![]()
目录
2.2.2.手动安装 Kubeflow Manifests 16
3.1.1.1.Kubeflow 用户界面(UI)概述 23
3.2.4.Jupyter TensorFlow 实例 37
3.3.1.Kubeflow Pipelines v1 Documentation 40
3.3.1.1.6.Kubeflow Pipelines UI 上的管道输入数据 44
3.3.1.2.1.1.部署 Kubeflow 并打开 Kubeflow Pipelines UI 48
3.3.1.3.2.3.集装箱化组件(Containerizing components) 62
3.3.1.3.5.运行和定期运行(Run and Recurring Run) 63
3.3.1.3.6.运行触发器(Run Trigger) 63
3.1.4.1.3.1.2.Kubeflow 独立管道 65
3.3.1.4.1.3.2.部署 Kubeflow 管道 73
3.3.1.4.1.3.3.升级 Kubeflow 管道 74
3.3.1.4.1.3.4.自定义 Kubeflow 管道 75
3.3.1.4.1.3.5.卸载 Kubeflow 管道 76
为 Docker Executor 准备 GKE 集群 78
3.3.1.5.1.2.Kubeflow Pipelines CLI 工具 82
3.3.1.5.1.5.安装 Kubeflow Pipelines SDK 83
3.3.1.5.1.6.将 Pipelines SDK 连接到 Kubeflow Pipelines 85
3.3.1.5.1.10.构建基于 Python 函数的组件 100
3.4.2.4.3.7.Parzen 估计树(TPE) 118
3.4.2.4.3.9.协方差矩阵自适应进化策略(CMA-ES) 119
3.4.2.4.3.10.Sobol 的 Quasirandom 序列 119
3.4.2.4.3.11.基于 ENAS 的神经结构搜索 120
3.4.2.4.3.12.可区分体系结构搜索(DARTS) 121
3.4.5.1.3.使用自定义 Kubernetes 资源作为试用模板 130
3.4.9.1.TensorFlow Training (TFJob) 138
3.4.9.1.2.安装 TensorFlow 运算符 141
验证 Kubeflow 部署中是否包含 TFJob 支持 141
3.4.9.1.8.tfReplicaStatus(tf 复制状态) 146
3.4.9.1.11.GKE 上的 Stackdriver 149
3.4.9.1.12.Troubleshooting 150
3.4.9.2.PaddlePaddle Training (PaddleJob) 151
验证 Kubeflow 部署中是否包含 PaddleJob 支持 151
3.4.9.3.PyTorch Training (PyTorchJob) 154
3.4.9.3.1.1.验证 Kubeflow 部署中是否包含 PyTorchJob 支持 154
3.4.9.4.MXNet Training (MXJob) 157
验证您的 Kubeflow 部署中是否包含 MXJob 支持 157
3.4.9.4.XGBoost 训练 (XGBoostJob) 162
3.4.9.4.2.验证 Kubeflow 部署中是否包含 XGBoost 支持 162
3.4.9.5.MPI Training (MPIJob) 165
3.4.9.6.2.关于火山调度程序和帮派调度(About volcano scheduler and gang-scheduling) 171
前提条件:授予用户最少的 Kubernetes 集群访问权限 176
3.4.10.3.9.通过 Kubeflow UI 管理贡献者 180
# 1.Kubeflow 简介
Kubeflow 项目致力于使机器学习(ML)工作流在 Kubernetes 上的部署变得简单、可移植和可扩展。我们的目标不是重新创建其他服务,而是提供一种直接的方式,将最佳的 ML 开源系统部署到不同的基础设施中。无论您在哪里运行 Kubernetes,都应该能够运行 Kuberlow。
# 1.1.Kubeflow 入门
阅读体系结构概述,了解 Kubeflow 的体系结构介绍,并了解如何使用 Kubeflow 管理 ML 工作流。
按照 Installing Kubeflow 设置环境并安装 Kubeflow。
观看以下视频,其中介绍了库贝洛。
# 1.2.Kubeflow 是什么?
Kubeflow 是 Kubernetes 的机器学习工具包。要使用 Kubeflow,基本工作流程是:
- 下载并运行 Kubeflow 部署二进制文件。
- 自定义生成的配置文件。
- 运行指定的脚本将容器部署到特定环境。
您可以调整配置以选择要用于 ML 工作流每个阶段的平台和服务:
- 数据准备
- 模型训练,
- 预测服务
- 服务管理
您可以选择在本地、本地或云环境中部署 Kubernetes 工作负载。
# 1.3.Kubeflow 的使命
我们的目标是通过让 Kubernetes 做它擅长的事情,尽可能简单地扩展机器学习(ML)模型并将其部署到生产环境中:
- 在不同的基础架构上进行简单、可重复、可移植的部署(例如,在笔记本电脑上进行实验,然后移动到本地集群或云)
- 部署和管理松散耦合的微服务
- 根据需求进行扩展
因为 ML 从业者使用了一组不同的工具,所以关键目标之一是根据用户需求(在合理范围内)定制堆栈,并让系统处理“无聊的东西”。虽然我们从一系列的技术开始,但我们正在与许多不同的项目合作,以包括更多的工具。
最终,我们希望有一组简单的清单,在 Kubernetes 已经运行的任何地方为您提供一个易于使用的 ML 堆栈,并且可以根据它部署到的集群进行自我配置。
# 2.架构
# 2.1.Kubeflow 架构概述
本指南介绍了 Kubeflow 作为开发和部署机器学习(ML)系统的平台。Kubeflow 是一个数据科学家的平台,他们希望构建和实验 ML 管道。Kubeflow 也适用于希望将 ML 系统部署到各种环境中进行开发、测试和生产级服务的 ML 工程师和运营团队。
# 2.1.1.概念性概述
Kubeflow 是 Kubernetes 的 ML 工具包。下图显示了 Kubeflow 作为一个平台,用于在 Kubernetes 上安排 ML 系统的组件:
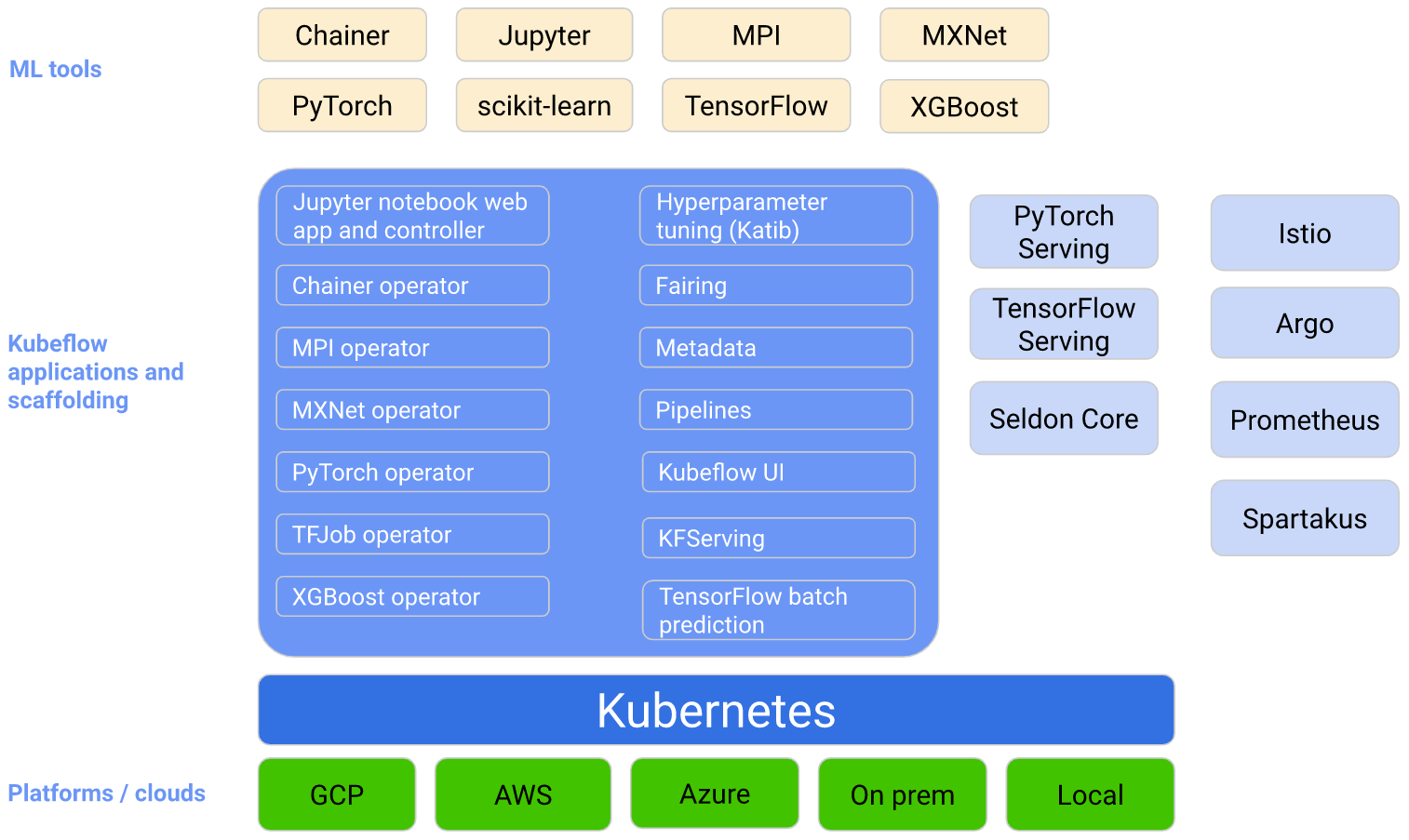
Kubeflow 基于 Kubernetes 构建,作为一个用于部署、扩展和管理复杂系统的系统。使用 Kubeflow 配置界面(见下文),您可以指定工作流所需的 ML 工具。然后,您可以将工作流部署到各种云、本地和本地平台,以供实验和生产使用。
# 2.1.2.介绍 ML 工作流
当您开发和部署 ML 系统时,ML 工作流通常由几个阶段组成。开发 ML 系统是一个迭代过程。您需要评估 ML 工作流各个阶段的输出,并在必要时对模型和参数进行更改,以确保模型始终产生所需的结果。
为了简单起见,下图按顺序显示了工作流阶段。工作流末尾的箭头指向流程,以指示流程的迭代性质:
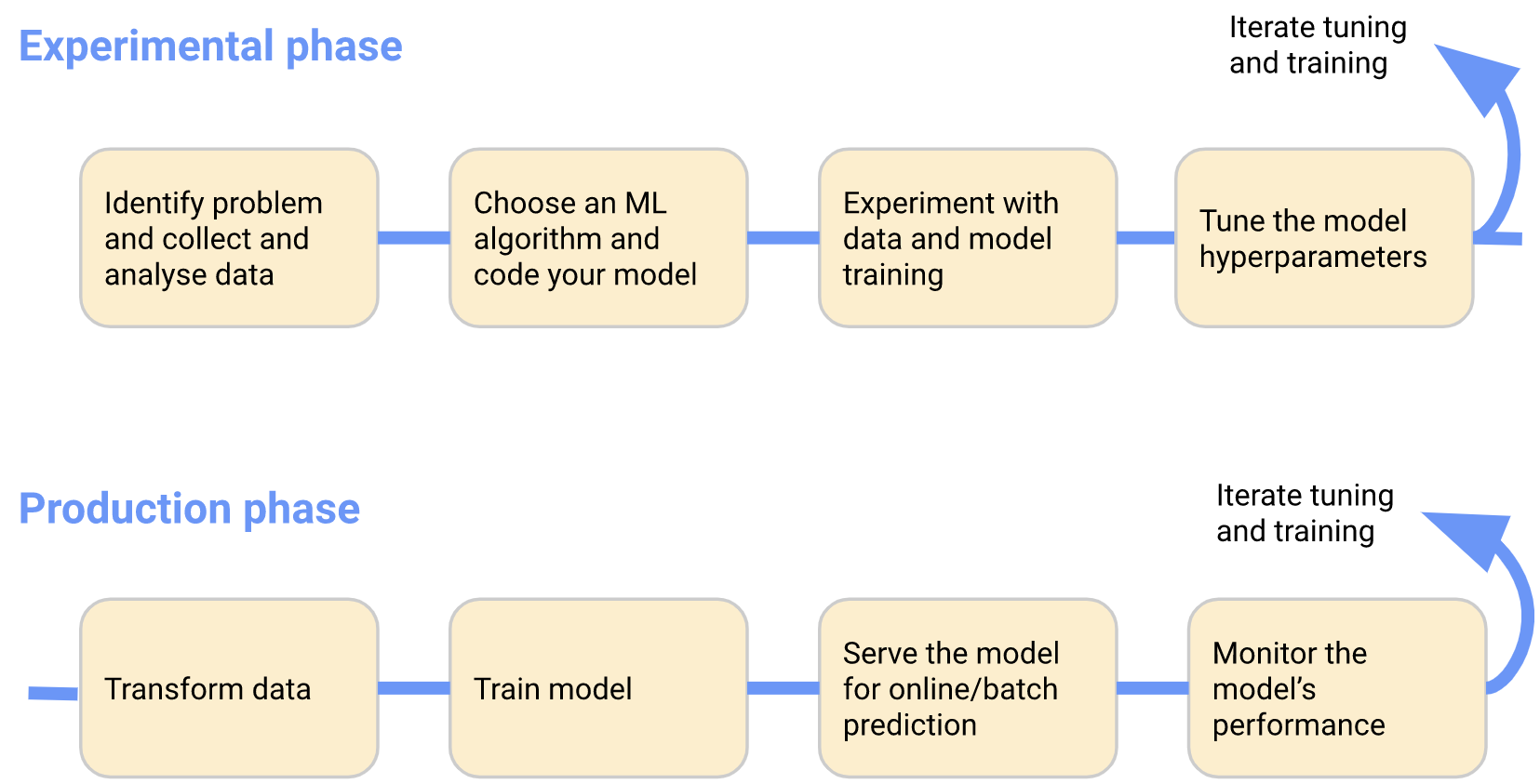
更详细地了解各阶段:
- 在实验阶段,您基于初始假设开发模型,并迭代测试和更新模型,以产生您想要的结果:
- 确定您希望 ML 系统解决的问题。
- 收集并分析训练 ML 模型所需的数据。
- 选择 ML 框架和算法,并对模型的初始版本进行编码。
- 实验数据和训练模型。
- 调整模型超参数以确保最有效的处理和最准确的结果。
- 在生产阶段,部署执行以下过程的系统:
- 将数据转换为训练系统所需的格式。为了确保模型在训练和预测过程中表现一致,转换过程在实验和生产阶段必须相同。
- 训练 ML 模型。
- 为在线预测或以批处理模式运行提供模型。
- 监控模型的性能,并将结果反馈到您的过程中,以调整或重新训练模型。
# 2.1.3.ML 工作流中的 Kubeflow 组件
下一个图表将 Kubeflow 添加到工作流中,显示了哪些 Kubeflow 组件在每个阶段都有用:
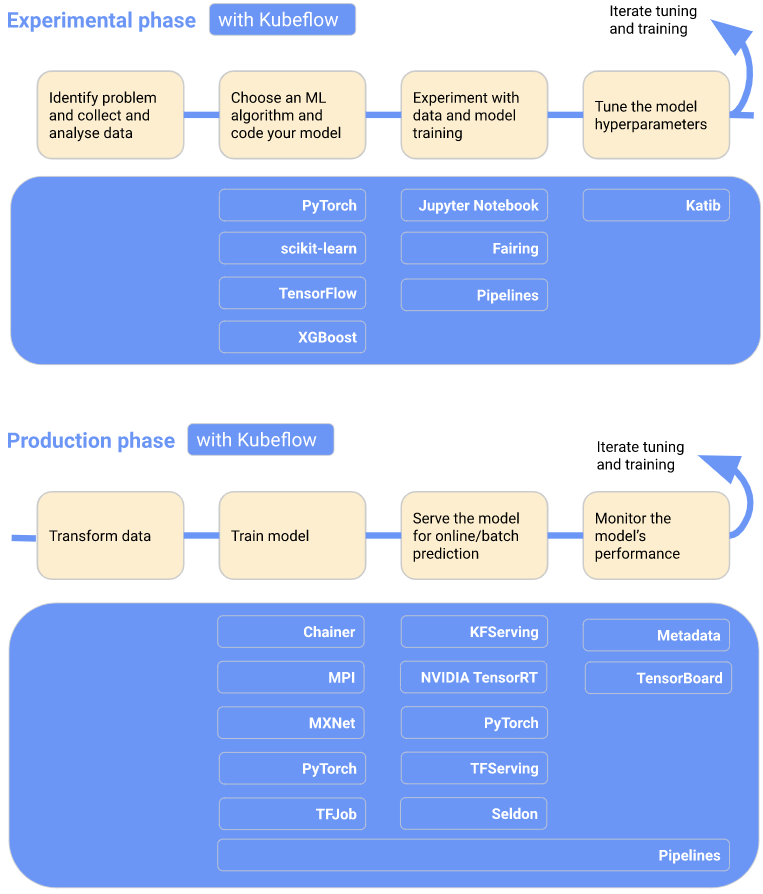
要了解更多信息,请阅读以下 Kubeflow 组件指南:
- Kubeflow 包括用于生成和管理 Jupyter 笔记本的服务。使用笔记本进行交互式数据科学和 ML 工作流实验。
- Kubeflow Pipelines 是一个基于 Docker 容器构建、部署和管理多步骤 ML 工作流的平台。
- Kubeflow 提供了几个组件,您可以使用这些组件来构建 ML 训练、超参数调优和跨多个平台服务工作负载。
# 2.1.4.特定 ML 工作流示例
下图显示了一个特定 ML 工作流的简单示例,您可以使用该工作流来训练和服务在 MNIST 数据集上训练的模型:
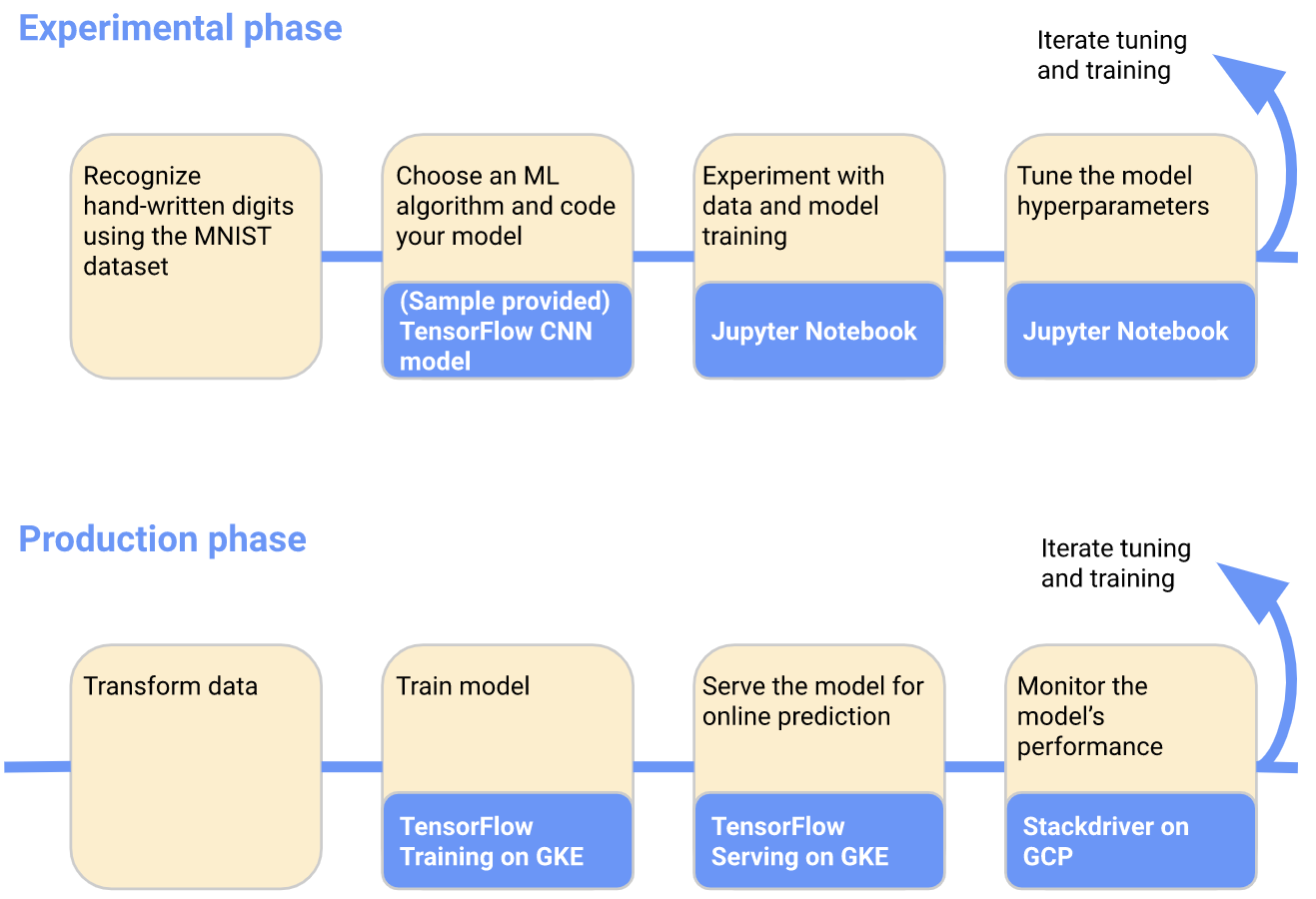
有关工作流的详细信息,以及如何自己运行系统,请参阅 GCP 上 Kubeflow 的端到端教程。
# 2.1.5.Kubeflow 接口
本节介绍可用于与 Kubeflow 交互以及在 Kubeflow 上构建和运行 ML 工作流的接口。
# 2.1.5.1.Kubeflow 用户界面(UI)
Kubeflow UI 如下所示:
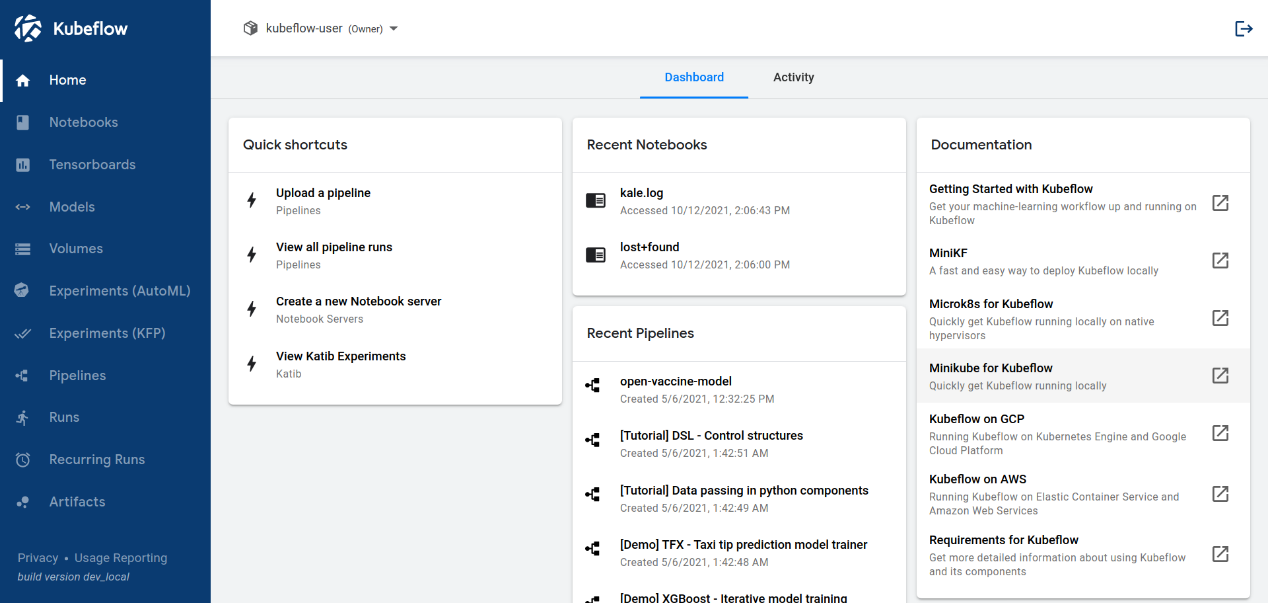
UI 提供了一个中央仪表板,您可以使用它访问 Kubeflow 部署的组件。阅读如何访问中央仪表板。
# 2.1.5.2.Kubeflow API 和 SDK
Kubeflow 的各种组件提供 API 和 Python SDK。请参阅以下参考文档集:
- Kubeflow Pipelines API 和 SDK 的 Pipelines 参考文档,包括 Kubeflow Pipelines 领域特定语言(DSL)。
- Kubeflow Fairing SDK 的 Fairing 参考文档。
# 2.2.安装 Kubeflow
Kubeflow 是 Kubernetes 的端到端机器学习(ML)平台,它为 ML 生命周期的每个阶段提供组件,从探索到训练和部署。操作员可以选择最适合其用户的组件,无需部署每个组件。要阅读更多有关 Kubeflow 组件和架构的信息,请参阅 Kubeflow 架构页面。
有两种途径可以与 Kubeflow 一起启动和运行,您可以选择:
- 使用打包分发
- 使用 manifests(高级)
# 2.2.1.安装打包的 Kubeflow 发行版
打包发行版由各自的维护人员开发和支持,Kubeflow 社区目前不认可或认证任何发行版。
| Name | Maintainer | Platform | Version | Docs | Website |
|---|---|---|---|---|---|
| Kubeflow on AWS | Amazon Web Services (AWS) | Amazon Elastic Kubernetes Service (EKS) | 1.6.1 | Docs (opens new window) | External Website (opens new window) |
| Kubeflow on Azure | Microsoft Azure | Azure Kubernetes Service (AKS) | 1.2 | Docs (opens new window) | |
| Kubeflow on Google Cloud | Google Cloud | Google Kubernetes Engine (GKE) | 1.6.1 | Docs (opens new window) | |
| Kubeflow on IBM Cloud | IBM Cloud | IBM Cloud Kubernetes Service (IKS) | 1.6 | Docs (opens new window) | External Website (opens new window) |
| Kubeflow on Nutanix | Nutanix | Nutanix Karbon | 1.6.0 | Docs (opens new window) | |
| Kubeflow on OpenShift | Red Hat | OpenShift | 1.6 | Docs (opens new window) | External Website (opens new window) |
| Argoflow | Argoflow Community | Conformant Kubernetes | 1.3 | N/A | External Website (opens new window) |
| Arrikto Kubeflow as a Service | Arrikto | Fully Managed | 1.5 | N/A | External Website (opens new window) |
| Arrikto Enterprise Kubeflow | Arrikto | EKS, AKS, GKE | 1.5 | Docs (opens new window) | External Website (opens new window) |
| Charmed Kubeflow | Canonical | Conformant Kubernetes | 1.6 | Docs (opens new window) | External Website (opens new window) |
| Kubeflow on Oracle Container Engine for Kubernetes | Oracle | Oracle Cloud Infrastructure (OCI) | 1.6 | N/A | External Website (opens new window) |
| Kubeflow on vSphere | VMware | vSphere | 1.6 | N/A | External Website (opens new window) |
# 2.2.2.手动安装 Kubeflow Manifests
此方法适用于高级用户。库贝洛社区不会支持特定环境问题。如果您需要支持,请考虑使用 Kubeflow 的打包发行版。
Manifests Working Group 负责汇总每个 Kubeflow 官方组成部分的权威 Manifests。虽然这些清单旨在作为打包发行版的基础,但高级用户可以选择按照这些说明直接安装它们。
# 2.2.2.1.Kubeflow Manifests
# 2.2.2.1.1.概述
该协议归宣言工作组所有。如果您是编写或编辑软件包的撰稿人,请参阅最佳实践。Kubeflow Manifests 存储库组织在三(3)个主目录下,其中包括用于安装的清单:
| Directory | Purpose |
|---|---|
| apps | Kubeflow 的官方组成部分,由各自的 Kubeflow 工作组维护 |
| common | 共同服务,由 Manifests 工作组维护 |
| contrib | 第三方贡献的应用程序,由外部维护,不属于 Kubeflow 工作组 |
发行版目录包含 Kubeflow 特定的、原有的发行版的清单,并将在 1.4 版本中逐步淘汰,因为未来的发行版将在各自的外部存储库中维护其清单。文档、hack 和测试目录也将逐步淘汰。从 Kubeflow1.3 开始,所有组件都应该只能使用 kustomize 进行部署。任何部署在清单之上的自动化工具都应该由分发所有者在外部维护。
# 2.2.2.1.2.Kubeflow 组件版本
该 repo 周期性地从其各自的上游 repo 中同步所有官方 Kubeflow 组件。下面的矩阵显示了我们为每个组件提供的 git 版本:
| Component | Local Manifests Path | Upstream Revision |
|---|---|---|
| Training Operator | apps/training-operator/upstream | v1.5.0 (opens new window) |
| Notebook Controller | apps/jupyter/notebook-controller/upstream | v1.6.0-rc.1 (opens new window) |
| Tensorboard Controller | apps/tensorboard/tensorboard-controller/upstream | v1.6.0-rc.1 (opens new window) |
| Central Dashboard | apps/centraldashboard/upstream | v1.6.0-rc.1 (opens new window) |
| Profiles + KFAM | apps/profiles/upstream | v1.6.0-rc.1 (opens new window) |
| PodDefaults Webhook | apps/admission-webhook/upstream | v1.6.0-rc.1 (opens new window) |
| Jupyter Web App | apps/jupyter/jupyter-web-app/upstream | v1.6.0-rc.1 (opens new window) |
| Tensorboards Web App | apps/tensorboard/tensorboards-web-app/upstream | v1.6.0-rc.1 (opens new window) |
| Volumes Web App | apps/volumes-web-app/upstream | v1.6.0-rc.1 (opens new window) |
| Katib | apps/katib/upstream | v0.14.0-rc.0 (opens new window) |
| KServe | contrib/kserve/kserve | release-0.8 (opens new window) |
| KServe Models Web App | contrib/kserve/models-web-app | v0.8.1 (opens new window) |
| Kubeflow Pipelines | apps/pipeline/upstream | 2.0.0-alpha.3 (opens new window) |
| Kubeflow Tekton Pipelines | apps/kfp-tekton/upstream | v1.2.1 (opens new window) |
以下也是 Kubeflow 不同项目中使用的通用组件版本的矩阵:
| Component | Local Manifests Path | Upstream Revision |
|---|---|---|
| Istio | common/istio-1-16 | 1.16.0 (opens new window) |
| Knative | common/knative | 0.22.1 (opens new window) |
| Cert Manager | common/cert-manager | 1.10.1 (opens new window) |
# 2.2.2.1.3.安装
从 Kubeflow1.3 开始,Manifests WG 提供了两个选项,用于安装 Kubeflow 官方组件和 kustomize 通用服务。其目的是帮助最终用户轻松安装,并帮助发行所有者从经过测试的出发点构建他们的有见解的发行版:
- app 和 common 下所有组件的单命令安装
- app 和 common 的多命令、单独组件安装
选项 1 的目标是方便最终用户部署。
选项 2 的目标是定制和选择单个组件的能力。
示例目录包含一个示例 kustomization,用于运行单个命令。
在这两个选项中,我们都使用默认电子邮件(user@example.com)和密码(12341234)。对于任何生产 Kubeflow 部署,您都应该按照相关章节更改默认密码。
# 2.2.2.1.4.先决条件
- 具有默认 StorageClass 的 Kubernetes(最高 1.21)
- ⚠️ Kubeflow 1.5.0 与 1.22 及更高版本不兼容。您可以在 Kubeflow/Kubeflow#6353 中跟踪 K8s 1.22 支持的剩余工作
- kustosize(版本 3.2.0)(下载链接)
- ⚠️ Kubeflow 1.5.0 与 kustomize 4.x 的最新版本不兼容。这是由于资源排序和打印顺序发生了变化。请参阅 kubernetes sigs/kustomize#3794 和 Kubeflow/manifest#1797。我们知道这并不理想,我们正在与上游的 kustomiize 团队合作,尽快为最新版本的 kustosize 添加支持。
kubectl apply 命令在第一次尝试时可能会失败。这是 Kubernetes 和 kubectl 工作方式固有的(例如,必须在 CRD 就绪后创建 CR)。解决方案是简单地重新运行命令,直到它成功。对于单行命令,我们包含了一个 bash-one 命令行来重试该命令。
# 2.2.2.1.5.使用单个命令安装
您可以使用以下命令安装所有 Kubeflow 官方组件(驻留在 app 下)和所有公共服务(驻留在 common 下):
while ! kustomize build example | kubectl apply -f -; do echo "Retrying to apply resources"; sleep 10; done
一旦一切安装成功,您就可以通过登录集群访问 Kubeflow Central Dashboard。祝贺现在,您可以开始使用 Kubeflow 测试和运行端到端 ML 工作流。
# 2.2.2.1.6.安装单个组件^1 (opens new window)
在本节中,我们将分别使用 kubectl 和 kustosize 安装每个 Kubeflow 官方组件(在 app 下)和每个公共服务(在 common 下)。
如果执行了以下所有命令,则结果与单命令安装的上述部分相同。本节的目的是:
- 提供每个组件的描述,并深入了解其安装方式。
- 允许用户或分发所有者仅选择所需的组件。
证书管理器
许多 Kubeflow 组件使用证书管理器为准入 webhook 提供证书。安装证书管理器:
Istio
许多 Kubeflow 组件使用 Istio 来保护其流量、强制网络授权和实现路由策略。安装 Istio:
Dex
Dex 是一个具有多个身份验证后端的 OpenID Connect Identity(OIDC)。在这个默认安装中,它包括一个带有电子邮件的静态用户user@example.com.默认情况下,用户的密码为 12341234。对于任何生产 Kubeflow 部署,您都应该按照相关章节更改默认密码。用如下命令安装 Dex:
OIDC 身份验证服务
OIDC AuthService 扩展了您的 Istio Ingress 网关功能,能够作为 OIDC 客户端运行:
Knative
Knative 由 KServe 官方 Kubeflow 组件使用。安装 Knative Serving:
或者,您可以安装可用于推理请求日志记录的 Knative Eventing:
Kubeflow Namespace
创建 Kubeflow 组件所在的命名空间。此命名空间名为 Kubeflow。安装 Kubeflow 命名空间:
Kubeflow Roles
创建 Kubeflow ClusterRoles、Kubeflow 视图、Kubeflowedit 和 Kubeflowadmin。Kubeflow 组件聚合对这些 ClusterRoles 的权限。安装 Kubeflow 角色:
Kubeflow Istio 资源
创建 Kubeflow 所需的 Istio 资源。这个 kustomization 当前在名称空间 Kubeflow 中创建了一个名为 Kubeflow Gateway 的 Istio 网关。如果你想用自己的 Istio 安装,那么你也需要这个 kustomization。安装 istio 资源:
# 2.3.获得支持
从何处获得 Kubeflow 的支持,本页介绍了当您遇到问题、有问题或想对 Kubeflow 提出建议时,可以探索的 Kubeflow 资源和支持选项。
# 2.3.1.应用程序状态
从 Kubeflow v1.0 发布开始,Kubeflow 社区将稳定状态归因于那些满足定义的稳定性、可支持性和可升级性级别的应用程序和组件。
当您将 Kubeflow 部署到 Kubernetes 集群时,您的部署包括许多应用程序。应用程序版本控制独立于 Kubeflow 版本控制。当应用程序在稳定性、可升级性和提供服务(如日志记录和监视)方面满足某些标准时,应用程序将移至 1.0 版。
当应用程序迁移到 1.0 版本时,Kubeflow 社区将决定是否在 Kubeflow 的下一个主要或次要版本中将该应用程序版本标记为稳定版本。
Kubeflow 的应用程序状态指示器:
- 稳定意味着应用程序符合达到应用程序版本 1.0 的标准,并且 Kubeflow 社区认为该应用程序对于 Kubeflow 的这个版本是稳定的。
- Beta 意味着应用程序正在朝着 1.0 版本的版本发展,其维护人员已经传达了满足稳定状态标准的时间表。Alpha 表示应用程序处于开发和/或集成到 Kubeflow 的早期阶段。
# 2.3.2.支持级别
下表描述了根据应用程序的状态可以预期的支持级别:
| Application status | Level of support |
|---|---|
| Stable | Kubeflow 社区为稳定的应用程序提供了最佳支持。请参阅下面关于社区支持的部分,了解尽力支持的定义以及您可以报告和讨论问题的社区渠道。您还可以考虑向 Kubeflow 社区提供商或云提供商请求支持。 |
| Beta | Kubeflow 社区为测试版应用程序提供了最佳支持。请参阅下面关于社区支持的部分,了解尽力支持的定义以及您可以报告和讨论问题的社区渠道。 |
| Alpha | 每个应用程序的 alpha 状态响应不同,这取决于该应用程序的社区规模和当前应用程序的活跃开发级别。 |
# 2.3.3.Kubeflow 社区的支持
Kubeflow 拥有一个活跃而乐于助人的用户和贡献者社区。Kubeflow 社区为稳定和测试版应用程序提供了尽最大努力的支持。尽力支持意味着没有解决问题的正式协议或承诺,但社区意识到尽快解决问题的重要性。如果以下所有情况属实,社区承诺帮助您诊断和解决问题:
- 原因属于 Kubeflow 控制的技术框架。例如,如果问题是由组织内的特定网络配置引起的,Kubeflow 社区可能无法提供帮助。
- 社区成员可以重现问题。
- 问题的报告者可以帮助进一步诊断和排除故障。
您可以在以下地方提出问题和建议:
- 轻松进行在线聊天和消息传递。查看 Kubeflow 的 Slack 工作区和频道的详细信息。
- Kubeflow 讨论基于电子邮件的小组讨论。加入 kubef low 讨论小组。
- Kubeflow 文档提供概述和操作指南。在排除问题时,请特别参考以下文档:
- Kubeflow 安装和设置
- Kubeflow 组件
- 进一步设置和故障排除
- Kubeflow 发布已知问题、问题和功能请求的跟踪器。搜索打开的问题,看看是否有其他人已经记录了您遇到的问题,并了解迄今为止的任何解决方法。如果没有人记录您的问题,请创建一个新问题来描述问题。
每个 Kubeflow 应用程序在 GitHub 上的 Kubeflow 组织中都有自己的问题跟踪程序。要开始,以下是主要的问题跟踪程序:
- Kubeflow core^2 (opens new window)
- kfctl 命令行工具^3 (opens new window)
- Kustomize manifests^4 (opens new window)
- Kubeflow 管道^5 (opens new window)
- Katib AutoML
- 元数据
- Fairing 笔记本 SDK
- Kubeflow 训练(TFJob、PyTorchJob、MXJob、XGBoostJob)
- KF 服务
- 示例
- 文档
# 2.3.4.Kubeflow 生态系统供应商的支持
以下组织为 Kubeflow 部署提供建议和支持:
# 2.3.5.来自云或平台提供商的支持
如果您使用云提供商的服务来托管 Kubeflow,云提供商可能能够帮助您诊断和解决问题。
请参阅您正在使用的云服务或平台的支持页面:
- 亚马逊 Web 服务(AWS)
- 标准 Ubuntu
- 谷歌云平台(GCP)
- IBM 云
- Microsoft Azure
- 红帽 OpenShift
# 2.3.6.其他提问地点
您还可以尝试在堆栈溢出上搜索答案或提问。查看标有“Kubeflow”的问题。
# 2.3.7.参与 Kubeflow 社区
你可以通过多种方式参与库贝洛。例如,您可以为 Kubeflow 代码或文档提供帮助。您可以参加社区会议,与维护人员讨论特定主题。有关更多信息,请参见 Kubeflow 社区页面。
# 2.3.8.关注新闻
关注库贝洛新闻:
- Kubeflow 博客是发布新版本、事件和技术演练的主要渠道。
- 请在 Twitter 上关注 Kubeflow 以获取共享的技术提示。
- 发行说明详细介绍了每个 Kubeflow 应用程序的最新更新。
- 每个 Kubeflow 应用程序在 GitHub 上的 Kubeflow 组织中都有自己的存储库。一些应用程序发布发行说明。要开始,以下是主要应用程序的发行说明:
- Kubeflow Core
- Kubeflow 管道
- Katib AutoML
- 元数据
- Fairing 笔记本 SDK
- 库贝洛训练操作员
- KF 服务
# 2.3.9.示例
使用 Kubeflow 演示机器学习的示例
警告
Kubeflow/examples 存储库中的一些示例尚未使用更新版本的 Kubeflow 进行测试。请参阅所选示例的自述文件。
MNIST 图像分类
使用 MNIST 数据集训练和服务图像分类模型。本教程采用在 Kubeflow 集群中运行的 Jupyter 笔记本的形式。您可以选择在各种云上部署 Kubeflow 并训练模型,包括 Amazon Web Services(AWS)、Google Cloud Platform(GCP)、IBM Cloud、Microsoft Azure 和内部部署。使用 TensorFlow Serving 为模型提供服务。
财务时间序列
在谷歌云平台(GCP)上使用 TensorFlow 训练和服务金融时间序列分析模型。使用 Kubeflow Pipelines SDK 自动化工作流。
# 3.部件
# 3.1.中央仪表板
# 3.1.1.中央仪表板
# 3.1.1.1.Kubeflow 用户界面(UI)概述
Kubeflow 组件状态稳定。请参阅 Kubeflow 版本控制策略。Kubeflow 部署包括一个中央仪表板,可快速访问部署在集群中的 Kubeflow 组件。仪表板包括以下功能:
特定操作的快捷方式,最近的管道和笔记本列表,以及度量,在一个视图中提供您的作业和集群概览。
集群中运行的组件的 UI 的外壳,包括 Pipelines、Katib、Notebook 等。
一个注册流,提示新用户在必要时设置其命名空间。
# 3.1.1.2.Kubeflow UI 概述
Kubeflow UI 包括以下内容:
- 主页:主页,访问最新资源、活动实验和有用文档的中心。
- 笔记本服务器:管理笔记本服务器。
- TensorBoard:管理 TensorBoard 服务器。
- 模型:管理部署的 KFServing 模型。
- 卷:管理群集的卷。
- 实验(AutoML):管理 Katib 实验。
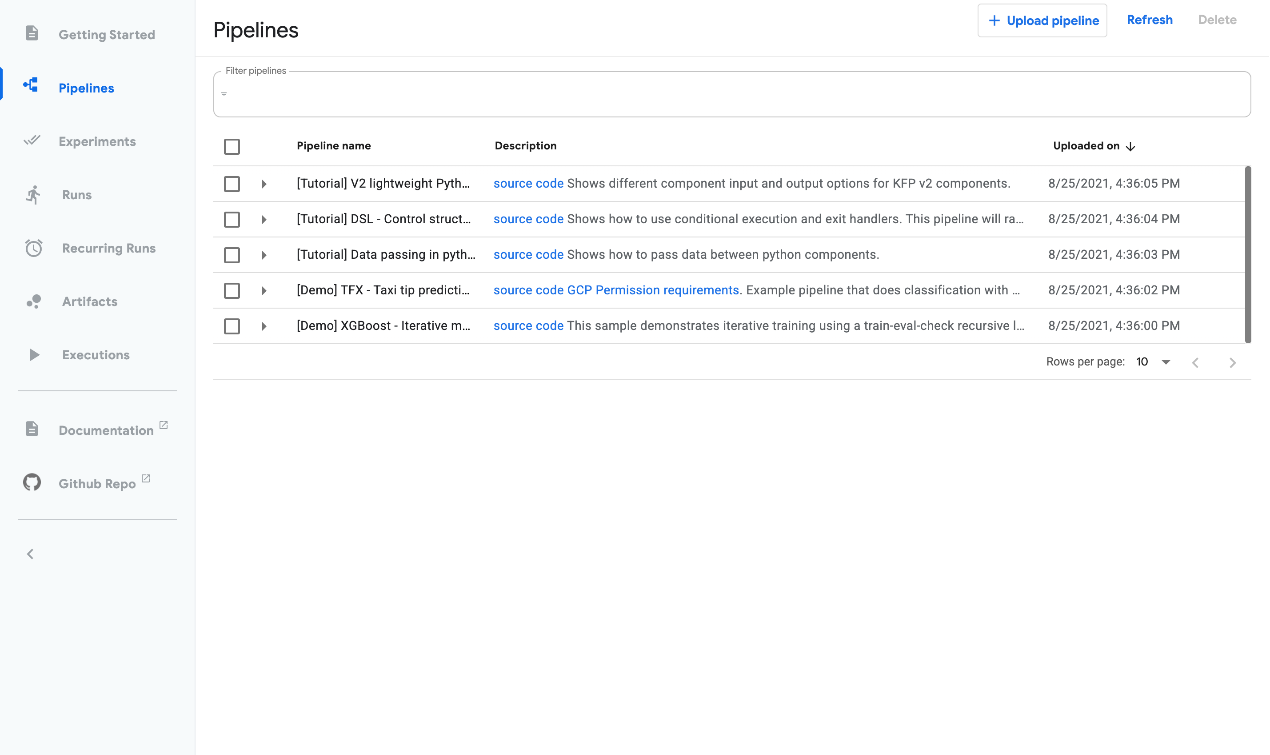
- 实验(KFP):管理 Kubeflow Pipelines(KFP)实验。
- 管道:管理 KFP 管道。
- 运行:管理 KFP 运行。
- 定期运行:管理 KFP 定期运行。
- 工件:跟踪 ML 元数据(MLMD)工件。
- 执行:跟踪 MLMD 中的各种组件执行。
- 管理贡献者:在 Kubeflow 部署中配置跨命名空间的用户访问共享。
中央仪表板如下所示:
# 3.1.1.3.访问中央仪表板
要访问中央仪表板,您需要连接到 Istio 网关,该网关提供对 Kubeflow 服务网格的访问。
如何访问 Istio 网关取决于您如何配置它。
# 3.1.1.4.谷歌云平台(GCP)的 URL 模式
如果您按照指南在 GCP 上部署 Kubeflow,则可以通过以下模式的 URL 访问 Kubeflow 中央 UI:
# 3.1.1.5.URL 将显示上面所示的仪表板
如果您使用云身份感知代理(IAP)部署 Kubeflow,Kubeflow 将使用 Let's Encrypt 服务为 Kubeflow UI 提供 SSL 证书。有关证书问题的疑难解答,请参阅监控云 IAP 设置的指南。
# 3.1.1.6.使用 kubectl 和端口转发
如果您没有将 Kubeflow 配置为与身份提供者集成,那么您可以直接转发到 Istio 网关。
如果以下任一项为真,则端口转发通常不起作用:
- 您已经使用 CLI 部署的默认设置在 GCP 上部署了 Kubeflow。
- 您已将 Istio 入口配置为仅接受特定域或 IP 地址上的 HTTPS 流量。
- 您已经将 Istio 入口配置为执行授权检查(例如,使用 CloudIAP 或 Dex)。
您可以通过 kubectl 和端口转发访问 Kubeflow,如下所示:
- 如果尚未安装 kubectl,请安装:
- 如果您在 GCP 上使用 Kubeflow,请在命令行上运行以下命令:gcloud components install kubectl。
- 或者,遵循 kubectl 安装指南。
- 使用以下命令设置到 Istio 网关的端口转发。
- 在以下位置访问中央导航仪表板:
根据您配置 Kubeflow 的方式,并非所有 UI 都在端口转发到反向代理之后工作。对于某些 web 应用程序,您需要配置应用程序服务的基本 URL。
# 3.1.2.自定义菜单项
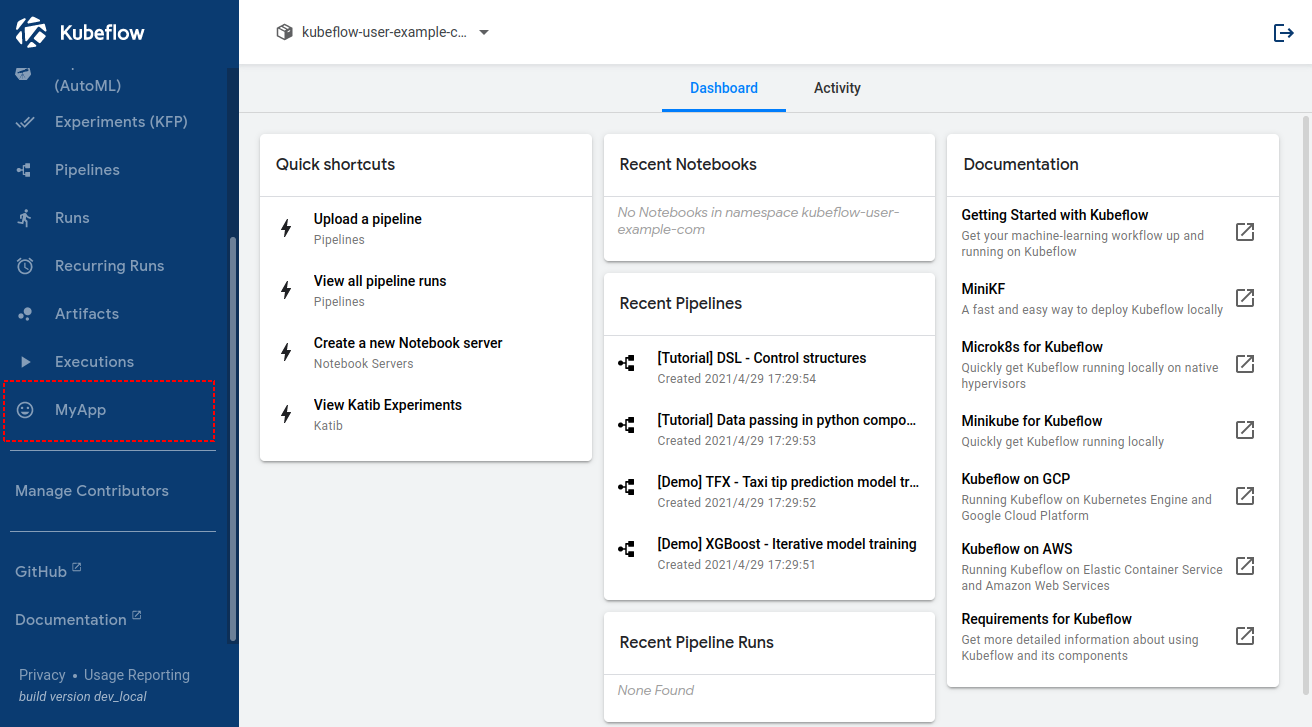
自定义菜单项以集成第三方应用程序。集群管理员可以将第三方应用程序与 Kubeflow 集成。在下面的示例中,“My App”被添加到侧菜单栏上。
# 3.1.2.1.添加共享项目
本节介绍了添加所有用户共享的项目的方法。首先,集群管理员应该将应用程序部署为 Kubernetes 中的微服务。应用程序的流量应设置为 Istio 的 VirtualService。
使用特定前缀进行部署并通过它控制流量是一种即时的方法。在这种情况下,可以从以下 URL 访问新应用程序。
接下来,菜单栏的配置可以如下打开。
您将看到当前设置。请根据需要添加新项目。
“图标”可以从铁图标^6 (opens new window)中选择。你可以在这个图标演示中看到铁图标列表。配置的变化很快就会反映出来。如果没有,请展开 centraldashboard 并重新加载 web 浏览器。
您将在菜单栏上看到一个新项目(在本例中为 MyApp)。通过单击该按钮,您可以跳转到 http://gateway/\_\_/myapp/并通过 (opens new window) Kubeflow 仪表板访问第三方应用程序。
# 3.1.2.2.添加名称空间项目
本节介绍了分割其他应用资源的方法。尽管 Kubeflow 具有多租户功能,但一些第三方应用程序无法与 Kubeflow 配置文件交互,或者不支持多租户。处理此问题的通用方法是为每个命名空间部署应用程序。集群管理员为每个命名空间和 URL 部署应用程序如下所示。
在这种情况下,您可以如下配置中央仪表板。当用户打开仪表板时,{ns}应替换为命名空间。
用户可以在菜单栏上看到一个新项目(在本例中,也是 MyApp)。它们可以根据名称空间选择跳到 http://gateway/\__/myapp/profile1/或 (opens new window) http://gateway/_/myapp/profile (opens new window) 2/。iframe 的实际内部内容由命名空间切换。
如果启用了 sidecar 注入,则对应用程序的授权由 istio 完成。e、 g)不属于 profile2 的用户无法访问http://gateway/__/myapp/profile2/ (opens new window)。
# 3.1.2.3.注册流程
在 Kubeflow 中设置命名空间。本指南适用于首次登录 Kubeflow 的 Kubeflow 用户。用户可以是部署 Kubeflow 的人,也可以是具有访问 Kubeflow 集群和使用 Kubeflow 权限的其他人。
# 3.1.2.4.命名空间简介
根据 Kubeflow 集群的设置,您可能需要在首次登录 Kubeflow 时创建一个命名空间。命名空间有时被称为概要文件或工作组。
Kubeflow 在以下情况下提示您创建命名空间:
- 对于支持多用户隔离的 Kubeflow 部署:您的用户名还没有与角色绑定相关联的命名空间,这些角色绑定为您提供了对命名空间的管理(所有者)访问权限。
- 对于支持单用户隔离的 Kubeflow 部署:Kubeflow 集群没有命名空间角色绑定。
如果 Kubeflow 没有提示您创建名称空间,那么 Kubeflow 管理员可能已经为您创建了名称空间。您应该能够看到 Kubeflow 中央仪表板并开始使用 Kubeflow。
# 3.1.2.5.先决条件
Kubeflow 管理员必须执行以下步骤:
- 按照 Kubeflow 入门指南,将 Kubeflow 部署到 Kubernetes 集群。
- 让您访问 Kubernetes 集群。请参阅多租户指南。
# 3.1.2.6.创建命名空间
如果您还没有与用户名关联的合适名称空间,Kubeflow 将在您首次登录时显示以下屏幕:

单击开始设置并按照屏幕上的说明设置命名空间。命名空间的默认名称是用户名。创建名称空间后,您应该看到 Kubeflow 中央仪表板,屏幕顶部的下拉列表中显示了您的名称空间:
# 3.1.3.注册一个流程
本指南适用于首次登录 Kubeflow 的 Kubeflow 用户。用户可以是部署 Kubeflow 的人,也可以是具有访问 Kubeflow 集群和使用 Kubeflow 权限的其他人。
# 3.1.3.1.命名空间简介
根据 Kubeflow 集群的设置,您可能需要在首次登录 Kubeflow 时创建一个命名空间。命名空间有时被称为概要文件或工作组。
Kubeflow 在以下情况下提示您创建命名空间:
- 对于支持多用户隔离的 Kubeflow 部署:您的用户名还没有与角色绑定相关联的命名空间,这些角色绑定为您提供了对命名空间的管理(所有者)访问权限。
- 对于支持单用户隔离的 Kubeflow 部署:Kubeflow 集群没有命名空间角色绑定。
如果 Kubeflow 没有提示您创建名称空间,那么 Kubeflow 管理员可能已经为您创建了名称空间。您应该能够看到 Kubeflow 中央仪表板并开始使用 Kubeflow。
# 3.1.3.2.先决条件
Kubeflow 管理员必须执行以下步骤:
- 按照 Kubeflow 入门指南^7 (opens new window),将 Kubeflow 部署到 Kubernetes 集群。
- 让您访问 Kubernetes 集群^8 (opens new window)。请参阅多租户指南。
# 3.1.3.3.创建命名空间
如果您还没有与用户名关联的合适名称空间,Kubeflow 将在您首次登录时显示以下屏幕:

单击开始设置并按照屏幕上的说明设置命名空间。命名空间的默认名称是用户名。
创建名称空间后,您应该看到 Kubeflow 中央仪表板,屏幕顶部的下拉列表中显示了您的名称空间:
# 3.2.Kubeflow Notebooks
# 3.2.1.概述
# 3.2.1.1.什么是 Kubeflow 笔记本?
Kubeflow Notebook 提供了一种在 Kubernetes 集群中运行基于 web 的开发环境的方法,方法是在 Pods 中运行它们。
一些关键功能包括:
- 本机支持 Jupyter Lab、RStudio 和 Visual Studio Code(代码服务器)。
- 用户可以直接在集群中创建笔记本容器,而不是在工作站上本地创建。
- 管理员可以为他们的组织提供标准笔记本图像,并预先安装所需的软件包。
- 访问控制由 Kubeflow 的 RBAC 管理,使整个组织更容易共享笔记本
# 3.2.2.快速入门指南
# 3.2.2.1.总结
- 按照《入门-安装 Kubeflow》安装 Kubeflow。
- 在浏览器中打开 Kubeflow Central Dashboard。
- 单击左侧面板中的“记事本”。
- 单击“新建服务器”以创建新的笔记本服务器。
- 指定笔记本服务器的配置。
- 配置笔记本后,单击“连接”
# 3.2.2.2.详细步骤
- 在浏览器中打开 Kubeflow Central Dashboard。
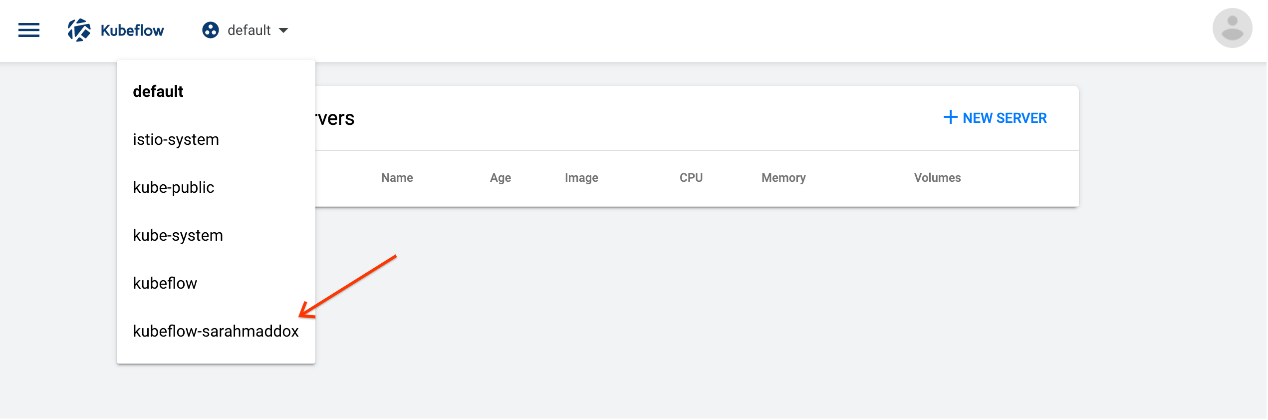
- 选择命名空间:
- 单击名称空间下拉列表以查看可用名称空间的列表。
- 选择与 Kubeflow Profile 对应的命名空间。(有关配置文件的更多信息,请参阅多用户隔离页面。)
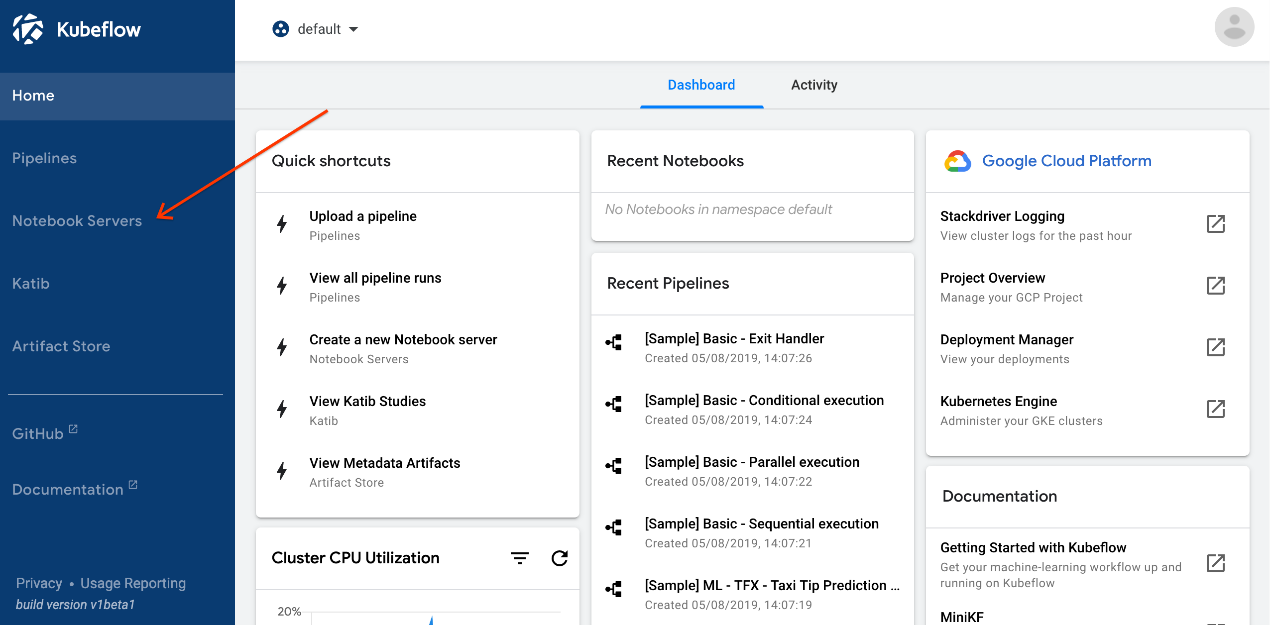
- 单击左侧面板中的“笔记本服务器”:
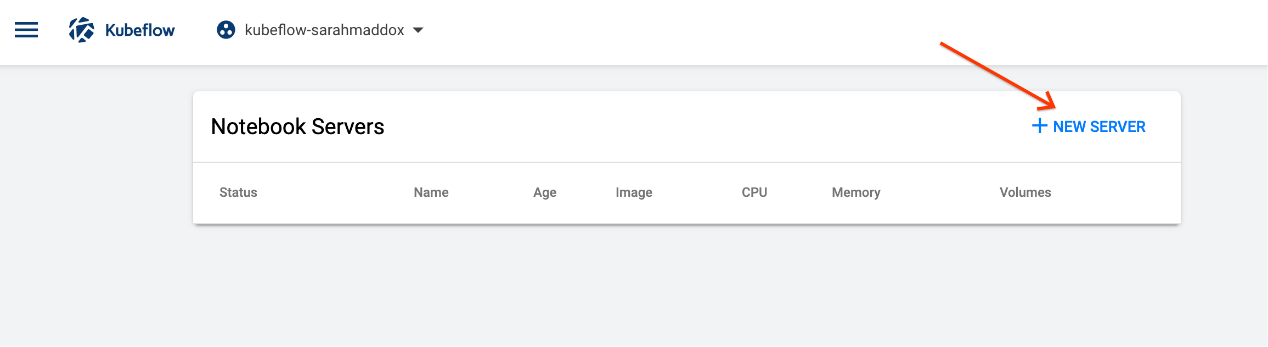
- 单击“笔记本服务器 Notebook Servers””页面上的“新建服务器 New Server””:
- 输入笔记本服务器的“名称 Name”。名称可以包含字母和数字,但不能包含空格。例如,my-first-notebook。
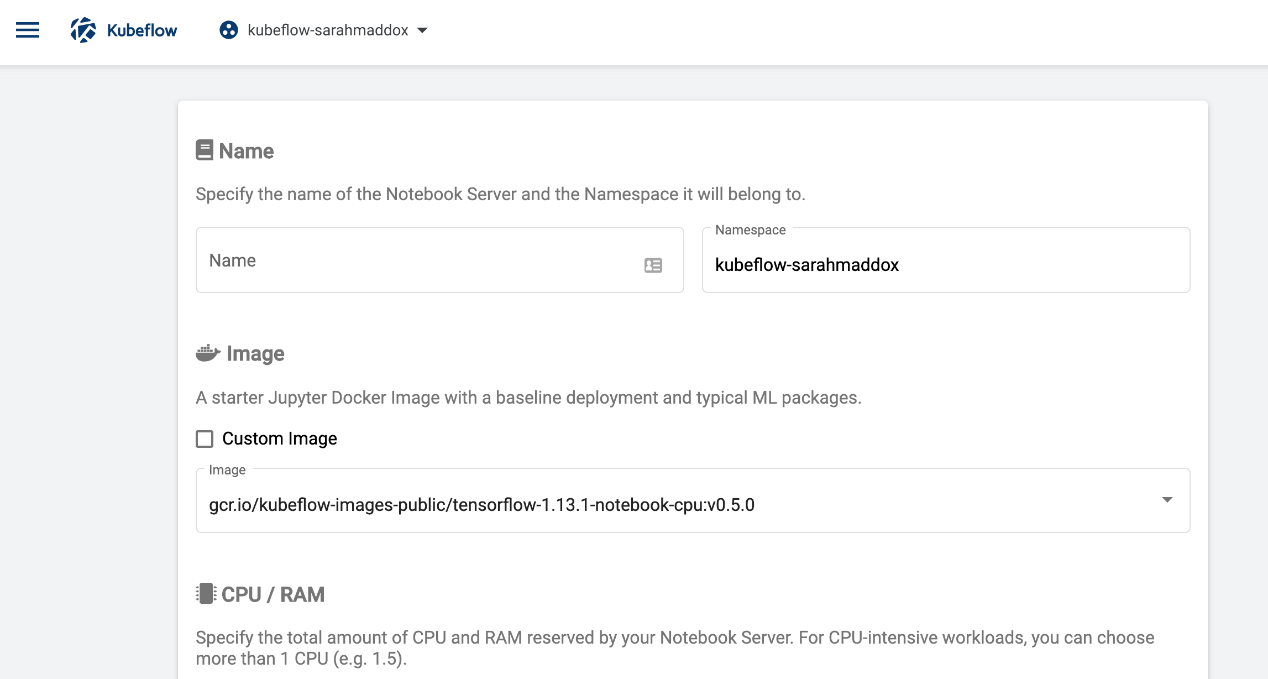
- 为笔记本服务器选择 Docker“图像”
- 自定义图像:如果选择自定义选项,则必须在表单 registry/image:tag 中指定 Docker 图像。(请参阅容器图像指南^9 (opens new window)。)
- 标准图像:单击“图像”下拉菜单以查看可用图像列表。(您可以从 Kubeflow 管理员配置的列表中选择)
- 指定笔记本服务器将请求的“CPU”数量。
- 指定笔记本服务器将请求的“RAM”数量。
- 指定要作为 PVC 卷安装在主文件夹中的“工作区卷”。
- (可选)指定一个或多个要安装为 PVC 卷的“数据卷”。
- (可选)指定一个或多个其他“配置”
- 这些资源对应于概要文件命名空间中的 PodDefault 资源^10 (opens new window)。
- Kubeflow 将“配置”字段中的标签与 PodDefault 清单中指定的属性进行匹配。
- 例如,在“配置”字段中选择标签 add gcp secret,以匹配包含以下配置的 PodDefault 清单:
- (可选)指定笔记本服务器将请求的任何“GPUs”。Kubeflow 在 Pod 请求中使用“limits”将 GPU 配置到笔记本 Pod 上(有关调度 GPU 的详细信息,请参阅 Kubernetes^11 (opens new window)文档)
- (可选)指定“启用共享内存enable shared memory”的设置。
- 一些库(如 PyTorch)使用共享内存进行多处理。
- 目前,Kubernetes 中没有激活共享内存的实现。
- 作为一种解决方法,Kubeflow 在/dev/shm 上装载一个空目录卷。
- 单击“启动LAUNCH”以创建具有指定设置的新笔记本 CRD。
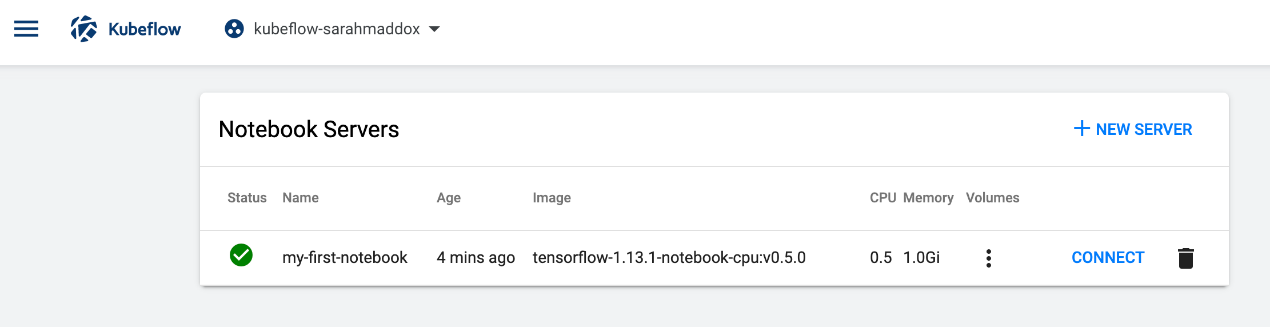
- 您应该在“笔记本服务器”页面上看到新笔记本服务器Notebook Servers的条目
- “状态Status”栏中应有一个旋转指示器。
- kubernetes 可能需要几分钟的时间来配置笔记本服务器 pod。
- 您可以通过将鼠标光标悬停在“状态”列中的图标上来检查 Pod 的状态Status。
- 单击“连接CONNECT”以查看笔记本服务器显示的 web 界面。
# 3.2.3.容器图像
Kubeflow Notebook 本机支持三种类型的笔记本,JupyterLab、RStudio 和 Visual Studio Code(代码服务器),但任何基于 web 的 IDE 都应该可以工作。笔记本服务器作为 Kubernetes Pod 中的容器运行,这意味着 IDE 的类型(以及安装的软件包)取决于您为服务器选择的 Docker 映像。
# 3.2.3.1.图像
我们提供了许多示例容器图像来帮助您开始。
# 3.2.3.2.基本图像
这些图像为 Kubeflow Notebook 容器提供了一个共同的起点。查看自定义图像,了解如何使用自己的软件包扩展它们。
# 3.2.3.3.完整图像
这些图像使用数据科学家和 ML 工程师使用的通用包扩展了基础图像。
# 3.2.3.4.图像相关性图表
此流程图显示了我们的笔记本容器图像如何相互依赖。
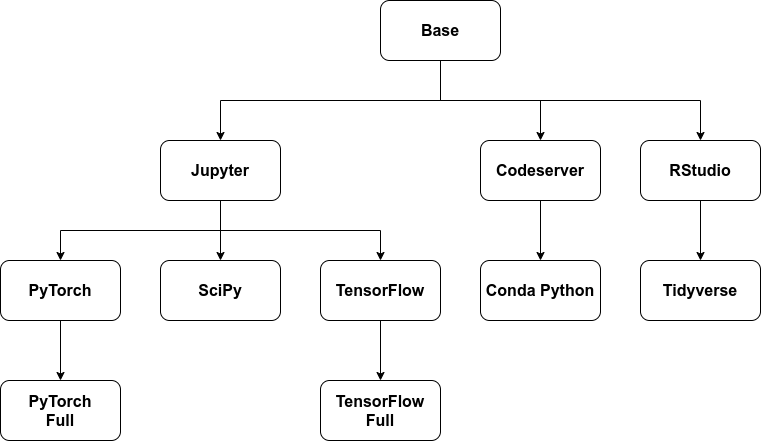
# 3.2.3.5.自定义图像
用户在生成 Kubeflow Notebook 后安装的软件包只会在 pod 的生命周期内使用(除非安装到 PVC 支持的目录中)。
为了确保在 Pod 重启过程中保留软件包,用户需要:
- 生成包含它们的自定义图像,或
- 确保它们安装在 PVC 支持的目录中
图像要求
要使 Kubeflow Notebook 使用容器图像,图像必须:
- 在端口 8888 上公开 HTTP 接口:
- Kubeflow 在运行时使用我们希望容器侦听的 URL 路径设置环境变量 NB_PREFIX
- Kubeflow 使用 IFrames,因此确保您的应用程序在 HTTP 响应头中设置 Access-Control-Allow-Origin:*
- 作为名为 jovyan 的用户运行:
- jovyan 的主目录应为/home/jovyan
- jovyan 的 UID 应该是 1000
- 成功启动安装在/home/jovyan 的空 PVC:
- Kubeflow 在/home/jovyan 安装了一个 PVC,以在 Pod 重启期间保持状态
# 3.2.4.Jupyter TensorFlow 实例
# 3.2.4.1.Mnist 示例
(改编自 tensorflow/tensorflow-mnist_softmax.py)创建笔记本服务器时,选择安装了 Jupyter 和 TensorFlow 的容器映像。使用 Jupyter 的界面创建一个新的 Python3 笔记本。
复制以下代码并将其粘贴到笔记本中:
- 运行代码。您应该会看到 TensorFlow 发出的大量警告消息,后面有一行显示训练精度,如下所示:
# 3.2.5.提交 Kubernetes 资源
从笔记本提交 Kubernetes 资源
# 3.2.5.1.笔记本 Pod 服务帐户
Kubeflow 将 default-editor Kubernetes Service Account 分配给 Notebook Pods。Kubernetes 默认编辑器 Service Account 绑定到 Kubeflow edit-Cluster Role,该角色对许多 Kubernete 资源具有命名空间范围的权限。
您可以使用以下方法获取 Cluster Role/Kubeflow 编辑的 RBAC 的完整列表:
# 3.2.5.2.笔记本 Pod 中的 Kuectl
因为每个 Notebook Pod 都绑定了高度特权的默认编辑器 Kubernetes Service Account,所以您可以在其中运行 kubectl,而无需提供额外的身份验证。
例如,以下命令将创建 test.yaml 中定义的资源:
# 3.2.6.故障排除
Kubeflow Notebook 常见问题及解决方案
# 3.2.6.1.问题:笔记本未启动
解决方案:检查笔记本的事件
运行以下命令,然后检查事件部分以确保没有错误:
kubectl describe notebooks "${MY_NOTEBOOK_NAME}" --namespace "${MY_PROFILE_NAMESPACE}"
解决方案:检查 Pod 的事件
运行以下命令,然后检查事件部分以确保没有错误:
kubectl describe pod "${MY_NOTEBOOK_NAME}-0" --namespace "${MY_PROFILE_NAMESPACE}"
解决方案:检查吊舱的 YAML
运行以下命令并检查 Pod YAML 的外观是否符合预期:
kubectl get pod "${MY_NOTEBOOK_NAME}-0" --namespace "${MY_PROFILE_NAMESPACE}" -o yaml
解决方案:检查 Pod 的日志
运行以下命令从 Pod 获取日志:
kubectl logs "${MY_NOTEBOOK_NAME}-0" --namespace "${MY_PROFILE_NAMESPACE}"
# 3.2.6.2.问题:手动删除笔记本
解决方案:使用 kubectl 删除笔记本资源
运行以下命令手动删除笔记本资源:
kubectl delete notebook "${MY_NOTEBOOK_NAME}" --namespace "${MY_PROFILE_NAMESPACE}"
# 3.2.7.API Reference
# Notebook (v1)
# 3.3.Kubeflow Pipelines
# 3.3.1.Kubeflow Pipelines v1 Documentation
# 3.3.1.1.引言
Kubeflow Pipelines 是一个基于 Docker 容器构建和部署可移植、可扩展的机器学习(ML)工作流的平台。
# 3.3.1.1.1.快速启动
按照管道快速启动指南运行第一个管道。
# 3.3.1.1.2.什么是 Kubeflow 管道?
Kubeflow 管道平台包括:
- 用于管理和跟踪实验、作业和运行的用户界面(UI)。
- 用于调度多步骤 ML 工作流的引擎。
- 用于定义和操作管道和组件的 SDK。
- 使用 SDK 与系统交互的笔记本。
Kubeflow 管道的目标如下:
- 端到端编排:启用和简化机器学习管道的编排。
- 简单的实验:让您轻松尝试各种想法和技术,并管理各种试验/实验。
- 易于重用:使您能够重用组件和管道,从而快速创建端到端解决方案,而无需每次重新构建。
Kubeflow Pipelines 可作为 Kubeflow 的核心组件或独立安装。
- 了解有关安装 Kubeflow 的更多信息。^12 (opens new window)
- 了解有关独立安装 Kubeflow Pipelines 的更多信息。^13 (opens new window)
由于 kubeflow/pipelines#1700^14 (opens new window),Kubeflow pipelines 中的容器生成器目前仅为 Google 云平台(GCP)准备证书。因此,容器生成器仅支持 Google container Registry。但是,如果正确设置了获取图像的凭据,则可以将容器图像存储在其他注册表中。
# 3.3.1.1.3.什么是管道?
管道是对 ML 工作流的描述,包括工作流中的所有组件以及它们如何以图形的形式组合。(请参见下面显示管道图示例的屏幕截图。)管道包括运行管道所需的输入(参数)的定义以及每个组件的输入和输出。
开发完管道后,您可以在 Kubeflow Pipelines UI 上上传和共享它。
管道组件是一组自包含的用户代码,打包为 Docker 映像^15 (opens new window),执行管道中的一个步骤。例如,组件可以负责数据预处理、数据转换、模型训练等。
请参见管道和组件的概念指南。
# 3.3.1.1.4.管道示例
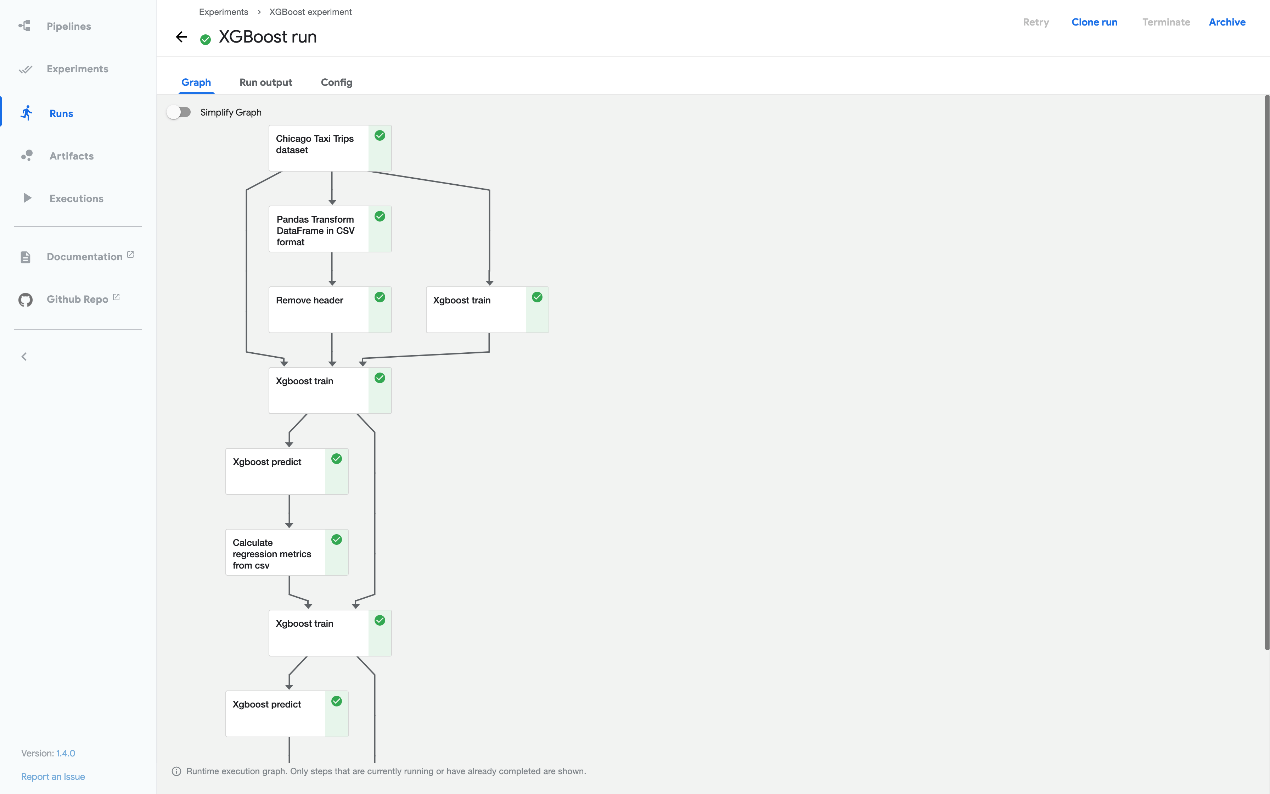
下面的截图和代码显示了 xgboost-training-cm.py 管道,它使用 CSV 格式的结构化数据创建 XGBoost 模型。您可以在 GitHub 上看到源代码^16 (opens new window)和有关管道的其他信息。
管道的运行时执行图
下面的屏幕截图显示了 Kubeflow Pipelines UI 中示例管道的运行时执行图:
# 3.3.1.1.5.表示管道的 Python 代码
下面是 Python 代码的摘录,其中定义了 xgboost 训练 cm。py 管道。你可以在 GitHub 上看到完整的代码。
@dsl.pipeline(
name='XGBoost Trainer',
description='A trainer that does end-to-end distributed training for XGBoost models.'
)
def xgb_train_pipeline(
output='gs://your-gcs-bucket',
project='your-gcp-project',
cluster_name='xgb-%s' % dsl.RUN_ID_PLACEHOLDER,
region='us-central1',
train_data='gs://ml-pipeline-playground/sfpd/train.csv',
eval_data='gs://ml-pipeline-playground/sfpd/eval.csv',
schema='gs://ml-pipeline-playground/sfpd/schema.json',
target='resolution',
rounds=200,
workers=2,
true_label='ACTION',
):
output_template = str(output) + '/' + dsl.RUN_ID_PLACEHOLDER + '/data'
# Current GCP pyspark/spark op do not provide outputs as return values, instead,
# we need to use strings to pass the uri around.
analyze_output = output_template
transform_output_train = os.path.join(output_template, 'train', 'part-*')
transform_output_eval = os.path.join(output_template, 'eval', 'part-*')
train_output = os.path.join(output_template, 'train_output')
predict_output = os.path.join(output_template, 'predict_output')
with dsl.ExitHandler(exit_op=dataproc_delete_cluster_op(
project_id=project,
region=region,
name=cluster_name
)):
_create_cluster_op = dataproc_create_cluster_op(
project_id=project,
region=region,
name=cluster_name,
initialization_actions=[
os.path.join(_PYSRC_PREFIX,
'initialization_actions.sh'),
],
image_version='1.2'
)
_analyze_op = dataproc_analyze_op(
project=project,
region=region,
cluster_name=cluster_name,
schema=schema,
train_data=train_data,
output=output_template
).after(_create_cluster_op).set_display_name('Analyzer')
_transform_op = dataproc_transform_op(
project=project,
region=region,
cluster_name=cluster_name,
train_data=train_data,
eval_data=eval_data,
target=target,
analysis=analyze_output,
output=output_template
).after(_analyze_op).set_display_name('Transformer')
_train_op = dataproc_train_op(
project=project,
region=region,
cluster_name=cluster_name,
train_data=transform_output_train,
eval_data=transform_output_eval,
target=target,
analysis=analyze_output,
workers=workers,
rounds=rounds,
output=train_output
).after(_transform_op).set_display_name('Trainer')
_predict_op = dataproc_predict_op(
project=project,
region=region,
cluster_name=cluster_name,
data=transform_output_eval,
model=train_output,
target=target,
analysis=analyze_output,
output=predict_output
).after(_train_op).set_display_name('Predictor')
_cm_op = confusion_matrix_op(
predictions=os.path.join(predict_output, 'part-*.csv'),
output_dir=output_template
).after(_predict_op)
_roc_op = roc_op(
predictions_dir=os.path.join(predict_output, 'part-*.csv'),
true_class=true_label,
true_score_column=true_label,
output_dir=output_template
).after(_predict_op)
dsl.get_pipeline_conf().add_op_transformer(
gcp.use_gcp_secret('user-gcp-sa'))
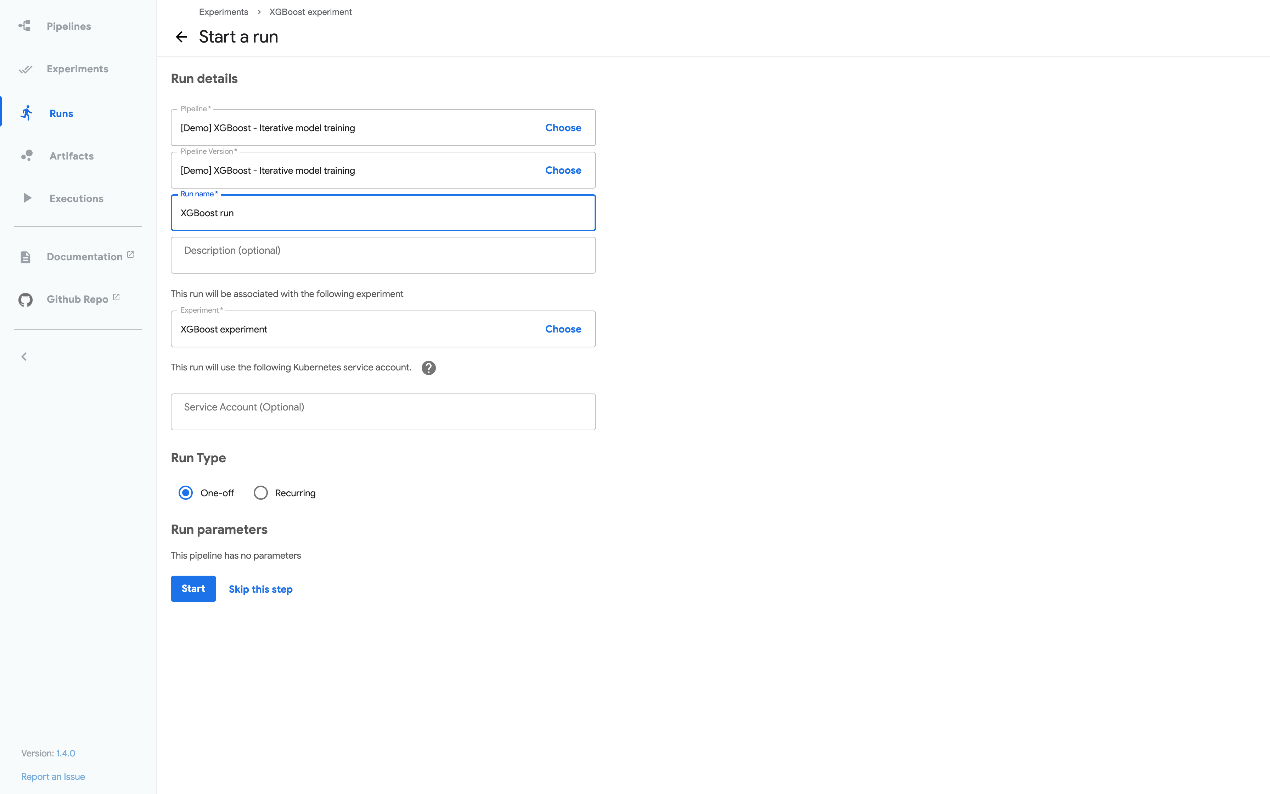
# 3.3.1.1.6.Kubeflow Pipelines UI 上的管道输入数据
下面的部分截图显示了 Kubeflow Pipelines UI,用于启动管道运行。代码中的管道定义决定了 UI 表单中显示的参数。管道定义还可以设置参数的默认值:
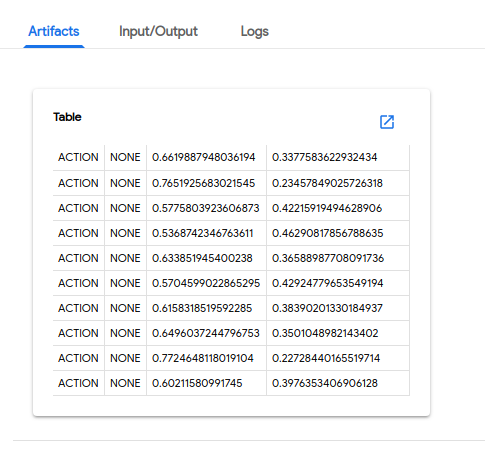
# 3.3.1.1.7.管道输出
以下屏幕截图显示了 Kubeflow Pipelines UI 上可见的管道输出示例。预测结果:
混淆矩阵:

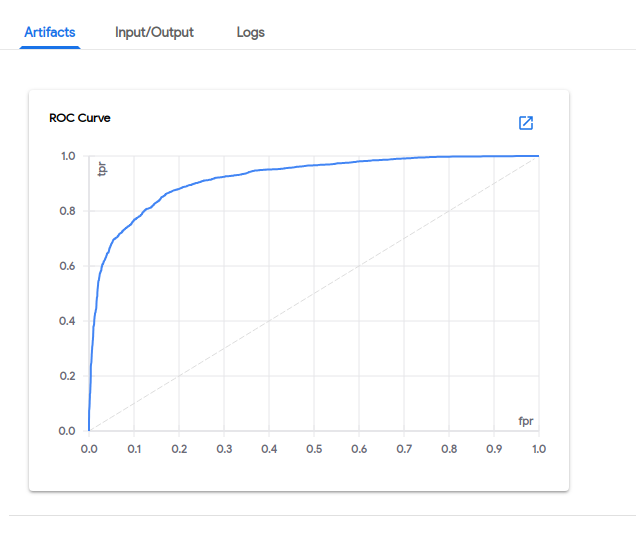
接收机工作特性(ROC)曲线:
# 3.3.1.1.8.体系架构综述
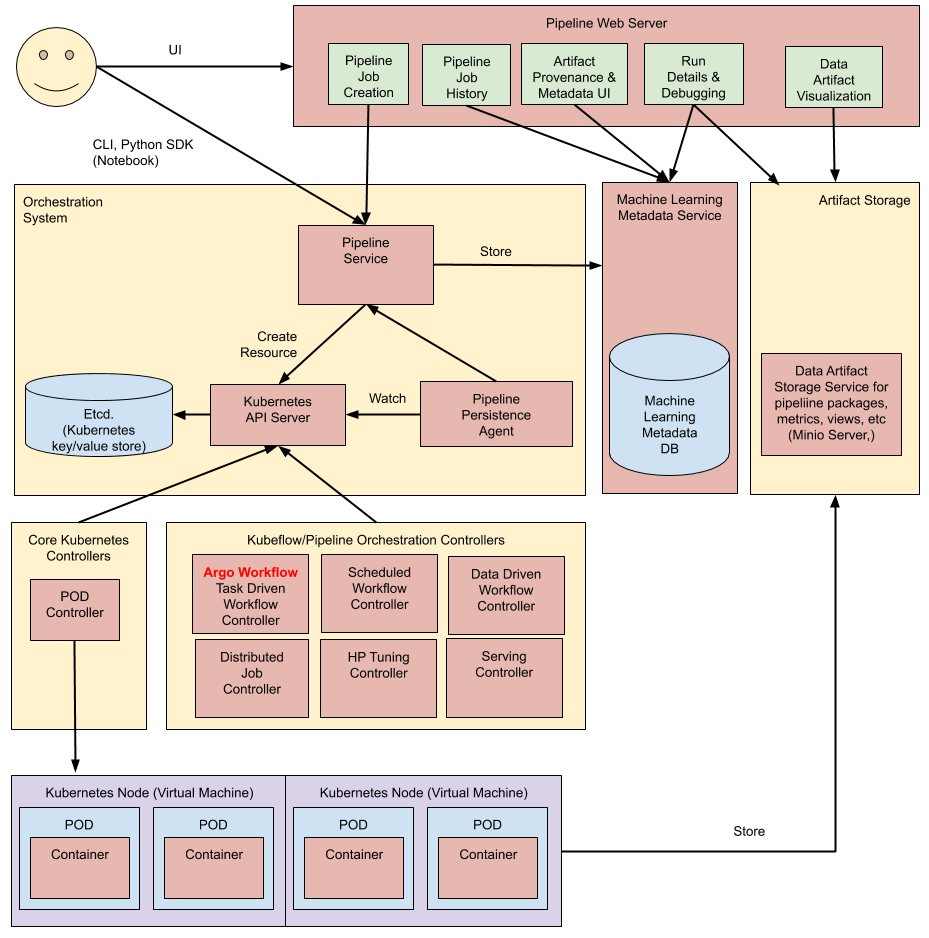
在高层,管道的执行过程如下:
- **Python SDK:**您可以使用 Kubeflow Pipelines 域特定语言(DSL)创建组件或指定管道。
- **DSL 编译器:**DSL 编译器将管道的 Python 代码转换为静态配置(YAML)。
- 管道服务(Pipeline Service):调用管道服务以从静态配置创建管道运行。
- **Kubernetes 资源(Kubernetes resources):**管道服务调用 Kubernetes API 服务器来创建运行管道所需的 Kubernetes 资源(CRD)。
- **编排控制器(Orchestration controllers):**一组编排控制器执行完成管道所需的容器。容器在虚拟机上的 Kubernetes Pods 中执行。一个示例控制器是 Argo 工作流控制器,它协调任务驱动的工作流。
- 工件存储(Artifact storage):Pods 存储两种数据:
- **元数据(Metadata):**实验、作业、管道运行和单标量度量。度量数据是为了排序和过滤而聚合的。Kubeflow Pipelines 将元数据存储在 MySQL 数据库中。
- 工件(Artifacts):管道包、视图和大规模度量(时间序列)。使用大规模度量来调试管道运行或调查单个运行的性能。Kubeflow Pipelines 将工件存储在工件存储库中,如 Minio 服务器或云存储。
- MySQL 数据库和 Minio 服务器都由 Kubernetes Persistent Volume 子系统支持。
- **持久化代理和 ML 元数据:**Pipeline 持久化代理监视 Pipeline Service 创建的 Kubernetes 资源,并将这些资源的状态持久化在 ML 元数据服务中。Pipeline Persistence Agent 记录执行的容器集及其输入和输出。输入/输出由容器参数或数据工件 URI 组成。
- **管道 web 服务器:**管道 web 服务器从各种服务收集数据,以显示相关视图:当前运行的管道列表、管道执行历史、数据工件列表、有关单个管道运行的调试信息、有关单个管程运行的执行状态。
# 3.3.1.2.概述
# 3.3.1.2.1.快速启动
如果您想了解 Kubeflow Pipelines 用户界面(UI)并快速运行简单的管道,请使用本指南。
本快速入门指南的目的是展示如何使用 Kubeflow Pipelines 安装附带的两个示例,这些示例在 Kubeflow Pipelines UI 上可见。您可以使用本指南作为 Kubeflow Pipelines UI 的介绍。
3.3.1.2.1.1.部署 Kubeflow 并打开 Kubeflow Pipelines UI
有几种部署 Kubeflow Pipelines 的选项,请选择最适合您需要的选项。如果您不确定,只想尝试 Kubeflow 管道,建议从独立部署开始。
一旦您部署了 Kubeflow Pipelines,请确保您可以访问 UI。访问 UI 的步骤因用于部署 Kubeflow Pipelines 的方法而异。
3.3.1.2.1.2.运行基本管道
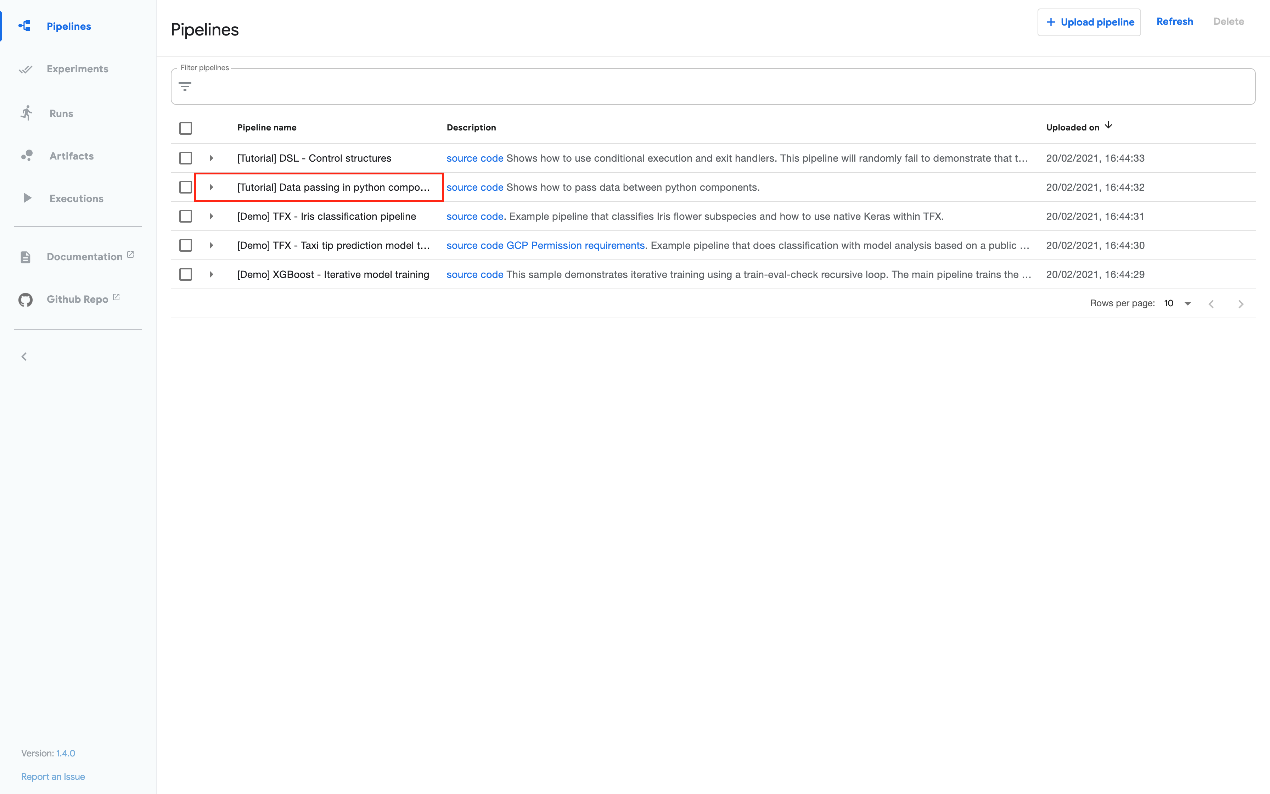
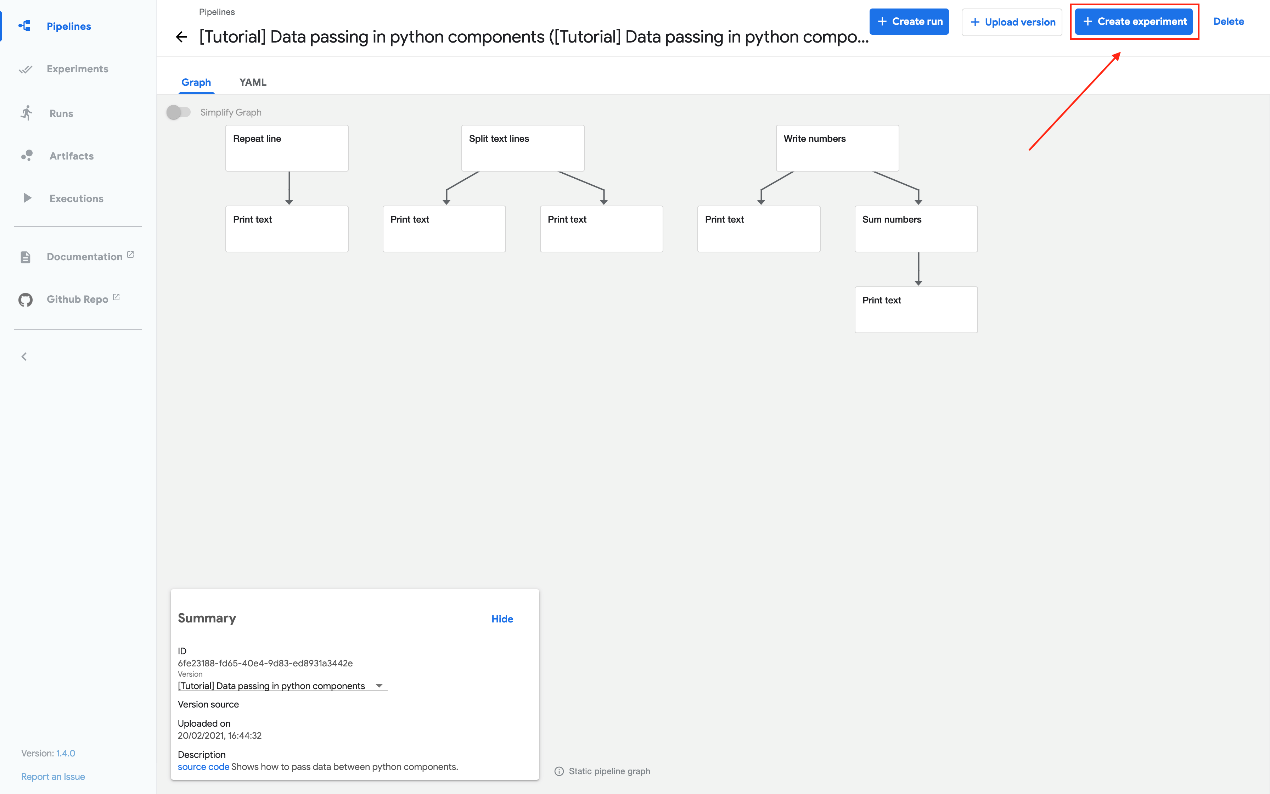
Kubeflow Pipelines 提供了一些示例,您可以使用它们快速试用 Kubeflow Pipelines。下面的步骤向您展示了如何运行包含一些 Python 操作但不包含机器学习(ML)工作负载的基本示例:
- 在管道 UI 上单击示例的名称[Tutorial]Data passing in python components:
- 单击创建实验(Create experiment):
- 按照提示创建实验,然后创建运行。该示例为您所需的所有参数提供默认值。以下屏幕截图假设您已经创建了名为 My experience 的实验,现在正在创建名为 My first run 的运行(run):
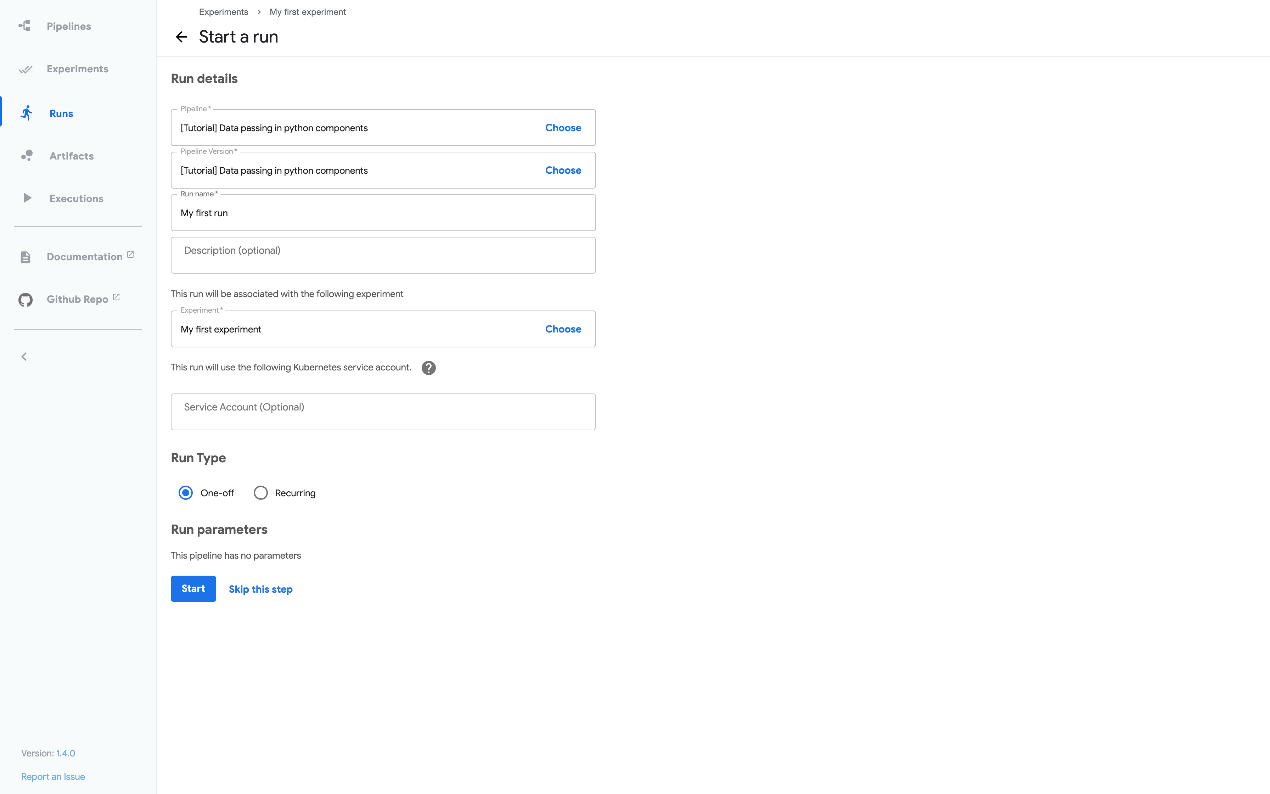
- 单击“开始(Start)”以运行管道。
- 在实验仪表板上单击运行的名称:
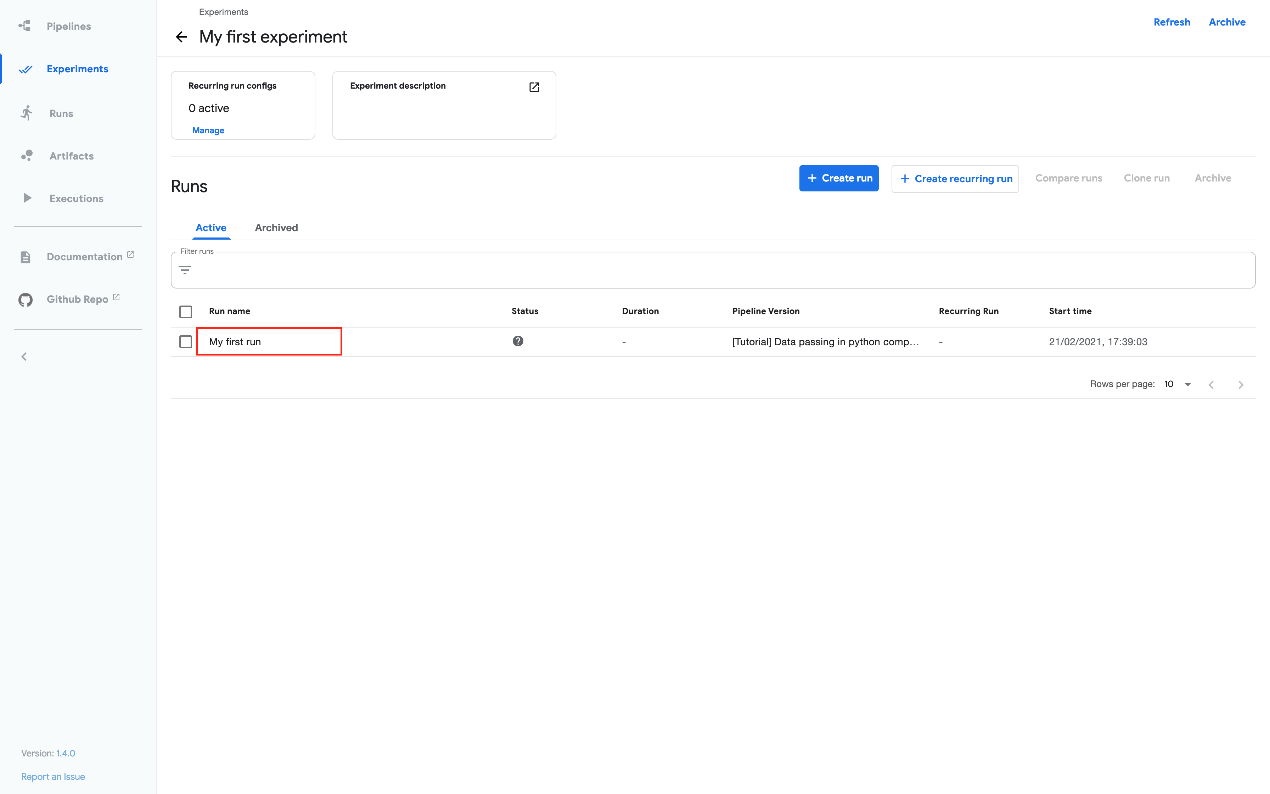
- 通过单击图形组件和其他 UI 元素,浏览图形和运行(run)的其他方面:
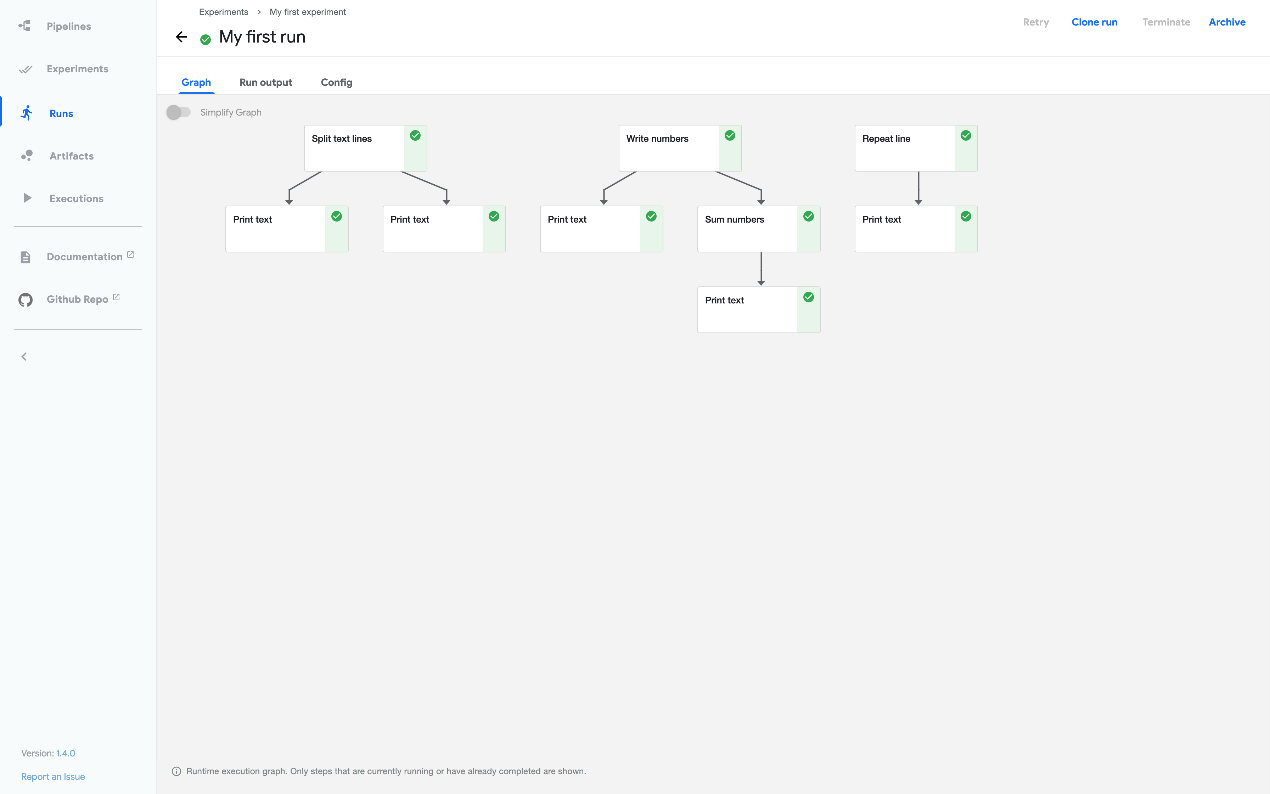
您可以在 Kubeflow Pipelines repo 中找到数据传入 python 组件教程的源代码^17 (opens new window)。
3.3.1.2.1.3.运行 ML 管道
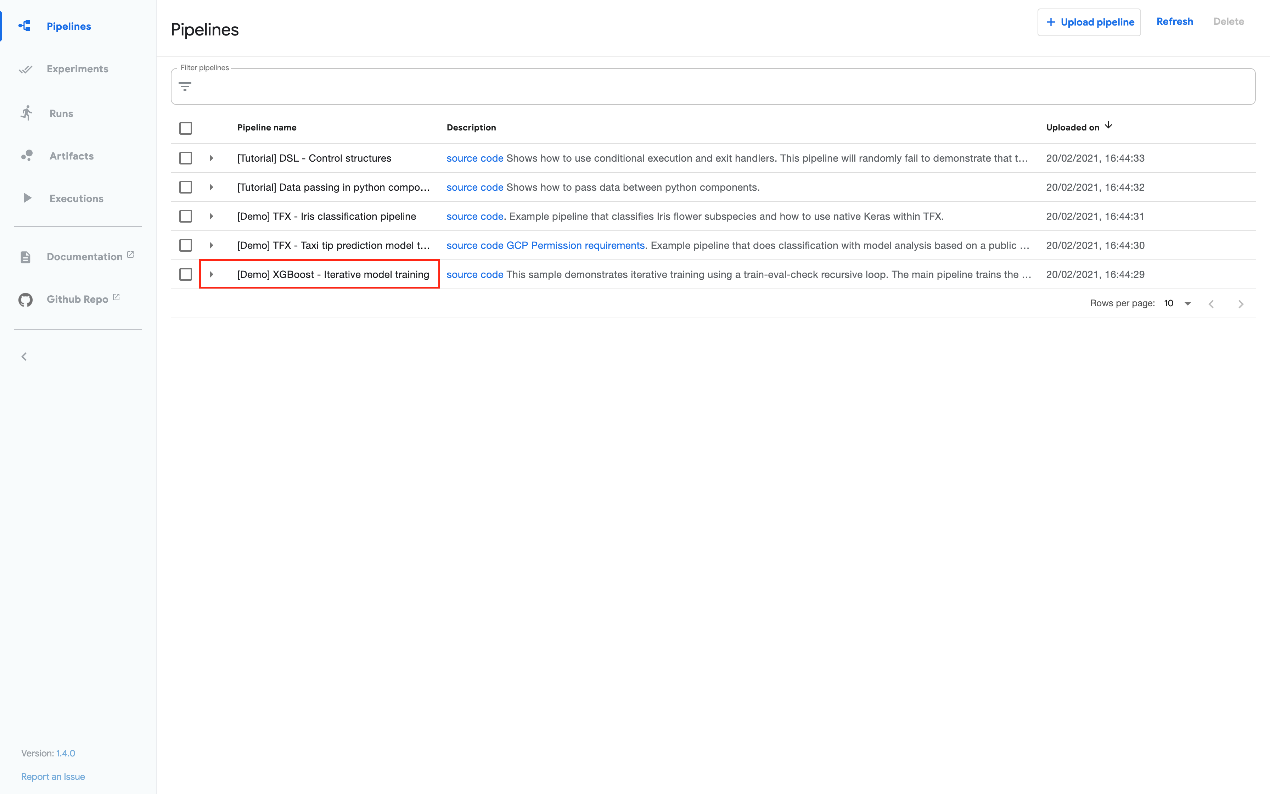
本节向您展示如何从管道 UI 运行 XGBoost 示例。与上述基本示例不同,XGBoost 示例确实包含 ML 组件。按照以下步骤运行示例:
- 在管道 UI 上单击示例名称**[Demo] XGBoost - Iterative model training**训练:
- 单击创建实验(Create experiment)。
- 按照提示创建实验(experiment),然后创建运行( run)。以下屏幕截图显示了运行详细信息:
- 单击“开始”(Start)创建管路。
- 在实验仪表板上单击运行的名称。
- 通过单击图形组件和其他 UI 元素,浏览图形和跑步的其他方面。以下屏幕截图显示了管道运行完成后的部分图形:
您可以在 Kubeflow Pipelines repo 中找到 XGBoost - Iterative model training demo^18 (opens new window)源代码。
# 3.3.1.2.2.管道接口
您可以与 Kubeflow Pipelines 系统交互的方式。本页介绍了可用于使用 Kubeflow Pipelines 构建和运行机器学习(ML)工作流的界面。
3.3.1.2.2.1.用户界面(UI)
您可以通过单击 Kubeflow UI 上的 Pipeline Dashboard 来访问 Kubeflow Pipelines UI。Kubeflow Pipelines UI 如下所示:
从 Kubeflow Pipelines UI,您可以执行以下任务:
- 运行一个或多个预加载的样本以快速测试管道。
- 将管道作为压缩文件上载。管道可以是您已经构建的管道(参见如何构建管道^19 (opens new window)),也可以是某人与您共享的管道。
- 创建一个实验,对一个或多个管道运行进行分组。参见实验的定义^20 (opens new window)。
- 在实验中创建并开始跑步。运行是管道的一次执行。请参见运行的定义^21 (opens new window)。
- 查询浏览管道运行的配置、图形和输出。
- 比较实验中一次或多次运行的结果。
- 通过创建定期运行计划运行。
有关访问 Kubeflow Pipelines UI 和运行示例的更多信息,请参阅快速入门指南。
构建管道组件时,可以写出信息以显示在 UI 中。请参阅在 UI 中导出度量^22 (opens new window)和可视化结果的指南。
3.3.1.2.2.2.开发包
Kubeflow Pipelines SDK 提供了一组 Python 包,您可以使用这些包来指定和运行 ML 工作流。
请参阅 Kubeflow Pipelines SDK^23 (opens new window)的简介,了解如何使用 SDK 构建管道组件和管道。
3.3.1.2.2.3.REST API
Kubeflow Pipelines API 对于持续集成/部署系统非常有用,例如,您希望将管道执行合并到 shell 脚本或其他系统中。例如,您可能希望在新数据进入时触发管道运行。请参阅 Kubeflow Pipelines API^24 (opens new window)参考文档。
# 3.3.1.2.3.多用户隔离
Kubeflow Pipelines 中多用户隔离的工作原理。Kubeflow 管道的多用户隔离是 Kubeflow 整体多租户特性的一部分。
资源是如何分离的?
Kubeflow Pipelines 使用 Kubernetes 命名空间分离资源,这些命名空间由 Kubeflow 的 Profile 资源管理^25 (opens new window)。其他用户未经许可无法查看您的 Profile/Namespace 中的资源,因为 Kubeflow Pipelines API 服务器拒绝当前用户无权访问的命名空间请求。
“实验(Experiments)”直接属于命名空间,运行和重复运行属于其父实验的命名空间。
“管道运行(Pipeline Runs)”在用户命名空间中执行,因此用户可以利用 Kubernetes 命名空间隔离。例如,他们可以为不同命名空间中的其他服务配置不同的机密。
使用 UI 时
当您从 Kubeflow Dashboard 访问 Kubeflow Pipelines UI 时,它只显示所选命名空间中的“实验”、“运行”和“重复运行”。类似地,当您从 UI 创建资源时,它们也属于您选择的名称空间。
使用 SDK 时
如何将 Pipelines SDK 连接到 Kubeflow Pipelines 将取决于您的 Kubeflow 部署类型以及从何处运行代码。
- 完全 Kubeflow(来自集群内部)
- 完全 Kubeflow(来自集群外部)
- 独立的 Kubeflow 管道(来自集群内部)
- 独立 Kubeflow 管道(来自集群外部)
下面的 Python 代码将从完整的 Kubeflow 集群中的 Pod 创建一个实验(以及相关的运行)。
import kfp
# the namespace in which you deployed Kubeflow Pipelines
kubeflow_namespace = "kubeflow"
# the namespace of your pipelines user (where the pipeline will be executed)
user_namespace = "jane-doe"
# the KF_PIPELINES_SA_TOKEN_PATH environment variable is used when no `path` is set
# the default KF_PIPELINES_SA_TOKEN_PATH is /var/run/secrets/kubeflow/pipelines/token
credentials = kfp**.auth.ServiceAccountTokenVolumeCredentials(path=None)**
# create a client
client = kfp**.Client(host=f"http://ml-pipeline-ui.{kubeflow_namespace}",** credentials**=credentials)**
# create an experiment
client**.create_experiment(name="<YOUR_EXPERIMENT_ID>",** namespace**=user_namespace)**
print**(client.list_experiments(namespace=user_namespace))**
# create a pipeline run
client**.run_pipeline(**
experiment*id**="<YOUR_EXPERIMENT_ID>",***# the experiment determines the namespace_
job_name**="<YOUR_RUN_NAME>",**
pipelineid**=**"<YOUR_PIPELINE_ID>"# the pipeline definition to run_
)
print**(client.list_runs(experiment_id="<YOUR_EXPERIMENT_ID>"))**
print**(client.list_runs(namespace=user_namespace))**
使用 REST API 时
当调用 Kubeflow Pipelines REST API^26 (opens new window)时,实验 API 需要命名空间参数。命名空间由类型为 namespace 和 key 的“资源引用”指定。id 等于命名空间名称。以下代码使用生成的 pythonAPI 客户端创建实验和管道运行。
import kfp
from kfp_server_api import *
# the namespace in which you deployed Kubeflow Pipelines
kubeflow_namespace = "kubeflow"
# the namespace of your pipelines user (where the pipeline will be executed)
user_namespace = "jane-doe"
# the KF_PIPELINES_SA_TOKEN_PATH environment variable is used when no `path` is set
# the default KF_PIPELINES_SA_TOKEN_PATH is /var/run/secrets/kubeflow/pipelines/token
credentials = kfp**.auth.ServiceAccountTokenVolumeCredentials(path=None)**
# create a client
client = kfp**.Client(host=f"http://ml-pipeline-ui.{kubeflow_namespace}",** credentials**=credentials)**
# create an experiment
experiment**😗* ApiExperiment = client**._experiment_api.create_experiment(**
body**=ApiExperiment(**
name**="<YOUR_EXPERIMENT_ID>",**
resource_references**=[**
ApiResourceReference**(**
key**=ApiResourceKey(**
id**=user_namespace,**
type**=ApiResourceType.NAMESPACE,**
),
relationship**=ApiRelationship.OWNER,**
)
],
)
)
print**("-------- BEGIN: EXPERIMENT --------")**
print**(experiment)**
print**("-------- END: EXPERIMENT ----------")**
# get the experiment by name (only necessary if you comment out the `create_experiment()` call)
# experiment: ApiExperiment = client.get_experiment(
# experiment_name="<YOUR_EXPERIMENT_ID>",
# namespace=user_namespace
# )
# create a pipeline run
run**😗* ApiRunDetail = client**._run_api.create_run(**
body**=ApiRun(**
name**="<YOUR_RUN_NAME>",**
pipeline_spec**=ApiPipelineSpec(**
# replace <YOUR_PIPELINE_ID> with the UID of a pipeline definition you have previously uploaded
pipeline_id**="<YOUR_PIPELINE_ID>",**
),
resource_references**=[ApiResourceReference(**
key**=ApiResourceKey(**
id**=experiment.id,**
type**=ApiResourceType.EXPERIMENT,**
),
relationship**=ApiRelationship.OWNER,**
)
],
)
)
print**("-------- BEGIN: RUN --------")**
print**(run)**
print**("-------- END: RUN ----------")**
# view the pipeline run
runs**😗* ApiListRunsResponse = client**._run_api.list_runs(**
resource_reference_key_type**=ApiResourceType.EXPERIMENT,**
resource_reference_key_id**=experiment.id,**
)
print**("-------- BEGIN: RUNS --------")**
print**(runs)**
print**("-------- END: RUNS ----------")**
# 3.3.1.2.4.缓存
Kubeflow Pipelines 步骤缓存入门。
从 Kubeflow Pipelines 0.4 开始,Kubeflow pipelines 支持独立部署和 AI 平台管道中的步骤缓存功能。
开始之前
本指南告诉您 Kubeflow Pipelines 步骤缓存的基本概念以及如何使用它。本指南假设您已经安装了 Kubeflow Pipelines,或者希望使用 Kubeflow pipelines 部署指南中的选项来部署 Kubeflow Pipelines。
什么是步骤缓存?
Kubeflow Pipelines 缓存提供步骤级输出缓存。默认情况下,为通过 KFP 后端和 UI 提交的所有管道启用缓存。例外的是使用 TFXSDK 编写的管道,它有自己的缓存机制。缓存密钥计算基于组件(基本映像、命令行、代码)、传递给组件的参数(值或工件)以及任何其他自定义。如果组件完全相同,并且参数与之前的某些执行完全相同,则可以跳过该任务,并使用旧步骤的输出。可以控制缓存重用行为,管道作者可以指定考虑重用的缓存数据的最大过时性。启用缓存后,系统可以跳过已执行的步骤,从而节省时间和金钱。
禁用/启用缓存
默认情况下,在 Kubeflow Pipelines 0.4 之后启用缓存。以下是有关禁用和启用缓存服务的说明:
配置对 Kubeflow 集群的访问
使用以下说明配置 kubectl 以访问您的 Kubeflow 集群。
- 要检查是否安装了 kubectl,请运行以下命令:
which kubectl
答案应该是这样的:
/usr/bin/kubectl
如果没有安装 kubectl,请按照指南中的说明安装和设置 kubectl^27 (opens new window)。
- 按照指南配置对 Kubernetes 集群的访问。
在 Kubeflow Pipelines 部署中禁用缓存:
- 确保集群中存在更改网络连接配置(mutating webhook configuration):
export NAMESPACE=<Namespace where KFP is installed>
kubectl get mutatingwebhookconfiguration cache-webhook-${NAMESPACE}
- 更改更改 webhook 配置规则:
kubectl patch mutatingwebhookconfiguration cache-webhook-${NAMESPACE} --type='json' -p='[{"op":"replace", "path": "/webhooks/0/rules/0/operations/0", "value": "DELETE"}]'
启用缓存
- 确保集群中存在更改网络连接配置(mutatingwebhookconfiguration):
export NAMESPACE=<Namespace where KFP is installed>
kubectl get mutatingwebhookconfiguration cache-webhook-${NAMESPACE}
- 更改回更改 webhook 配置规则:
kubectl patch mutatingwebhookconfiguration cache-webhook-${NAMESPACE} --type='json' -p='[{"op":"replace", "path": "/webhooks/0/rules/0/operations/0", "value": "CREATE"}]'
管理缓存老化
默认情况下,缓存是启用的,如果您使用相同的参数执行了相同的组件,则将跳过该组件的任何新执行,并从缓存中获取输出。对于某些场景,某些组件的缓存输出数据可能会在一段时间后变得太过时,无法使用。要控制重用缓存数据的最大过时性,可以设置步骤的 max_cache_staleness 参数。max_cache_staleness 采用 RFC3339^28 (opens new window)持续时间格式(因此 30 天=“P30D”)。默认情况下,max_cache_staleness 设置为无限大,因此任何旧缓存数据都将被重用。
def some_pipeline():
# task is a target step in a pipeline
task = some_op()
task.execution_options.caching_strategy.max_cache_staleness = "P30D"
理想情况下,组件代码应该是纯的和确定性的,因为它在给定相同输入的情况下产生相同的输出。如果您的组件不是确定性的(例如,它在每次调用时返回不同的随机数),您可能希望通过将 max_cache_staleness 设置为 0 来禁用从该组件创建的任务的缓存:
def some_pipeline():
# task is a target step in a pipeline
task_never_use_cache = some_op()
task_never_use_cache.execution_options.caching_strategy.max_cache_staleness = "P0D"
更好的解决方案是使组件具有确定性。如果组件使用随机数生成,则可以将 RNG 种子作为组件输入公开。如果组件获取一些变化的数据,您可以添加时间戳或日期输入。
# 3.3.1.2.5.Caching v2
从 Kubeflow Pipelines SDK v2 和 Kubeflow pipelines 1.7.0 开始,Kubeflow Pipelines 支持独立部署和 AI 平台管道中的步骤缓存功能。
开始之前
本指南告诉您 Kubeflow Pipelines 缓存的基本概念以及如何使用它。本指南假设您已经安装了 Kubeflow Pipelines,或者希望使用《Kubeflow Pipelines 部署指南》中的独立或 AI 平台 Pipelines 选项来部署 Kubeflow Pipelines。
什么是步骤缓存?
Kubeflow Pipelines 缓存提供了步骤级输出缓存,该过程通过跳过在前一次管道运行中完成的计算来帮助降低成本。默认情况下,使用 kfp.dsl.PipelineExecutionMode.V2_COMPATIBLE 模式为使用 Kubeflow pipelines SDK v2^29 (opens new window)构建的管道的所有任务启用缓存。当 Kubeflow Pipeline 运行管道时,它会检查 Kubeflow Pipeline 中是否存在执行,以及每个管道任务的接口。任务的接口定义为管道任务规范(基本图像、命令、参数)、管道任务的输入(工件的名称和 id、参数的名称和值)和管道任务的输出规范(工件和参数)的组合。注意:如果生成工件的生产者任务未被缓存,则生产者任务将生成具有不同 ID 的新工件,而使用生产者任务生成的工件的下游任务将不会命中缓存。
如果 Kubeflow Pipelines 中有匹配的执行,则使用该执行的输出,并跳过该任务。缓存被命中的示例:
禁用/启用缓存
默认情况下,Kubeflow Pipelines SDK v2 使用 kfp.dsl.PipelineExecutionMode.V2_COMPATIBLE 启用缓存。
可以为使用 Python 创建的管道运行关闭执行缓存。使用 create_run_from_pipeline_func^30 (opens new window)或 create_run_from_pipeine_package^31 (opens new window)或 run_pipeline^32 (opens new window)运行管道时,可以使用 enable_caching 参数指定此管道运行不使用缓存。
# 3.3.1.2.6.Pipeline Root
从 Kubeflow Pipelines SDKv2 和 Kubeflow Pipelines 1.7.0 开始,Kubeflow Pipelines 支持一个新的中间工件库功能:独立部署^33 (opens new window)和 AI 平台管道^34 (opens new window)中的管道根。
3.3.1.2.6.1.开始之前
本指南告诉您 Kubeflow Pipelines 管道根的基本概念以及如何使用它。本指南假设您已经安装了 Kubeflow Pipelines,或者希望使用《Kubeflow Pipelines 部署指南》中的独立或 AI 平台 Pipelines 选项来部署 Kubeflow Pipelines。
3.3.1.2.6.2.什么是管道根?
Pipeline 根表示一个工件库,Kubeflow Pipelines 存储管道的工件。该功能支持使用 Go CDK^35 (opens new window)的 MinIO、S3 和 GCS。在 S3 和 GCS 中,当 Kubeflow Pipelines 与其他系统集成时,可以更容易地访问工件。
**注意:**对于 MinIO,不能更改 MinIO 实例。Kubeflow Pipelines 只能使用自己部署的 Minio 实例。(如果需要指定 Minio 实例,请点击此 GitHub 问题^36 (opens new window)。)
3.3.1.2.6.3.如何配置管道根身份验证
最小 IO
您不需要通过 MinIO 的身份验证。Kubeflow Pipelines 配置了与自己一起部署的 MinIO 实例的身份验证。
GCS
如果要指定 GCS 的管道根:检查身份验证管道^37 (opens new window)。
S3
如果要指定 S3 的管道根,请选择以下选项之一:
- 通过 AWS IRSA:
- 通过 kfp-sdk:dsl.get_pipeline_conf().add_op_transformer(aws.use_aws_secret('xxx'、'xxx'和'xxx'))
参考文献:
加法运算变压器
使用 aws 秘密
3.3.1.2.6.4.如何配置管道根
通过配置映射
您可以通过更改 Kubernetes 命名空间中 ConfigMaps kfp-launcher 的 defaultPipelineRoot 条目来为 Kubeflow Pipelines 配置默认管道根。
kubectl edit configMap kfp-launcher -n ${namespace}
此管道根将是 Kubernetes 命名空间中运行的所有管道的默认管道根,除非您使用以下选项之一覆盖它:
通过建筑管道
构建管道时^38 (opens new window),可以通过 kfp.dsl.pipeline 注释配置管道根
通过 SDK 提交管道
使用以下方法之一提交管道时,可以通过 pipeline_root 参数配置管道根:
- 创建 run_from_pipeline_func^39 (opens new window)
- 创建 run_from_pipeline_package^40 (opens new window)
- run_pipeline^41 (opens new window)。
3.3.1.2.6.5.通过提交管道直通 UI
在 UI 中提交管道运行时,可以通过 pipeline_root 运行参数配置管道根。
# 3.3.1.3.概念
# 3.3.1.3.1.管道
流水线是机器学习(ML)工作流的描述,包括工作流中的所有组件^42 (opens new window)以及这些组件如何以图^43 (opens new window)形的形式相互关联。管道配置包括运行管道所需的输入(参数)以及每个组件的输入和输出的定义。
当您运行管道时,系统会启动一个或多个 Kubernetes Pod,对应于工作流(管道)中的步骤^44 (opens new window)(组件)。Pods 启动 Docker 容器,容器反过来启动程序。开发完管道后,您可以使用 Kubeflow Pipelines UI 或 Kubeflow Pipelines SDK 上传管道。
# 3.3.1.3.2.部件 Component
管道组件是一组自包含的代码,用于执行 ML 工作流(管道)中的一个步骤,例如数据预处理、数据转换、模型训练等。组件类似于函数,因为它具有名称、参数、返回值和主体。
3.3.1.3.2.1.部件代码
每个组件的代码包括以下内容:
- 客户端代码:与端点对话以提交作业的代码。例如,与 Google Dataproc API 对话以提交 Spark 作业的代码。
- 运行时代码:执行实际作业并通常在集群中运行的代码。例如,将原始数据转换为预处理数据的 Spark 代码。
请注意名为“mytask”的任务的客户端代码和运行时代码的命名约定:
mytask.py 程序包含客户端代码。
mytask 目录包含所有运行时代码。
3.3.1.3.2.2.组件定义
YAML 格式的组件规范描述了 KubeflowPipelines 系统的组件。组件定义包含以下部分:
- 元数据(Metadata):名称、描述等。
- 接口(Interface):输入/输出规范(名称、类型、描述、默认值等)。
- 实现(Implementation):给定组件输入的一组参数值,说明如何运行组件。实现部分还描述了在组件完成运行后如何从组件获取输出值。
有关组件的完整定义,请参阅组件规范^45 (opens new window)。
3.3.1.3.2.3.集装箱化组件(Containerizing components)
您必须将组件打包为 Docker 映像^46 (opens new window)。组件表示容器内的特定程序或入口点。
管道中的每个组件都独立执行。这些组件不在同一进程中运行,并且不能直接共享内存数据。您必须将在组件之间传递的所有数据片段序列化(到字符串或文件),以便数据可以通过分布式网络传输。然后必须对数据进行反序列化,以便在下游组件中使用。
# 3.3.1.3.3.图表
Kubeflow 管道中图形的概念概述。
图形是 Kubeflow Pipelines UI 中管道运行时执行的图形表示。该图显示了管道运行已执行或正在执行的步骤,箭头指示了每个步骤所表示的管道组件之间的父/子关系。运行开始后即可查看图形。图中的每个节点对应于管道中的一个步骤,并相应地标记。
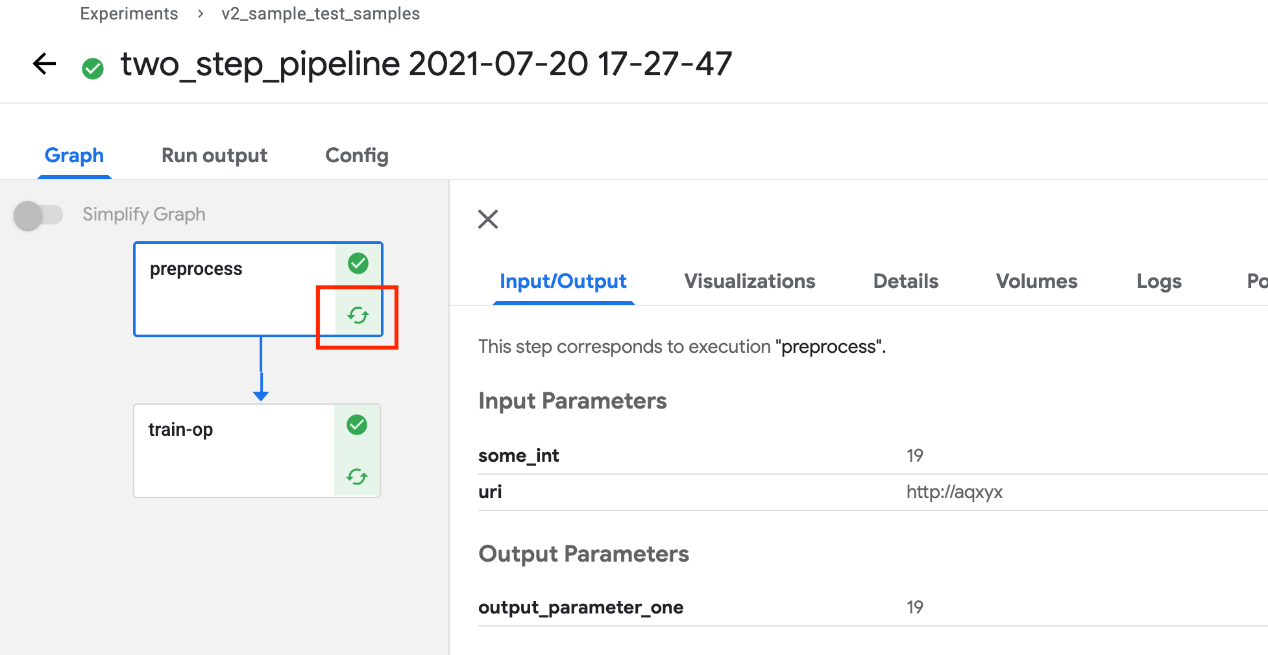
下面的屏幕截图显示了一个管道图示例:
每个节点的右上方都有一个图标,指示其状态:运行、成功、失败或跳过。(当节点的父级包含条件子句时,可以跳过该节点。)
# 3.3.1.3.4.实验
实验(experiment )是一个工作区,您可以在其中尝试不同的管道配置。您可以使用实验将跑步组织成逻辑组。实验可以包含任意运行,包括重复运行^47 (opens new window)(recurring runs)。
# 3.3.1.3.5.运行和定期运行(Run and Recurring Run)
Kubeflow 管道运行的概念概述
运行是管道的一次执行。运行包含您尝试的所有实验的不可变日志,并且设计为独立的,以允许重复性。您可以通过查看 Kubeflow Pipelines UI 上的详细信息页面来跟踪运行的进度,在那里可以看到运行时图形、输出工件和运行中每个步骤的日志。
Kubeflow Pipelines 后端 API 中的重复运行或作业是管道的可重复运行。循环运行的配置包括指定了所有参数值的管道副本和运行触发器。您可以在任何实验中开始重复运行,它将定期启动运行配置的新副本。您可以从 Kubeflow Pipelines UI 启用/禁用重复运行。您还可以指定并发运行的最大次数,以限制并行启动的运行次数。如果管道预计会运行很长一段时间,并且被触发频繁运行,这可能会很有帮助。
# 3.3.1.3.6.运行触发器(Run Trigger)
Kubeflow 管道中运行触发器的概念概述
运行触发器是一个标志,它告诉系统循环运行配置何时产生新的运行。以下类型的运行触发器可用:
- 周期性:用于基于间隔的运行调度(例如:每 2 小时或每 45 分钟)。
- Cron:用于为调度运行指定 Cron 语义。
# 3.3.1.3.7.步(step)
步骤是执行管道中的一个组件。步骤与其组件之间的关系是实例化的关系,非常类似于运行与其管道之间的关系。在复杂的管道中,组件可以在循环中多次执行,或者在解析管道代码中的 if/else 类子句后有条件地执行。
# 3.3.1.3.8.输出工件
Kubeflow Pipelines 中输出工件的概念概述
输出工件是由管道组件发出的输出,Kubeflow Pipelines UI 可以理解并呈现为丰富的可视化效果。管道组件包含工件是非常有用的,这样您就可以提供性能评估、运行的快速决策或不同运行之间的比较。人工制品还可以理解管道的各种组件是如何工作的。工件的范围可以从简单的数据文本视图到丰富的交互式可视化。
# 3.3.1.3.9.ML 元数据
Kubeflow Pipelines 中元数据的概念概述
**注意:**Kubeflow Pipelines 已经从使用 Kubeflow/metadata 转向使用 google/ml 元数据作为元数据依赖。
Kubeflow Pipelines 后端在元数据存储中存储管道运行的运行时信息。运行时信息包括任务的状态、工件的可用性、与执行或工件相关的自定义属性等。
如果不同运行中的多个执行正在使用一个工件,则可以查看管道运行中工件和执行之间的连接。这种连接可视化称为线型图。
# 3.3.1.4.安装 Installation
# 3.3.1.4.1.安装选项
Kubeflow Pipelines 提供了一些安装选项。本页介绍每个选项的选项和可用功能:
- Kubeflow Pipelines Standalone^48 (opens new window)是仅包含 Kubeflow 管道的最小便携式安装。
- Kubeflow Pipelines 作为完整 Kubeflow 部署的一部分^49 (opens new window),提供了所有 Kubeflow 组件以及与每个平台的更多集成。
- 测试版:谷歌云 AI 平台管道通过在谷歌云控制台上提供管理 UI,使在谷歌云上安装和使用 Kubeflow Pipelines 变得更加容易。
- 用于测试目的的本地^50 (opens new window)Kubeflow Pipelines 部署。
3.1.4.1.3.1.1.选择安装选项
- 除了管道之外,是否要使用其他 Kubeflow 组件?如果是,请选择完整的 Kubeflow 部署^51 (opens new window)。
- 您可以使用 cloud/prem Kubernetes 集群吗?如果不能,您应该尝试在本地 Kubernetes 集群上使用 Kubeflow Pipelines 进行学习和测试,方法是遵循在本地集群上部署 Kubeflow pipelines 中的步骤。
- 您想在多用户支持下使用 Kubeflow Pipelines 吗?如果是,请选择版本>=v1.1 的完整 Kubeflow 部署。
- 你在谷歌云上部署吗?
如果是,则部署 Kubeflow Pipelines Standalone。您还可以使用 Google Cloud AI Platform Pipelines 使用用户界面部署 Kubeflow Pipelines,但在可定制性和可升级性方面存在限制。有关详细信息,请阅读相应章节。
- 您可以在其他平台上部署。
在做出决定之前,请将您特定于平台的完整 Kubeflow 与 Kubeflow 独立管道进行比较。
**警告:**请谨慎选择安装选项,当前没有支持在不同安装选项之间迁移数据的路径。如果这对你很重要,请创建一个 GitHub 问题。
3.1.4.1.3.1.2.Kubeflow 独立管道
使用此选项可以将 Kubeflow Pipelines 部署到本地、云甚至本地 Kubernetes 集群,而不需要 Kubeflow 的其他组件。要部署 Kubeflow Pipelines Standalone,您只能使用 kustosize 清单。这个过程使得定制部署和将 Kubeflow Pipelines 集成到现有的 Kubernetes 集群中变得更加简单。
安装指南
Kubeflow Pipelines 独立部署指南
接口:
- Kubeflow 管道 UI
- Kubeflow 管道 SDK
- Kubeflow 管道 API
- Kubeflow Pipelines 端点仅为 Google Cloud 自动配置。
如果您希望在其他平台上部署 Kubeflow Pipelines,您可以通过 kubectl 端口转发访问它,也可以自己配置自己的特定于平台的授权端点。
发布时间表
Kubeflow Pipelines Standalone 可用于每个 Kubeflow Pipelines 版本。您将可以访问最新功能。
升级支持(Beta 版)
升级 Kubeflow Pipelines Standalone 介绍了如何就地升级。
谷歌云集成:
- 自动为您配置了具有身份验证支持的 Kubeflow Pipelines 公共端点。
- 通过云控制台 AI 平台管道仪表板中的开放管道仪表板链接打开 Kubeflow 管道 UI。
- (可选)您可以选择将数据保存在 Google 云管理存储(云 SQL 和云存储)中。
- 支持对 Google Cloud 进行身份验证的所有选项。
具体功能说明:
- 部署后,Kubernetes 集群仅包含 Kubeflow Pipelines。它不包括其他 Kubeflow 组件。例如,要使用 Jupyter 笔记本,您必须在云服务(如 AI 平台笔记本)中使用本地笔记本或托管笔记本。
- Kubeflow Pipelines 多用户支持在单机版中不可用,因为多用户支持依赖于其他 Kubeflow 组件。
完全 Kubeflow 部署
使用此选项可以将 Kubeflow Pipelines 部署到本地计算机、本地或云,作为完整 Kubeflow 安装的一部分。
安装指南
Kubeflow 安装指南
接口:
- Kubeflow 用户界面
- Kubeflow UI 内部或外部的 Kubeflow Pipelines UI
- Kubeflow 管道 SDK
- Kubeflow 管道 API
- 其他 Kubeflow API
- Kubeflow Pipelines 端点自动配置,每个平台都支持身份验证
发布时间表
完整的库贝洛每季度发布一次。它在接收 Kubeflow Pipelines 更新时有明显延迟。
| Kubeflow Version | Kubeflow Pipelines Version |
|---|---|
| 0.7.0 | 0.1.31 |
| 1.0.0 | 0.2.0 |
| 1.0.2 | 0.2.5 |
| 1.1.0 | 1.0.0 |
| 1.2.0 | 1.0.4 |
| 1.3.0 | 1.5.0 |
| 1.4.0 | 1.7.0 |
注意:Google Cloud、AWS 和 IBM Cloud 支持 Kubeflow Pipelines 1.0.0 和多用户分离。其他平台目前可能不是最新的,请参阅此 GitHub 问题以了解状态。
升级支持:请参阅 Google Cloud 指南中升级 Kubeflow Pipelines 的完整 Kubeflow 章节。
谷歌云集成:
- 使用云身份感知代理为您自动配置具有身份验证支持的 Kubeflow Pipelines 公共端点。
- 当前不支持将数据持久化在 Google 云托管存储(云 SQL 和云存储)中。有关最新状态,请参阅此 GitHub 问题。
- 您可以使用 Workload Identity 向 Google Cloud 进行身份验证。
具体功能说明:
- 部署后,Kubernetes 集群包括所有 Kubeflow 组件。例如,您可以使用与 Kubeflow 一起部署的 Jupyter 笔记本服务在 Kubeflow 集群中创建一个或多个笔记本服务器。
- Kubeflow Pipelines 多用户支持仅在完整的 Kubeflow 中可用。它支持使用一个 Kubeflow Pipelines 控制平面来协调多个用户命名空间中的用户管道运行,并获得授权。
- 最新的功能和 bug 修复可能不会很快出现,因为发布周期很长。
谷歌云 AI 平台管道
使用此选项将 Kubeflow Pipelines 部署到 Google 云市场中的 Google Kubernetes Engine(GKE)。您可以将 Kubeflow Pipelines 部署到现有或新的 GKE 集群,并在 GoogleCloud 中管理集群。
安装指南
Google Cloud AI 平台管道文档
接口:
- 用于管理 Kubeflow Pipelines 集群和其他 Google 云服务的 Google 云控制台
- 通过 Google 云控制台中的 Open Pipelines Dashboard 链接,Kubeflow Pipelines UI
- 云笔记本中的 Kubeflow Pipelines SDK
- 为您自动配置实例的 Kubeflow Pipelines 端点
发布时间表
AI Platform Pipelines 可用于一组选定的稳定 Kubeflow Pipelines 版本。您将收到比 Kubeflow Pipelines Standalone 稍慢的更新。
升级支持(Alpha)
不支持就地升级。
要通过重新安装(使用现有数据)升级 AI 平台管道,请参阅《升级 AI 平台管线》指南。
谷歌云集成:
- 您可以在云控制台 UI 上部署 AI 平台管道。
- 自动为您配置了具有身份验证支持的 Kubeflow Pipelines 公共端点。
- (可选)您可以选择将数据保存在 Google 云管理的存储服务(云 SQL 和云存储)中。
- 您可以使用计算引擎默认服务帐户向 Google Cloud 进行身份验证。但是,如果需要工作负载权限分离,则此方法可能不适用。
- 您可以在公共和私有 GKE 集群上部署 AI 平台管道,只要集群有足够的资源用于 AI 平台管道。
具体功能说明:
部署后,Kubernetes 集群仅包含 Kubeflow Pipelines。它不包括其他 Kubeflow 组件。例如,要使用 Jupyter 笔记本,可以使用 AI 平台笔记本。
Kubeflow Pipelines 多用户支持在 AI 平台 Pipelines 中不可用,因为多用户支持依赖于其他 Kubeflow 组件。
# 3.3.1.4.1.2.本地部署
Kubeflow 管道(种类、K3s、K3ai)的当地部署信息。本指南介绍了如何使用以下方法在本地 Kubernetes 集群上独立部署 Kubeflow Pipelines:
- kind
- K3 秒
- Windows Linux 子系统(WSL)上的 K3s
- K3ai[α]
此类部署方法可以是本地环境的一部分,使用提供的 kustosize 清单进行测试。本指南是部署 Kubeflow 管道(KFP)^52 (opens new window)。
3.1.4.1.3.3.开始之前
您应该熟悉 Kubernetes^53 (opens new window)、kubectl^54 (opens new window)和 kustomize^55 (opens new window)。
对于 kustomize 的本地支持,您需要 kubectl v1.14 或更高版本。您可以按照 kubectl 安装指南下载并安装 kubectl。
3.1.4.1.3.4.KIND
1.安装种类
kind^56 (opens new window)是一个使用 Docker 容器节点运行本地 Kubernetes 集群的工具。该类型主要用于测试 Kubernetes 本身。它也可用于本地开发或 CI。
您可以按照官方的快速入门来安装和配置种类。
从 Kind 开始:
在 Linux 上:
通过运行以下命令下载可执行文件并将其移动到 PATH 中的目录中:
curl -Lo ./kind https://kind.sigs.k8s.io/dl/**{**KIND_VERSION**}**/kind-linux-amd64 (opens new window) && \
chmod +x ./kind && \
mv ./kind /{YOUR_KIND_DIRECTORY}/kind
替换以下内容:
{KIND_VERSION}:种类版本;例如,自本指南编写之日起,v0.8.1
{YOUR_KIND_DIRECTORY}:PATH 中的目录
在 macOS 上:
您可以使用 Homebrew^57 (opens new window)安装种类:
brew install kind
在 Windows 上:
您可以使用管理 PowerShell 控制台运行以下命令,以下载可执行文件并将其移动到 PATH 中的目录:
PowerShell:运行以下命令下载 kind 可执行文件并将其移动到 PATH 中的目录:
curl**.exe -Lo kind-windows-amd64.exe https://kind.sigs.k8s.io/dl/{KIND_VERSION}/**kind-windows-amd64
Move-Item **.\kind-windows-amd64.exe c:\{YOUR_KIND_DIRECTORY}\kind.**exe
替换以下内容:
- {KIND_VERSION}:种类版本-例如 v0.9(查看种类发布页面上的最新稳定二进制版本)
- {YOUR_KIND_DIRECTORY}:PATH 中的种类目录
- {KIND_VERSION}:种类版本;例如,自本指南编写之日起,v0.8.1
- {YOUR_KIND_DIRECTORY}:PATH 中的目录
或者,您可以使用 Chocolateyhttps://chocolatey.org/packages/kind: (opens new window)
choco install kind
2.基于实物创建集群
安装了 kind 之后,可以使用以下命令在 kind 上创建 Kubernetes 集群:
kind create cluster
这将使用预构建的节点映像引导 Kubernetes 集群。您可以在 Docker Hub kindest/node 上找到该图像。如果您希望自己构建节点映像,可以使用 kind-build-node image 命令。有关详细信息,请参阅官方的构建映像部分。要指定另一个图像,请使用--image 标志。
默认情况下,集群将被命名为 kind。使用--name 标志为集群分配不同的上下文名称。
K3
1.在 K3s 上设置集群
K3s 是完全兼容的 Kubernetes 发行版,具有以下增强功能:
- 打包为单个二进制文件。
- 基于 sqlite3 作为默认存储机制的轻量级存储后端。etcd3、MySQL、Postgres 仍然可用。
- 包装在简单的启动器中,可以处理 TLS 和选项的许多复杂性。
- 对于轻量级环境,默认情况下使用合理的默认值确保安全。
- 添加了简单但功能强大的“电池内置”功能,例如:本地存储提供商、服务负载平衡器、Helm 控制器和 Traefik 入口控制器。
- 所有 Kubernetes 控制平面组件的操作都封装在一个二进制和进程中。这允许 K3 自动化和管理复杂的集群操作,如分发证书。
- 外部依赖性已经最小化(只需要一个现代内核和 cgroup 挂载)。K3s 包需要依赖项,包括:
- 集装箱 containerd
- Flannel
- Core DNS
- CNI
- 主机实用程序(iptables、socat 等)
- 入口控制器(traefik)
- 嵌入式服务负载平衡器
- 嵌入式网络策略控制器
您可以在 K3s 官方网站上找到官方 K3s 安装脚本,将其作为服务安装在基于 systemd 或 openrc 的系统上。要使用该方法安装 K3,请运行以下命令:
curl -sfL https://get.k3s.io (opens new window) | sh -
2.在 K3s 上创建集群
- 要在 K3s 上创建 Kubernetes 集群,请使用以下命令:
sudo k3s server &
这将引导 Kubernetes 集群 kubeconfig 写入/etc/rancher/k3s/k3s.yaml。
- (可选)检查群集:
sudo k3s kubectl get node
K3s 将流行的 kubectl 命令直接嵌入到二进制文件中,因此您可以立即通过它与集群交互。
- (可选)在其他节点上运行以下命令。NODE_TOKEN 来自服务器上的/var/lib/rrancher/k3s/server/NODE TOKEN:
- sudo k3s agent --server https://myserver:6443 (opens new window) --token {YOUR_NODE_TOKEN}
Windows Linux 子系统(WSL)上的 K3s
1.在 Windows Subsystem for Linux(WSL)上的 K3s 上设置群集
Windows Subsystem for Linux(WSL)允许开发人员在 GNU/Linux 环境中运行,包括大多数命令行工具、实用程序和应用程序-直接在 Windows 上运行,无需修改,而无需传统虚拟机或 dualbot 设置的开销。
安装 WSL 的完整说明可以在 Windows 官方网站上找到。
以下步骤总结了在 WSL 上设置 WSL 和 K3 所需的内容。
- 按照官方文档安装[WSL]。
- 根据官方说明,更新 WSL 并下载您的首选分发:
- SUSE Linux Enterprise Server 15 SP1
- openSUSE Leap 15.2
- Ubuntu 18.04 LTS
- Debian GNU/Linux
参考:WSL 上的 K3s:快速入门指南^58 (opens new window)
2.在 WSL 上的 K3s 上创建集群
以下是在 WSL 中的 K3s 上创建集群的步骤
要在 WSL 上的 K3s 上创建 Kubernetes 集群,请运行以下命令:
sudo ./k3s server
这将引导 Kubernetes 集群,但您将无法从 Windows 计算机访问集群本身。
注意:您不能使用 curl 脚本安装 K3,因为 WSL 中没有监控器(systemd 或 openrc)。
从下载 K3s 二进制文件https://github.com/rancher/k3s/releases/latest.然后,在下载K3s二进制文件的目录中,运行以下命令以向K3s二进制添加执行权限: (opens new window)
chmod +x k3s
3. 启动 K3s:
sudo ./k3s server
3.设置对 WSL 实例的访问
要设置对 WSL 实例的访问,请执行以下操作:
复制/etc/rancher/k3s/k3s。yaml 从 WSL 到$HOME/.kube/config。
通过更改服务器 URL 编辑复制的文件 https://localhost:6443 (opens new window) 到 WSL 实例的 IP(IP-addr show dev eth0)(例如,https://192.168.170.170:6443.) (opens new window)
在 Windows 终端中运行 kubectl。如果您没有安装 kubectl,请按照 Kubernetes 官方的 Windows 说明进行操作。
K3ai[α]
K3ai 是一种轻量级的“机箱中的基础设施”,专门用于在便携式硬件(如笔记本电脑和边缘设备)上安装和配置 AI 工具和平台。这使得用户能够在本地集群上使用 Kubeflow 进行快速实验。
K3ai 的主要目标是提供一种快速安装 Kubernetes(基于 K3s)和 Kubeflo Pipelines 的方法,支持 NVIDIA GPU 和 TensorFlow Serving。(对于 Kubeflow 和其他组件支持,请查看 K3ai 的网站以获取更新。)要使用 K3ai 安装 Kubeflow Pipelines,请运行以下命令:
仅支持 CPU:
curl -sfL https://get.k3ai.in (opens new window) | bash -s -- --cpu --plugin_kfpipelines
具有 GPU 支持:
curl -sfL https://get.k3ai.in (opens new window) | bash -s -- --gpu --plugin_kfpipelines
有关 K3ai 的更多信息,请参阅官方文档^59 (opens new window)。
部署 Kubeflow 管道
Kubeflo 管道的安装过程对于本指南中涵盖的所有三种环境都是相同的:kind、K3s 和 K3ai。
注意:进程命名空间共享(PNS)在 Argo 中尚未成熟-有关更多信息,请访问 Argo 执行器,并在使用 PNS 时可能遇到的任何问题中引用“PNS 执行器”。
1.要部署 KubeflowPipelines,请运行以下命令:
# env/platform-agnostic-pns hasn't been publically released, so you will install it from master
export PIPELINE_VERSION**=**1.8.5
kubectl apply -k "github.com/kubeflow/pipelines/manifests/kustomize/cluster-scoped-resources?ref=$PIPELINE_VERSION"
kubectl wait --for condition**=established --timeout=**60s crd/applications.app.k8s.io
kubectl apply -k "github.com/kubeflow/pipelines/manifests/kustomize/env/platform-agnostic-pns?ref=$PIPELINE_VERSION"
KubeflowPipelines 的部署可能需要几分钟才能完成。
2.验证端口转发是否可以访问 Kubeflow Pipelines UI:
kubectl port-forward -n kubeflow svc/ml-pipeline-ui 8080:80
然后,在 http://localhost:8080/或者-如果您在虚拟机中使用种类或 (opens new window) K3-http://{YOUR_VM_IP_ADDRESS}:8080/ (opens new window)
请注意,K3ai 将在安装过程结束时自动打印 web UI 的 URL。
注意:kubectl apply-k 接受本地路径和格式化为 hashicorp/go-getter URL 的路径。虽然前面命令中的路径看起来像 URL,但它们不是有效的 URL。
卸载 Kubeflow 管道
以下是在 K3s 或 K3ai 上的移除 Kubeflow 管道的步骤:
- 要使用清单文件卸载 Kubeflow Pipelines,请运行以下命令,将{your_manifest_file}替换为清单文件的名称:
kubectl delete -k {YOUR_MANIFEST_FILE}`
- 要使用 KubeflowPipelines 的 GitHub 存储库中的清单卸载 KubeflowPipelines,请运行以下命令:
export PIPELINE_VERSION**=**1.8.5
kubectl delete -k "github.com/kubeflow/pipelines/manifests/kustomize/env/platform-agnostic-pns?ref=$PIPELINE_VERSION"
kubectl delete -k "github.com/kubeflow/pipelines/manifests/kustomize/cluster-scoped-resources?ref=$PIPELINE_VERSION"
- 要使用本地存储库或文件系统中的清单卸载 Kubeflow Pipelines,请运行以下命令:
kubectl delete -k manifests/kustomize/env/platform-agnostic-pns
kubectl delete -k manifests/kustomize/cluster-scoped-resources
# 3.3.1.4.1.3.独立部署
关于 Kubeflow 管道独立部署的信息
作为部署 Kubeflow Pipelines(KFP)作为 Kubeflow 部署的一部分的替代方案,您还可以选择只部署 Kubeflow Pipelines。按照以下说明使用提供的 kustosize 清单独立部署 Kubeflow Pipelines。
您应该熟悉 Kubernetes、kubectl 和 kustomize。
Kubeflow Pipelines 单机版的安装选项
本指南目前介绍了如何在谷歌云平台(GCP)上独立安装 Kubeflow Pipelines。您还可以在其他平台上独立安装 Kubeflow Pipelines。本指南需要更新。见问题 1253。
3.3.1.4.1.3.1.开始之前
使用 Kubeflow Pipelines Standalone 需要 Kubernetes 集群以及 kubectl 安装。
下载并安装 kubectl
按照 kubectl 安装指南下载并安装 kubectl^60 (opens new window)。
您需要 kubectl 1.14 或更高版本才能支持 kustosize。
设置群集
如果您有一个现有的 Kubernetes 集群,请继续执行配置 kubectl 以与集群通信的说明^61 (opens new window)。
请参阅 GKE 指南,了解如何为 Google 云平台(GCP)创建集群^62 (opens new window)。
使用 gcloud container clusters create^63 (opens new window)命令创建一个可以运行所有 Kubeflow Pipelines 示例的集群:
# The following parameters can be customized based on your needs.
CLUSTER_NAME="kubeflow-pipelines-standalone"
ZONE="us-central1-a"
MACHINE_TYPE="e2-standard-2" # A machine with 2 CPUs and 8GB memory.
SCOPES="cloud-platform" # This scope is needed for running some pipeline samples. Read the warning below for its security implication
gcloud container clusters create $CLUSTER_NAME \
--zone $ZONE \
--machine-type $MACHINE_TYPE \
--scopes $SCOPES
注意:e2-standard-2 不支持 GPU。您可以参考云机器系列中的指南来选择满足您需求的机器类型^64 (opens new window)。
警告:使用 SCOPES="cloud-platform"授予集群所有 GCP 权限。有关更安全的群集设置,请参阅向 GCP 验证管道^65 (opens new window)。
注意,一些遗留的管道示例可能需要少量代码更改才能在 SCOPES="cloud-platform"的集群上运行,请参阅编写管道以使用默认服务帐户^66 (opens new window)。
参考文献:
- GCP 区域和区域文件^67 (opens new window)
- gcloud 命令行工具指南^68 (opens new window)
- gcloud 命令参考^69 (opens new window)
配置 kubectl 以与集群通信
请参阅 Google Kubernetes Engine(GKE)指南,以配置 kubectl 的集群访问^70 (opens new window)。
3.3.1.4.1.3.2.部署 Kubeflow 管道
- 部署 Kubeflow 管道:
export PIPELINE_VERSION=1.8.5
kubectl apply -k "github.com/kubeflow/pipelines/manifests/kustomize/cluster-scoped-resources?ref=$PIPELINE_VERSION"
kubectl wait --for condition=established --timeout=60s crd/applications.app.k8s.io
kubectl apply -k "github.com/kubeflow/pipelines/manifests/kustomize/env/dev?ref=$PIPELINE_VERSION"
Kubeflow Pipelines 部署大约需要 3 分钟才能完成。
注:以上命令适用于 Kubeflow Pipelines 0.4.0 及更高版本。
对于 Kubeflow Pipelines 版本 0.2.0~0.3.0,请使用:
export PIPELINE_VERSION=<kfp-version-between-0.2.0-and-0.3.0>
kubectl apply -k "github.com/kubeflow/pipelines/manifests/kustomize/base/crds?ref=$PIPELINE_VERSION"
kubectl wait --for condition=established --timeout=60s crd/applications.app.k8s.io
kubectl apply -k "github.com/kubeflow/pipelines/manifests/kustomize/env/dev?ref=$PIPELINE_VERSION"
对于 Kubeflow Pipelines 版本<0.2.0,请使用:
export PIPELINE_VERSION=<kfp-version-0.1.x>
kubectl apply -k "github.com/kubeflow/pipelines/manifests/kustomize/env/dev?ref=$PIPELINE_VERSION"
注意:kubectl apply -k 接受本地路径和格式化为 hashicorp/go-getter URL 的路径。虽然前面命令中的路径看起来像 URL,但这些路径不是有效的 URL。
2. 获取 KubeflowPipelines UI 的公共 URL,并使用它访问 Kubeflowpipelines UI:
kubectl describe configmap inverse-proxy-config -n kubeflow | grep googleusercontent.com
3.3.1.4.1.3.3.升级 Kubeflow 管道
1.有关发布通知和中断更改,请参阅升级 Kubeflow 管道^71 (opens new window)。
2.查看 Kubeflow Pipelines GitHub^72 (opens new window)存储库以获取可用版本。
3.要升级到 Kubeflow Pipelines 0.4.0 或更高版本,请使用以下命令:
export PIPELINE_VERSION=<version-you-want-to-upgrade-to>
kubectl apply -k "github.com/kubeflow/pipelines/manifests/kustomize/cluster-scoped-resources?ref=$PIPELINE_VERSION"
kubectl wait --for condition=established --timeout=60s crd/applications.app.k8s.io
kubectl apply -k "github.com/kubeflow/pipelines/manifests/kustomize/env/dev?ref=$PIPELINE_VERSION"
要升级到 Kubeflow Pipelines 0.3.0 或更低版本^73 (opens new window),请使用部署说明升级 Kubeflow pipelines 集群。
4.手动删除过时的资源。
根据您要升级的版本和您要升级到的版本,某些 Kubeflow Pipelines 资源可能已过时。
如果要从 Kubeflow Pipelines<0.4.0 升级到 0.4.0 或更高版本,则可以在升级后删除以下过时资源:元数据部署、元数据服务。
运行以下命令以检查群集上是否存在这些资源:
kubectl -n <KFP_NAMESPACE> get deployments | grep metadata-deployment
kubectl -n <KFP_NAMESPACE> get service | grep metadata-service
如果集群上存在这些资源,请运行以下命令删除它们:
kubectl -n <KFP_NAMESPACE> delete deployment metadata-deployment
kubectl -n <KFP_NAMESPACE> delete service metadata-service
对于其他版本,您无需执行任何操作。
3.3.1.4.1.3.4.自定义 Kubeflow 管道
Kubeflow 管道可通过 kustomize 覆盖层进行配置。
首先,首先克隆 Kubeflow Pipelines GitHub 存储库,并将其用作工作目录。
使用云 SQL 和 Google 云存储在 GCP 上部署
注意:建议用于生产环境。有关为 GCP 定制环境的更多详细信息,请参阅 Kubeflow Pipelines GCP 清单^74 (opens new window)。
更改部署命名空间
要在命名空间< my namespace >中独立部署 Kubeflow Pipelines,请执行以下操作:
1.在 dev/kustomization 中将 namespace 字段设置为< my namespace >。yaml 或 gcp/kustomization.yaml。
2.在集群范围的 resources/kustomization.yaml 中,将 namespace 字段设置为<my namespace>
应用更改以更新 KubeflowPipelines 部署:
kubectl apply -k manifests/kustomize/cluster-scoped-resources
kubectl apply -k manifests/kustomize/env/dev
注意:如果使用 GCP Cloud SQL 和 Google Cloud Storage,请在 manifest/kustomize/env/GCP/params.env 中设置正确的值。然后使用以下命令应用:
kubectl apply -k manifests/kustomize/cluster-scoped-resources
kubectl apply -k manifests/kustomize/env/gcp
禁用公共终结点
默认情况下,KFP 独立部署安装一个公开公共 URL 的反向代理。如果要跳过反向代理的安装,请完成以下操作:
1.注释出基础 kustomization.yaml 中的代理组件。例如 manifest/kustomize/env/dev/kustomization。yaml 注释掉 inverse-proxy。
2.应用更改以更新 Kubeflow Pipelines 部署:
kubectl apply -k manifests/kustomize/env/dev
注意:如果使用 GCP Cloud SQL 和 Google Cloud Storage,请在 manifest/kustomize/env/GCP/params.env 中设置正确的值。然后使用以下命令应用:
kubectl apply -k manifests/kustomize/env/gcp
3.验证端口转发是否可以访问 Kubeflow Pipelines UI:
kubectl port-forward -n kubeflow svc/ml-pipeline-ui 8080:80
4.打开 Kubeflow Pipelines UIhttp://localhost:8080/ (opens new window)
3.3.1.4.1.3.5.卸载 Kubeflow 管道
要卸载 Kubeflow Pipelines,请运行kubectl delete-k < manifest file >。
例如,要使用 GitHub 存储库中的清单卸载 KFP,请运行:
export PIPELINE_VERSION=1.8.5
kubectl delete -k "github.com/kubeflow/pipelines/manifests/kustomize/env/dev?ref=$PIPELINE_VERSION"
kubectl delete -k "github.com/kubeflow/pipelines/manifests/kustomize/cluster-scoped-resources?ref=$PIPELINE_VERSION"
要使用本地存储库或文件系统中的清单卸载 KFP,请运行:
kubectl delete -k manifests/kustomize/env/dev
kubectl delete -k manifests/kustomize/cluster-scoped-resources
**注意:**如果您正在使用 GCP Cloud SQL 和 Google Cloud Storage,请运行:
kubectl delete -k manifests/kustomize/env/gcp
kubectl delete -k manifests/kustomize/cluster-scoped-resources
3.3.1.4.1.3.6.维护清单的最佳实践
与源代码类似,配置文件属于源代码控制。存储库管理对清单文件的更改,并确保您可以重复部署、升级和卸载组件。
在源代码管理中维护清单
创建或自定义部署清单后,将清单保存到本地或远程源代码管理存储库。例如,保存以下 kustomization.yaml:
# kustomization.yaml
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
# Edit the following to change the deployment to your custom namespace.
namespace: kubeflow
# You can add other customizations here using kustomize.
# Edit ref in the following link to deploy a different version of Kubeflow Pipelines.
bases:
- github.com/kubeflow/pipelines/manifests/kustomize/env/dev?ref=1.8.5
3.3.1.4.1.3.6.故障排除
如果您的管道卡在 ContainerCreating 状态,并且它有 pod 事件,如:
MountVolume.SetUp failed for volume "gcp-credentials-user-gcp-sa" : secret "user-gcp-sa" not found
您应该删除 use_gcp_secret 用法,如“向 gcp 验证管道”中所述^75 (opens new window)。
# 3.3.1.4.1.4.选择 Argo 工作流执行器
如何选择 Argo 工作流执行器
Argo 工作流执行器是一个符合特定接口的过程,该接口允许 Argo 执行某些操作,如监视 pod 日志、收集工件、管理容器生命周期等。
Kubeflow Pipelines 作为工作流引擎运行在 Argo Workflows^76 (opens new window)上,因此 KubeflowPipelines 用户需要选择工作流执行器。
3.3.1.4.1.4.1.选择工作流执行器
一些用户可能看重稳定性和向后兼容性。例如,如果您正在生产集群中运行 KubeflowPipelines,或者您维护的生产管道不希望中断或迁移。
在这种情况下,我们建议您使用 docker 执行器,并将 Kubernetes 节点配置为使用 docker 容器运行时。
然而,Kubernetes 反对将 docker 作为容器运行时,因此我们建议开始尝试使用 emissiary,并在其稳定时为迁移做好准备。
对于不太关心稳定性和向后兼容性的用户,我们建议尝试新的使者执行器。
注意,Argo 工作流支持其他工作流执行器,但 Kubeflow Pipelines 团队只建议在 docker 执行器和使者执行器之间进行选择。
Docker 执行器
Docker 执行器是默认的工作流执行器。但 Kubeflow Pipelines v1.8 将切换到 Emissary Executor 作为默认执行器。
- 容器运行时:仅 docker。然而,Kubernetes 在 v1.20 之后反对 Docker 作为容器运行时。在 Google Kubernetes Engine(GKE)1.19+上,容器运行时已经默认为 containerd。
- 可靠性:测试最充分、最流行的 argo 工作流执行器
- 安全性:最不安全
- 它需要对要装载的主机的 docker.sock 进行特权访问。通常被开放政策代理(OPA)或您的 Pod 安全政策(PSP)拒绝。GKE 自动驾驶模式也拒绝它,因为没有特权吊舱。
- 它可以逃脱 pod 服务帐户的特权。
为 Docker Executor 准备 GKE 集群
对于 GKE,节点映像决定使用哪个容器运行时。要使用 docker 容器运行时,需要使用 docker 指定节点映像。
必须使用以下节点映像之一:
- 容器优化操作系统与 Docker(cos)
- Ubuntu 与 Docker(Ubuntu)
如果您的节点没有将 docker 用作容器运行时,那么当您运行管道时,总会发现错误消息,如:
此步骤处于错误状态,并显示以下消息:未能保存输出:后台进程的错误响应:没有这样的容器:XXXXXX
代理执行器
特使执行器是一个新的工作流执行器。它首次发布于 Argo Workflows v3.1(2021 6 月)。然而,Kubeflow Pipelines 团队认为,其架构和可移植性的改进可以使其成为大多数人将来应该使用的默认执行器。
因此,团队承诺积极收集反馈并为特使执行者修复 bug,以便我们更快地稳定它。在代理执行器 github 问题中提交您的反馈^77 (opens new window)。
- 到目前为止,Kubeflow Pipelines 测试基础设施在特使执行者的支持下一直稳定运行。
- 容器运行时:任意
- 可靠性:尚未经过良好测试,也尚未普及,但 Kubeflow Pipelines 团队对此表示支持。
- 安全性:更安全
- 无特权访问。
- 无法逃脱 pod 服务帐户的特权。
- 迁移:命令必须在 Kubeflow Pipelines 组件规范中指定。
注意,Kubeflow Pipelines v2 兼容模式需要相同的迁移要求,请参阅已知的警告和突破性更改。
迁移到代理执行器
前提条件:代理执行器仅在 Kubeflow Pipelines 后端版本 1.7+中可用。若要升级,请参阅升级 Kubeflow Pipelines。
配置现有的 KubeflowPipelines 集群以使用特使执行器
1.安装 kubectl^78 (opens new window)。
2.通过 kubectl 连接到集群。
3.切换到安装了 Kubeflow Pipelines 的命名空间:
kubectl config set-context --current --namespace <your-kfp-namespace>
注意,通常是 Kubeflow 或默认值。
4.确认当前工作流执行者:
kubectl describe configmap workflow-controller-configmap | grep -A 2 containerRuntimeExecutor
使用 docker 执行器时,您将看到如下输出:
containerRuntimeExecutor:
----
docker
5.将工作流执行器配置为特使:
kubectl patch configmap workflow-controller-configmap --patch '{"data":{"containerRuntimeExecutor":"emissary"}}'
6.确认工作流执行器已成功更改:
kubectl describe configmap workflow-controller-configmap | grep -A 2 containerRuntimeExecutor
您将看到如下输出:
containerRuntimeExecutor:
----
emissary
使用特使执行器部署一个新的 Kubeflow Pipelines 集群
对于 AI 平台管道,请在安装期间选中“使用特使执行器”复选框。
对于 Kubeflow Pipelines Standalone,安装 env/平台不可知使者:
kubectl apply -k "github.com/kubeflow/pipelines/manifests/kustomize/env/platform-agnostic-emissary?ref=$PIPELINE_VERSION"
如果有疑问,您可以先部署 Kubeflow Pipelines 集群,并在安装后使用现有集群的说明配置工作流执行器。
迁移管道组件以在委托执行器上运行
某些管道组件需要手动更新才能在授权执行器上运行。对于 Kubeflow Pipelines 组件规范 YAML,必须指定命令字段。
分步组件迁移教程:
- 有一个 hello world 组件:
name: hello-world
implementation:
container:
image: hello-world
2.我们可以在没有命令/args 的情况下运行容器:
\$ docker run hello-world
Hello from Docker!
...
3 查找图像中的默认 ENTRYPOINT 和 CMD:
\$ docker image inspect -f '{{\.Config.Entrypoint}} {{\.Config.Cmd}}' hello-world
[] [/hello]
因此未指定 ENTRYPOINT,CMD 为[“/hello”]。注意,ENTRYPOINT 大致表示命令,CMD 大致表示参数。命令和参数被连接为用户命令。
4.更新组件 YAML:
name: hello-world
implementation:
container:
image: hello-world
command: ["/hello"]
5. 更新的组件现在可以在使者执行器上运行。
注意:Kubeflow Pipelines SDK 编译器总是为基于 python 函数的组件指定一个命令。因此,这些组件将继续在使者执行器上工作,无需修改。
# 3.3.1.4.1.5.兼容性矩阵
Kubeflow Pipelines 与 TensorFlow Extended(TFX)的兼容性矩阵
Kubeflow Pipelines 后端和 TFX 兼容性
在 TensorFlow Extended(TFX)的任何版本中编写的管道都将在 Kubeflow Pipelines(KFP)后端的任何版本上执行。但是,如果 TFX 和 Kubeflow Pipelines 后端版本不兼容,某些 UI 功能可能无法正常运行。
下表显示了 TFX 和 Kubeflow Pipelines 后端版本的 UI 功能兼容性:

详细说明:
1.可视化不兼容:Kubeflow Pipelines UI 和 TFDV、TFMA 可视化不兼容。可视化在 Kubeflow Pipelines UI 中引发错误。
2.元数据 UI 不兼容:Kubeflow Pipelines UI 和 TFX 记录的 ML 元数据不兼容。运行详细信息页面中的 ML 元数据选项卡显示错误消息“未找到对应的 ML 元数据”。因此,基于 ML 元数据的可视化也不会显示在可视化选项卡中。
# 3.3.1.5.Pipelines SDK
# 3.3.1.5.1.Pipelines SDK 简介
使用 SDK 构建组件和管道概述
Kubeflow 组件状态稳定。请参阅 Kubeflow 版本控制策略。
Kubeflow Pipelines SDK 提供了一组 Python 包,您可以使用这些包来指定和运行机器学习(ML)工作流。管道是对 ML 工作流的描述,包括组成工作流步骤的所有组件以及组件之间的交互方式。
注意:这里的 SDK 文档是指默认的 Kubeflow Pipelines with Argo^79 (opens new window)。如果您使用 Tekton 运行 Kubeflow Pipelines^80 (opens new window),请遵循 Kubeflow Pipelines SDK for Tekton^81 (opens new window)文档。
3.3.1.5.1.1.SDK 包
Kubeflow Pipelines SDK 包括以下包:
- Kfp.compiler 包含用于将管道 Python DSL 编译为工作流 yaml 规范的类和方法。此包中的方法包括但不限于以下内容:
- kfpcompiler.compiler.compile 将 Python DSL 代码编译为一个静态配置(YAML 格式),Kubeflow Pipelines 服务可以处理该配置。Kubeflow Pipelines 服务将静态配置转换为一组 Kubernetes 资源以供执行。
- kfp.components 包括用于与管道组件交互的类和方法。本包中的方法包括但不限于以下内容:
- kfp.components.func_to_container_op 将 Python 函数转换为管道组件并返回工厂函数。然后可以调用工厂函数来构造管道任务(ContainerOp)的实例,该任务在容器中运行原始函数。
- kfp.components.load_component_from_file 从文件加载管道组件并返回工厂函数。然后,您可以调用工厂函数来构造运行组件容器映像的管道任务(ContainerOp)的实例。
- kfp.components.load_component_from_url 从 url 加载管道组件并返回工厂函数。然后,您可以调用工厂函数来构造运行组件容器映像的管道任务(ContainerOp)的实例。
- kfp.dsl 包含域特定语言(dsl),您可以使用它来定义管道和组件并与之交互。此包中的方法、类和模块包括但不限于以下内容:
- kfp.dls.PipelineParam 表示可以从一个管道组件传递到另一个管道的管道参数。请参见管道参数指南。
- kfp.dls.component 是 dsl 函数的装饰器,它返回一个管道组件。(集装箱操作)。
- kfp.dsl.pipeline 是 Python 函数的装饰器,它返回一个管道。
- kfp.dsl.python_component 是 python 函数的装饰器,它将管道组件元数据添加到函数对象中。
- kfp.dls.types 包含 Kubeflow Pipelines SDK 定义的类型列表。类型包括基本类型,如 String、Integer、Float 和 Bool,以及特定于域的类型,如 GCPProjectID 和 GCRPath。请参阅 DSL 静态类型检查指南。
- kfp.ds.ResourceOp 表示一个管道任务(op),它允许您直接操作 Kubernetes 资源(创建、获取、应用…)。
- kfp.dls.VolumeOp 表示创建新的 Persistent Volume Claim(PVC)的管道任务(op)。它的目的是使创建 Persistent Volume Claim 的常见情况变得更快。
- kfp.ds.VolumeSnapshotOp 表示创建新 Volume Snapshot 的管道任务(op)。它旨在使创建 Volume Snapshot 的常见情况变得快速。
- kfp.dds.PipelineVolume 表示用于在管道步骤之间传递数据的卷。ContainerOps 可以通过构造函数的参数 pvolumes 或 add_pvolumes()方法装载 PipelineVolume。
- kfp.ds.ParallelFor 表示管道中静态或动态项集上的并行 for 循环。for 循环的每个迭代都是并行执行的。
- kfp.dsl.ExitHandler 表示退出管道时调用的退出处理程序。ExitHandler 的典型用法是垃圾收集。
- kfp.ddsl.Condition 表示一组操作,只有在满足特定条件时才会执行。需要在运行时通过在布尔表达式中至少包含一个任务输出或 Pipeline Param 来确定指定的条件。
- kfp.Client 包含 Kubeflow Pipelines API 的 Python 客户端库。本包中的方法包括但不限于以下内容:
- kfp.Client.create_experiment 创建一个管道实验并返回一个实验对象。
- kfp.Client.run_pipeline 运行管道并返回运行对象。
- kfp.Client.create_run_from_pipeline_func 编译一个管道函数,并将其提交给 Kubeflow Pipelines 执行。
- kfp.Client.create_run_from_pipeline_package 在 Kubeflow Pipelines 上运行本地管道包。
- kfp.Client.upload_pipeline 上载一个本地文件,以在 Kubeflow Pipelines 中创建一个新管道。
- kfp.Client.upload_pipeline_version 上载本地文件以创建管道版本。通过示例了解有关创建管道版本的更多信息。
- Kubeflow Pipelines 扩展模块^82 (opens new window)包括用于特定平台的类和函数,您可以在这些平台上使用 Kubeflow Pipelines。示例包括本地、Google 云平台(GCP)、Amazon Web Services(AWS)和 Microsoft Azure 的实用程序功能。
- Kubeflow Pipelines diagnose_me 模块^83 (opens new window)包括帮助执行环境诊断任务的类和函数。
- kfp.li.diagnos_me.dev_env 报告开发环境中的诊断元数据,例如 python 库版本。
- kfp.li.diagnose_me.kubenetes_cluster 报告来自 kubernetes 集群的诊断数据,例如 Kubernetes secrets。
- kfp.li.diagnose_me.gcp 报告与 gcp 环境相关的诊断数据。
3.3.1.5.1.2.Kubeflow Pipelines CLI 工具
Kubeflow Pipelines CLI 工具使您能够直接从命令行使用 Kubeflow Pipelines SDK 的一个子集。Kubeflow Pipelines CLI 工具提供以下命令:
kfp diagnose_me 使用指定的参数运行环境诊断。
- --json -表示此命令必须以 json 形式返回结果。否则,结果将以可读格式返回。
- --namespace TEXT-指定要使用的 Kubernetes 命名空间。所有名称空间都是默认值。
- --project-id TEXT-对于 GCP 部署,此值指定要使用的 GCP 项目。如果未指定此值,则使用环境默认值。
kfp pipeline <COMMAND>提供以下命令来帮助您管理管道。
- get -从 Kubeflow Pipelines 集群获取有关 Kubeflow pipeline 的详细信息。
- list -列出已上载到 Kubeflow Pipelines 集群的管道。
- upload -将管道上传到 Kubeflow Pipelines 集群。
kfp run <COMMAND>提供以下命令来帮助您管理管道运行。
- get -显示管道运行的详细信息。
- list -列出最近的管道运行。
- submit -提交管道运行。
kfp--endpoint<endpoint>-指定 Kubeflow Pipelines CLI 应连接到的端点。
3.3.1.5.1.3.安装开发工具包
遵循安装 Kubeflow Pipelines SDK 的指南^84 (opens new window)。
3.3.1.5.1.4.建筑管道和组件
本节总结了使用 SDK 构建管道和组件的方法。
Kubeflow 管道是 ML 工作流的可移植和可扩展的定义。ML 工作流中的每个步骤,例如准备数据或训练模型,都是管道组件的实例。
了解有关构建管道的更多信息^85 (opens new window)。
管道组件是一组自包含的代码,在 ML 工作流中执行一个步骤。组件在组件规范中定义,该规范定义了以下内容:
- 组件的接口、输入和输出。
- 组件的实现、容器映像和要执行的命令。
- 组件的元数据,例如组件的名称和描述。
使用以下选项创建或重用管道组件。
- 您可以通过为容器化应用程序定义组件规范来构建组件。了解有关构建管道组件的详细信息^86 (opens new window)。
- 基于 Python 函数的轻量级组件通过使用 Kubeflow Pipelines SDK 生成 Python 函数的组件规范,可以更容易地构建组件。了解如何构建基于 Python 函数的组件。
- 您可以在管道中重用预构建的组件。了解有关重用预构建组件的更多信息。
3.3.1.5.1.5.安装 Kubeflow Pipelines SDK
设置 Kubeflow Pipelines 开发环境
本指南告诉您如何安装 Kubeflow Pipelines SDK^87 (opens new window),您可以使用它来构建机器学习管道。您可以使用 SDK 来执行管道,也可以将管道上传到 Kubeflow Pipelines UI 以执行。
自动生成的 SDK 参考文档中描述了 SDK 的所有类和方法^88 (opens new window)。
注意:如果您使用 Tekton 运行 Kubeflow Pipelines,而不是使用 Argo 运行默认的 Kubeflow Pipelines,则应使用 Tekton 的 Kubeflow Pipelines SDK。
设置 Python
您需要 Python 3.5 或更高版本才能使用 Kubeflow Pipelines SDK。本指南使用 Python 3.7。
如果您还没有设置 Python3 环境,请立即设置。本指南推荐 Miniconda,但您可以使用自己选择的虚拟环境管理器,例如virtualenv。
按照以下步骤使用 Miniconda 设置 Python:
1.根据您的环境,选择以下方法之一安装 Miniconda:
- Debian/Uubuntu/Cloud Shell:
apt-get update**;** apt-get install -y wget bzip2
wget https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh (opens new window)
bash Miniconda3-latest-Linux-x86_64.sh
- Windows:下载安装程序,并确保在安装过程中选择了将 Miniconda 添加到 PATH 环境变量的选项。
- MacOS:下载安装程序并运行以下命令:
bash Miniconda3-latest-MacOSX-x86_64.sh
- 检查 conda 命令是否可用:
which conda
如果找不到 conda 命令,请将 Miniconda 添加到路径中:
export PATH**=**<YOUR_MINICONDA_PATH>/bin:$PATH
3.使用您选择的名称创建一个干净的 Python 3 环境。此示例使用 Python 3.7 和环境名 mlpipeline。:
conda create --name mlpipeline python**=**3.7
conda activate mlpipeline
安装 Kubeflow Pipelines SDK
运行以下命令以安装 Kubeflow Pipelines SDK:
pip3 install kfp --upgrade
注意:如果在安装 Kubeflow Pipelines SDK 时未使用虚拟环境(如 conda),则可能会收到以下错误:
ERROR: Could not install packages due to an EnvironmentError: [Errno 13] Permission denied: '/usr/local/lib/python3.5/dist-packages/kfp-<version>.dist-info'
Consider using the `--user` option or check the permissions.
如果出现此错误,请使用--user 选项安装 kfp:
pip3 install kfp --upgrade --user
该命令将 dsl compile 和 kfp 二进制文件安装在~/.local/bin 下,这在某些 Linux 发行版(如 Ubuntu)中不是 PATH 的一部分。您可以将~/.local/bin 添加到 PATH 中,方法是在.bashrc 文件末尾的新行中附加以下内容:
export PATH**=**$PATH:~/.local/bin
成功安装后,命令 dsl compile 应该可用。您可以使用此命令验证它:
which dsl-compile
答案应该是这样的:
pip3 install kfp --upgrade --user
该命令将 dsl compile 和 kfp 二进制文件安装在~/.local/bin 下,这在某些 Linux 发行版(如 Ubuntu)中不是 PATH 的一部分。您可以将~/.local/bin 添加到 PATH 中,方法是在.bashrc 文件末尾的新行中附加以下内容:
export PATH**=**$PATH:~/.local/bin
成功安装后,命令 dsl compile 应该可用。您可以使用此命令验证它:
which dsl-compile
答案应该是这样的:
/<PATH_TO_YOUR_USER_BIN>/miniconda3/envs/mlpipeline/bin/dsl-compile
3.3.1.5.1.6.将 Pipelines SDK 连接到 Kubeflow Pipelines
如何以各种方式将 Pipelines SDK 连接到 Kubeflow Pipelines
如何将 Pipelines SDK 连接到 Kubeflow Pipelines 将取决于您的 Kubeflow 部署类型以及从何处运行代码。
- 完全 Kubeflow(来自集群内部)^89 (opens new window)
- 完全 Kubeflow(来自集群外部)^90 (opens new window)
- 独立的 Kubeflow 管道(来自集群内部)^91 (opens new window)
- 独立 Kubeflow 管道(来自集群外部)^92 (opens new window)
3.3.1.5.1.7.构建管道(Pipeline)
关于构建管道以协调 ML 工作流的教程
 在 Google Colab 中运行
在 Google Colab 中运行  在 GitHub 上查看源代码
在 GitHub 上查看源代码
Kubeflow 管道是机器学习(ML)工作流的可移植和可扩展的定义。ML 工作流中的每个步骤,例如准备数据或训练模型,都是管道组件的实例。本文档提供了管道概念和最佳实践的概述,以及描述如何构建 ML 管道的说明。
开始之前
1.运行以下命令以安装 Kubeflow Pipelines SDK。如果在 Jupyter 笔记本中运行此命令,请在安装 SDK 后重新启动内核。
$ pip install kfp **--**upgrade
2.导入 kfp 和 kfp.components 包。
import kfp
import kfp.components as comp
理解管道
Kubeflow 管道是基于容器的 ML 工作流的可移植和可扩展的定义。管道由一组输入参数和此工作流中的步骤列表组成。管道中的每个步骤都是一个组件的实例,该组件表示为 ContainerOp 的实例。
您可以使用管道:
- 协调可重复的 ML 工作流。
- 通过使用不同的超参数集运行工作流来加速实验。
了解管道组件
管道组件是一个容器化应用程序,它执行管道工作流中的一个步骤。管道组件在组件规范中定义,其中定义了以下内容:
- 组件的接口、输入和输出。
- 组件的实现、容器映像和要执行的命令。
- 组件的元数据,例如组件的名称和描述。
您可以通过为容器化应用程序定义组件规范来构建组件,也可以使用 Kubeflow Pipelines SDK 为 Python 函数生成组件规范。您还可以重用管道中的预构建组件。
了解管道图
管道的工作流中的每个步骤都是组件的实例。定义管道时,指定每个步骤的输入源。可以从管道的输入参数、常量或步骤输入中设置步骤输入。步骤输入可以取决于此管道中其他步骤的输出。Kubeflow Pipelines 使用这些依赖关系将管道的工作流定义为图形。
例如,考虑具有以下步骤的管道:接收数据、生成统计信息、预处理数据和训练模型。以下描述了每个步骤之间的数据依赖关系。
- **摄取数据:**此步骤从使用管道参数指定的外部源加载数据,并输出数据集。由于此步骤不依赖于任何其他步骤的输出,因此可以先运行此步骤。
- **生成统计信息:**此步骤使用摄取的数据集生成并输出一组统计信息。由于此步骤取决于摄取数据步骤生成的数据集,因此它必须在摄取数据步骤之后运行。
- **预处理数据:**此步骤对摄取的数据集进行预处理,并将数据转换为预处理的数据集。由于此步骤取决于摄取数据步骤生成的数据集,因此它必须在摄取数据步骤之后运行。
- **训练模型:**此步骤使用预处理的数据集、生成的统计数据和管道参数(如学习率)训练模型。由于此步骤依赖于预处理数据和生成的统计信息,因此它必须在预处理数据与生成统计信息步骤完成后运行。
由于生成统计数据和预处理数据步骤都依赖于摄取的数据,因此生成统计数据与预处理数据的步骤可以并行运行。一旦数据依赖性可用,则执行所有其他步骤。
设计您的管道
在设计管道时,请考虑如何将 ML 工作流拆分为管道组件。将 ML 工作流拆分为管道组件的过程类似于将单片脚本拆分为可测试函数的过程。以下规则可以帮助您定义构建管道所需的组件。
- 组件应具有单一责任。拥有一个单一的职责可以更容易地测试和重用组件。例如,如果您有一个加载数据的组件,则可以将其用于加载数据的类似任务。如果您有一个加载和转换数据集的组件,那么该组件可能不太有用,因为您只能在需要加载和转换该数据集时使用它。
- 尽可能重复使用组件。Kubeflow Pipelines 为常见的管道任务和访问云服务提供组件。
- 考虑调试管道所需的知识,并研究管道生成的模型的谱系。Kubeflow Pipelines 存储每个管道步骤的输入和输出。通过询问管道运行产生的工件,您可以更好地了解运行之间模型质量的变化,或者跟踪工作流中的错误。
通常,您应该在设计组件时考虑到可组合性。
管道由组件实例(也称为步骤)组成。步骤可以根据另一步骤的输出定义其输入。步骤之间的依赖关系定义了管道工作流图。
建筑管道组件
Kubeflow 管道组件是容器化的应用程序,在 ML 工作流中执行一个步骤。以下是定义管道组件的方法:
如果您有一个要用作管道组件的容器化应用程序,请创建一个组件规范,将此容器映像定义为管道组件。
该选项提供了在管道中包含任何语言编写的代码的灵活性,只要您可以将应用程序打包为容器映像即可。了解有关构建管道组件的详细信息^93 (opens new window)。
如果组件代码可以表示为 Python 函数,请评估组件是否可以构建为基于 Python 函数^94 (opens new window)的组件。Kubeflow Pipelines SDK 通过节省创建组件规范的工作量,使构建基于 Python 函数的轻量级组件变得更加容易。
尽可能重用预构建的组件^95 (opens new window),以节省构建自定义组件的工作量。
本指南中的示例演示了如何构建使用基于 Python 函数的组件并重用预构建组件的管道。
了解数据如何在组件之间传递
当 Kubeflow Pipelines 运行组件时,在 Kubernetes Pod 中启动容器映像,并将组件的输入作为命令行参数传入。组件完成后,组件的输出将作为文件返回。
在组件的规范中,您定义了组件输入和输出,以及如何将输入和输出路径作为命令行参数传递给程序。您可以按值将小输入(如短字符串或数字)传递给组件。大型输入(如数据集)必须作为文件路径传递给组件。输出被写入 Kubeflow Pipelines 提供的路径。
基于 Python 函数的组件通过为您构建组件规范,可以更容易地构建管道组件。基于 Python 函数的组件还处理将输入传递到组件以及将函数的输出传递回管道的复杂性。
了解有关基于 Python 函数的组件如何处理输入和输出的更多信息。
开始构建管道
以下部分演示如何通过将 Python 脚本转换为管道的过程开始构建 Kubeflow 管道。
设计您的管道
以下步骤将介绍设计管道时可能面临的一些设计决策。
- 评估流程。在下面的示例中,Python 函数从公共网站下载包含多个 CSV 文件的压缩 tar 文件(.tar.gz)。该函数提取 CSV 文件,然后将其合并为单个文件。
import glob
import pandas as pd
import tarfile
import urllib.request
def download_and_merge_csv**(url😗* str**,** output_csv**😗* str**)😗*
with urllib**.request.urlopen(url)** as res**😗*
tarfile**.open(fileobj=res,** mode**="r|gz").extractall('data')**
df = pd**.concat(**
[pd.read_csv(csv_file, header**=None)**
for csv_file in glob**.glob('data/*.csv')])**
df**.to_csv(output_csv,** index**=False,** header**=False)**
- 运行以下 Python 命令来测试函数。
download_and_merge_csv**(**
url**='https://storage.googleapis.com/ml-pipeline-playground/iris-csv-files.tar.gz',**
output_csv**='merged_data.csv')**
- 运行以下命令打印合并 CSV 文件的前几行。
$ head merged_data**.**csv
4.设计您的管道。例如,考虑以下管道设计。
使用一个步骤实现管道。在这种情况下,管道包含一个与示例函数类似的组件。这是一个简单的函数,在这种情况下,实现单步管道是一种合理的方法。
这种方法的缺点是,压缩的 tar 文件不会成为管道运行的工件。没有可用的工件可能会使在生产中调试该组件更加困难。
将其实现为两步管道。第一步是从网站下载文件。第二步从压缩的 tar 文件中提取 CSV 文件,并将其合并为单个文件。
这种方法有几个好处:
- 您可以重用 Web 下载组件来实现第一步。
- 每个步骤都有一个单独的责任,这使得组件更易于重用。
- 压缩的 tar 文件是第一个管道步骤的产物。这意味着您可以在调试使用此组件的管道时检查此工件。
此示例实现了两步管道。
构建管道组件
1.构建管道组件。此示例修改初始脚本以提取压缩的 tar 文件的内容,合并压缩的 tar 中包含的 CSV 文件,并返回合并的 CSV 文件。
本示例构建了一个基于 Python 函数的组件。您还可以将组件的代码打包为 Docker 容器映像,并使用 ComponentSpec 定义组件。
在这种情况下,需要对原始功能进行以下修改。
- 文件下载逻辑已删除。压缩 tar 文件的路径作为参数传递给此函数。
- 导入语句在函数内部移动。基于 Python 函数的组件需要独立的 Python 函数。这意味着必须在函数中定义任何必需的导入语句,并且必须在函数内定义任何助手函数。了解有关构建基于 Python 函数的组件的更多信息。
- 函数的参数用 kfp.components.InputPath 和 kfp.conents.OutputPath 注释修饰。这些注释让 Kubeflow Pipelines 知道如何提供压缩的 tar 文件的路径,并在函数存储合并的 CSV 文件时创建路径。
以下示例显示了更新的 merge_csv 函数。
def merge_csv**(file_path😗* comp**.InputPath('Tarball'),**
output_csv**😗* comp**.OutputPath('CSV'))😗*
import glob
import pandas as pd
import tarfile
tarfile**.open(name=file_path,** mode**="r|gz").extractall('data')**
df = pd**.concat(**
[pd.read_csv(csv_file, header**=None)**
for csv_file in glob**.glob('data/*.csv')])**
df**.to_csv(output_csv,** index**=False,** header**=False)**
2.使用 kfp.components.create_component_from_func 返回可用于创建管道步骤的工厂函数。此示例还指定了运行此函数的基本容器映像、保存组件规范的路径以及运行时需要安装在容器中的 PyPI 包列表。
create_step_merge_csv = kfp**.components.create_component_from_func(**
func**=merge_csv,**
output*component_file**='component.yaml',***# This is optional. It saves the component spec for future use._
base_image**='python:3.7',**
packages_to_install**=['pandas==1.1.4'])**
构建您的管道
1.使用 kfp.components.load_component_from_url 为您在此管道中重用的任何组件加载组件规范 YAML。
web_downloader_op = kfp**.components.load_component_from_url('https://raw.githubusercontent.com/kubeflow/pipelines/master/components/contrib/web/Download/component.yaml')**
2.将管道定义为 Python 函数。
管道函数的参数定义了管道的参数。使用管道参数来实验不同的超参数,例如用于训练模型的学习速率,或者将运行级输入(例如输入文件的路径)传递到管道运行中。
使用 kf.components.create_component_from_func 和 kf.components.load_component.from_url 创建的工厂函数创建管道任务。组件工厂函数的输入可以是管道参数、其他任务的输出或常量值。在本例中,web_downloader_task 任务使用 url 管道参数,merge_csv_task 使用 web_downloader_task 的数据输出。
# Define a pipeline and create a task from a component:
def my_pipeline**(url)😗*
web_downloader_task = web_downloader_op**(url=url)**
merge_csv_task = create_step_merge_csv**(file=web_downloader_task.outputs['data'])**
# The outputs of the merge_csv_task can be referenced using the
# merge_csv_task.outputs dictionary: merge_csv_task.outputs['output_csv']
编译并运行管道
如前一节所述,在 Python 中定义管道后,使用以下选项之一编译管道并将其提交给 KubeflowPipelines 服务。
选项 1:编译,然后在 UI 中上传
1.运行以下命令编译管道并将其保存为 pipeline.yaml。
kfp**.compiler.Compiler().compile(**
pipeline_func**=my_pipeline,**
package_path**='pipeline.yaml')**
2.使用 Kubeflow Pipelines 用户界面上传并运行 pipeline.yaml。请参阅 UI 入门指南。
选项 2:使用 Kubeflow Pipelines SDK 客户端运行管道
1.按照使用 SDK 客户端连接到 Kubeflow Pipelines 的步骤,创建一个 kfp.Client 类的实例。
client = kfp**.Client()** # change arguments accordingly
2 使用 kfp.Client 实例运行管道:
client**.create_run_from_pipeline_func(**
my_pipeline**,**
arguments**={**
'url': 'https://storage.googleapis.com/ml-pipeline-playground/iris-csv-files.tar.gz'
})
3.3.1.5.1.8.建筑构件
关于如何创建组件并在管道中使用它们的教程
管道组件是一组自包含的代码,在 ML 工作流中执行一个步骤。本文档描述了构建组件所需的概念,并演示了如何开始构建组件。
开始之前
运行以下命令以安装 Kubeflow Pipelines SDK。
$ pip3 install kfp **--**upgrade
有关 Kubeflow Pipelines SDK 的更多信息,请参阅 SDK 参考指南。
了解管道组件
管道组件是自包含的代码集,在 ML 工作流中执行一个步骤,例如预处理数据或训练模型。要创建组件,必须构建组件的实现并定义组件规范。
组件的实现包括组件的可执行代码和代码运行的 Docker 容器映像。了解有关设计管道组件的更多信息^96 (opens new window)。
一旦构建了组件的实现,就可以将组件的接口定义为组件规范。组件规范定义了:
- 组件的输入和输出。
- 组件代码运行的容器映像、用于运行组件代码的命令以及传递给组件代码的行参数。
- 组件的元数据,如名称和描述。
了解有关创建组件规范的更多信息^97 (opens new window)。
如果组件的代码实现为 Python 函数,请使用 Kubeflow Pipelines SDK 将函数打包为组件。了解有关构建基于 Python 函数的组件的更多信息。
设计管道组件
当 Kubeflow Pipelines 执行组件时,在 Kubernetes Pod 中启动容器映像,并将组件的输入作为命令行参数传入。您可以按值传递小输入,例如字符串和数字。较大的输入(如 CSV 数据)必须作为文件路径传递。组件完成后,组件的输出将作为文件返回。
设计组件代码时,请考虑以下事项:
- 哪些输入可以按值传递给组件?可以通过值传递的输入示例包括数字、布尔值和短字符串。任何可以作为命令行参数合理传递的值都可以按值传递给组件。所有其他输入都通过对输入路径的引用传递给组件。
- 要从组件返回输出,输出的数据必须存储为文件。当您定义组件时,您可以让 Kubeflow Pipelines 知道组件产生的输出。当管道运行时,Kubeflow Pipelines 会传递用于将组件输出存储为组件输入的路径。
- 输出通常写入单个文件。在某些情况下,您可能需要返回文件目录作为输出。在这种情况下,在输出路径上创建一个目录,并将输出文件写入该位置。在这两种情况下,如果父目录不存在,则可能需要创建父目录。
- 组件的目标可能是在外部服务(如 BigQuery 表)中创建数据集。在这种情况下,组件输出生成数据的标识符(例如表名)而不是数据本身可能是有意义的。我们建议您将此模式限制在数据必须放入外部系统的情况下,而不是将其保存在 Kubeflow Pipelines 系统中。
- 由于输入和输出路径是作为命令行参数传入的,因此组件的代码必须能够从命令行读取输入。如果您的组件是用 Python 构建的,那么 argparse 和 absl.flags 等库可以更容易地读取组件的输入。
- 组件的代码可以用任何语言实现,只要它可以在容器映像中运行即可。
以下是使用 Python3 编写的示例程序。该程序从输入文件中读取给定数量的行,并将这些行写入输出文件。这意味着该函数接受三个命令行参数:
- 输入文件的路径。
- 要读取的行数。
- 输出文件的路径。
#!/usr/bin/env python3
import argparse
from pathlib import Path
# Function doing the actual work (Outputs first N lines from a text file)
def do_work**(input1_file,** output1_file**,** param1**)😗*
for x**,** line in enumerate**(input1_file)😗*
if x >= param1**😗*
break
_ = output1_file**.write(line)**
# Defining and parsing the command-line arguments
parser = argparse**.ArgumentParser(description='My program description')**
# Paths must be passed in, not hardcoded
parser**.add_argument('--input1-path',** type**=str,**
help**='Path of the local file containing the Input 1 data.')**
parser**.add_argument('--output1-path',** type**=str,**
help**='Path of the local file where the Output 1 data should be written.')**
parser**.add_argument('--param1',** type**=int,** default**=100,**
help**='The number of lines to read from the input and write to the output.')**
args = parser**.parse_args()**
# Creating the directory where the output file is created (the directory
# may or may not exist).
Path**(args.output1_path).parent.mkdir(parents=True,** exist_ok**=True)**
with open**(args.input1_path,** 'r') as input1_file**😗*
with open**(args.output1_path,** 'w') as output1_file**😗*
do_work**(input1_file,** output1_file**,** args**.param1)**
如果此程序保存为 program.py,则此程序的命令行调用为:
python3 program.py --input1-path <path-to-the-input-file> \
--param1 <number-of-lines-to-read> \
--output1-path <path-to-write-the-output-to>
包含组件的代码
为了让 KubeflowPipelines 运行您的组件,您的组件必须打包为 Docker 容器映像,并发布到 Kubernetes 集群可以访问的容器注册表中。创建容器图像的步骤并不特定于 Kubeflow Pipelines。为了方便您,本节提供了一些标准容器创建指南。
1.为容器创建 Dockerfile^98 (opens new window)。Dockerfile 指定:
- 基本容器图像。例如,代码运行的操作系统。
- 运行代码需要安装的任何依赖项。
- 要复制到容器中的文件,例如此组件的可运行代码。
以下是 Dockerfile 示例。
FROM python:3.7
RUN python3 -m pip install keras
COPY ./src /pipelines/component/src
在此示例中:
基本容器图像是 python:3.7。
keras Python 包安装在容器映像中。
中的文件/src 目录被复制到容器图像中的/pipeines/component/src 中。
2.创建一个名为 build_image.sh 的脚本,该脚本使用 Docker 构建容器映像并将容器映像推送到容器注册表。Kubernetes 集群必须能够访问容器注册表以运行组件。容器注册表的示例包括 Google container Registry^99 (opens new window)和 Docker Hub^100 (opens new window)。
以下示例构建容器映像,将其推送到容器注册表,并输出严格的映像名称。最好的做法是在组件规范中使用严格的映像名称,以确保在每个组件执行中使用预期版本的容器映像。
#!/bin/bash -e
image_name**=**gcr.io/my-org/my-image
image_tag**=**latest
full_image_name**=**${image_name}😒{image_tag}
cd "$(dirname "$0")"
docker build -t "${full_image_name}" .
docker push "$full_image_name"
# Output the strict image name, which contains the sha256 image digest
docker inspect --format**=**"{{index .RepoDigests 0}}" "\${full_image_name}"
在前面的示例中:
- image_name 指定容器注册表中容器映像的全名。
- image_tag 指定此图像应标记为最新。
保存此文件并运行以下命令以使此脚本可执行。
chmod +x build_image.sh
3.运行 build_image.sh 脚本来构建容器映像并将其推送到容器注册表。
4.使用 docker run 在本地测试容器映像。如果需要,请修改应用程序和 Dockerfile,直到应用程序在容器中按预期工作。
3.3.1.5.1.9.创建组件规范
要从容器化程序创建组件,必须创建定义组件接口和实现的组件规范。以下部分通过演示如何定义组件的实现、接口和元数据,概述了如何创建组件规范。
要了解有关定义组件规范的更多信息,请参阅组件规范参考指南。
定义组件的实现
以下示例创建了组件规范 YAML 并定义了组件的实现。
1.创建一个名为 component.yaml 的文件,并在文本编辑器中打开它。
2.创建组件的实现部分并指定容器映像的严格名称。运行 build_image.sh 脚本时会提供严格的图像名称。
implementation:
container:
# The strict name of a container image that you've pushed to a container registry.
image: gcr.io/my-org/my-image@sha256:a172..752f
3.为组件的实现定义命令。此字段指定用于在容器中运行程序的命令行参数。
implementation:
container:
image: gcr.io/my-org/my-image@sha256:a172..752f
# command is a list of strings (command-line arguments).
# The YAML language has two syntaxes for lists and you can use either of them.
# Here we use the "flow syntax" - comma-separated strings inside square brackets.
command: [
python3,
# Path of the program inside the container
/pipelines/component/src/program.py,
--input1-path,
{inputPath: Input 1},
--param1,
{inputValue: Parameter 1},
--output1-path,
{outputPath: Output 1},
]
命令格式为字符串列表。命令中的每个字符串都是命令行参数或占位符。在运行时,占位符被输入或输出替换。在前面的示例中,两个输入和一个输出路径被传递到位于/pipeines/component/src/proprogram.py 的 Python 脚本中。
有三种类型的输入/输出占位符:
- {inputValue: <input-name>}:此占位符将替换为指定输入的值。这对于小的输入数据(如数字或小字符串)非常有用。
- {inputPath: <input-name>}:此占位符被替换为此输入的文件路径。组件可以在管道运行期间读取该路径上的输入内容。
- {outputPath: <output-name>}:此占位符被替换为程序写入此输出数据的路径。这使 KubeflowPipelines 系统能够读取文件的内容,并将其存储为指定输出的值。
<input-name>名称必须与组件规范的 inputs 部分中的输入名称匹配。<output-name>名称必须与组件规范的输出部分中的 outputs 名称匹配。
定义组件的界面
以下示例演示如何指定组件的接口。
1.要在 component.yaml 中定义输入,请向输入列表中添加具有以下属性的项:
- name:此输入的可读名称。每个输入的名称必须唯一。
- description:(可选。)输入的可读描述。
- default:(可选。)指定此输入的默认值。
- type:(可选。)指定输入的类型。了解有关 Kubeflow Pipelines SDK 中定义的类型以及类型检查如何在管道和组件中工作的更多信息。
- optional:指定此输入是否可选。该属性的值为 Bool 类型,默认为 False。
在此示例中,Python 程序有两个输入:
- Input 1 包含字符串数据。
- Parameter 1 包含整数。
inputs:
- {name: Input 1, type: String, description: 'Data for input 1'}
- {name: Parameter 1, type: Integer, default: '100', description: 'Number of lines to copy'}
注意:输入 1 和参数 1 没有指定有关它们如何存储或包含多少数据的任何详细信息。考虑使用命名约定来指示输入是否足够小以传递值。
2.组件完成任务后,组件的输出将作为路径传递到管道。在运行时,Kubeflow Pipelines 为每个组件的输出创建一个路径。这些路径作为输入传递给组件的实现。
要在组件规范 YAML 中定义输出,请向输出列表中添加具有以下属性的项:
- name:此输出的可读名称。每个输出的名称必须唯一。
- description:(可选。)输出的可读描述。
- type:(可选。)指定输出的类型。了解有关 Kubeflow Pipelines SDK 中定义的类型以及类型检查如何在管道和组件中工作的更多信息。
在本例中,Python 程序返回一个输出。输出名为 output 1,它包含字符串数据。
outputs:
- {name: Output 1, type: String, description: 'Output 1 data.'}
注意:考虑使用命名约定来指示此输出是否足够小以传递值。每次管道运行时,应将按值传递的数据量限制为 200KB。
3.定义组件的接口后,component.yaml 应该如下所示:
inputs:
- {name: Input 1, type: String, description: 'Data for input 1'}
- {name: Parameter 1, type: Integer, default: '100', description: 'Number of lines to copy'}
outputs:
- {name: Output 1, type: String, description: 'Output 1 data.'}
implementation:
container:
image: gcr.io/my-org/my-image@sha256:a172..752f
# command is a list of strings (command-line arguments).
# The YAML language has two syntaxes for lists and you can use either of them.
# Here we use the "flow syntax" - comma-separated strings inside square brackets.
command: [
python3,
# Path of the program inside the container
/pipelines/component/src/program.py,
--input1-path,
{inputPath: Input 1},
--param1,
{inputValue: Parameter 1},
--output1-path,
{outputPath: Output 1},
]
指定组件的元数据
要定义组件的元数据,请将名称和描述字段添加到 component.yaml 中
name: Get Lines
description: Gets the specified number of lines from the input file.
inputs:
- {name: Input 1, type: String, description: 'Data for input 1'}
- {name: Parameter 1, type: Integer, default: '100', description: 'Number of lines to copy'}
outputs:
- {name: Output 1, type: String, description: 'Output 1 data.'}
implementation:
container:
image: gcr.io/my-org/my-image@sha256:a172..752f
# command is a list of strings (command-line arguments).
# The YAML language has two syntaxes for lists and you can use either of them.
# Here we use the "flow syntax" - comma-separated strings inside square brackets.
command: [
python3,
# Path of the program inside the container
/pipelines/component/src/program.py,
--input1-path,
{inputPath: Input 1},
--param1,
{inputValue: Parameter 1},
--output1-path,
{outputPath: Output 1},
]
在管道中使用组件
您可以使用 Kubeflow Pipelines SDK 使用以下方法加载组件:
- kfp.components.load_component_from_file:使用此方法从 component.yaml 路径加载组件。
- kfp.components.load_component_from_url:使用此方法从 url 加载 component.yaml。
- kfp.components.load_component_from_text:使用此方法从字符串加载组件规范 YAML。该方法对于快速迭代组件规范非常有用。
这些函数创建一个工厂函数,您可以使用该函数创建 ContainerOp 实例,作为管道中的步骤。此工厂函数的输入参数包括组件的输入和组件输出的路径。可以通过以下方式修改函数签名,以确保它是有效的和 Pythonic 的。
- 具有默认值的输入将出现在没有默认值和输出的输入之后。
- 输入和输出名称转换为 Python 名称(空格和符号替换为下划线,字母转换为小写)。例如,名为 input 1 的输入被转换为 input_1。
下面的示例演示如何加载组件规范的文本并在两步管道中运行它。在运行此示例之前,请更新组件规范以使用在前面几节中定义的组件规范。
为了演示组件之间的数据传递,我们创建了另一个组件,它只使用 bash 命令将一些文本值写入输出文件。输出文件可以作为输入传递给我们的前一个组件。
import kfp
import kfp.components as comp
create_step_get_lines = comp**.load_component_from_text(**"""
name: Get Lines
description: Gets the specified number of lines from the input file.
inputs:
- {name: Input 1, type: Data, description: 'Data for input 1'}
- {name: Parameter 1, type: Integer, default: '100', description: 'Number of lines to copy'}
outputs:
- {name: Output 1, type: Data, description: 'Output 1 data.'}
implementation:
container:
image: gcr.io/my-org/my-image@sha256:a172..752f
# command is a list of strings (command-line arguments).
# The YAML language has two syntaxes for lists and you can use either of them.
# Here we use the "flow syntax" - comma-separated strings inside square brackets.
command: [
python3,
# Path of the program inside the container
/pipelines/component/src/program.py,
--input1-path,
{inputPath: Input 1},
--param1,
{inputValue: Parameter 1},
--output1-path,
{outputPath: Output 1},
]""")
# create_step_get_lines is a "factory function" that accepts the arguments
# for the component's inputs and output paths and returns a pipeline step
# (ContainerOp instance).
#
# To inspect the get_lines_op function in Jupyter Notebook, enter
# "get_lines_op(" in a cell and press Shift+Tab.
# You can also get help by entering `help(get_lines_op)`, `get_lines_op?`,
# or `get_lines_op??`.
# Create a simple component using only bash commands. The output of this component
# can be passed to a downstream component that accepts an input with the same type.
create_step_write_lines = comp**.load_component_from_text(**"""
name: Write Lines
description: Writes text to a file.
inputs:
- {name: text, type: String}
outputs:
- {name: data, type: Data}
implementation:
container:
image: busybox
command:
- sh
- -c
- |
mkdir -p "$(dirname "$1")"
echo "$0" > "$1"
args:
- {inputValue: text}
- {outputPath: data}
""")
# Define your pipeline
def my_pipeline**()😗*
write_lines_step = create_step_write_lines**(**
text**='one\ntwo\nthree\nfour\nfive\nsix\nseven\neight\nnine\nten')**
get_lines_step = create_step_get_lines**(**
# Input name "Input 1" is converted to pythonic parameter name "input_1"
input_1**=write_lines_step.outputs['data'],**
parameter_1**='5',**
)
# If you run this command on a Jupyter notebook running on Kubeflow,
# you can exclude the host parameter.
# client = kfp.Client()
client = kfp**.Client(host='<your-kubeflow-pipelines-host-name>')**
# Compile, upload, and submit this pipeline for execution.
client**.create_run_from_pipeline_func(my_pipeline,** arguments**={})**
组织组件文件
本节提供了组织组件文件的推荐方法。没有要求您必须以这种方式组织文件。然而,使用标准组织可以将相同的脚本用于测试、图像构建和组件版本控制。
components/<component group>/<component name>/
src/* # Component source code files
tests/* # Unit tests
run_tests.sh # Small script that runs the tests
README.md # Documentation. If multiple files are needed, move to docs/.
Dockerfile # Dockerfile to build the component container image
build_image.sh # Small script that runs docker build and docker push
component.yaml # Component definition in YAML format
有关真实组件示例,请参见此示例组件。
3.3.1.5.1.10.构建基于 Python 函数的组件
使用 Python 构建自己的轻量级管道组件
 在 Google Colab 中运行;
在 Google Colab 中运行; 在 GitHub 上查看源代码
在 GitHub 上查看源代码
Kubeflow Pipelines 组件是一组自包含的代码,在 ML 工作流中执行一个步骤。管道组件包括:
- 组件代码,它实现了在 ML 工作流中执行步骤所需的逻辑。
- 组件规范,其定义如下:
- 组件的元数据、名称和描述。
- 组件的接口、组件的输入和输出。
- 组件的实现、要运行的 Docker 容器映像、如何向组件代码传递输入以及如何获取组件的输出。
基于 Python 函数的组件可以让您将组件代码构建为 Python 函数并为您生成组件规范,从而使快速迭代变得更容易。本文档描述了如何构建基于 Python 函数的组件并在管道中使用它们。
开始之前
运行以下命令以安装 Kubeflow Pipelines SDK。如果在 Jupyter 笔记本中运行此命令,请在安装 SDK 后重新启动内核。
$ pip3 install kfp **--**upgrade
# Katib
# 3.4.1.Katib 简介
Katib 用于超参数调谐和神经结构搜索的概述
本指南介绍了超参数调谐、神经架构搜索以及作为 Kubeflow 组件的 Katib 系统的概念。
Katib 是用于自动机器学习(AutoML)的 Kubernetes 本地项目。Katib 支持超参数调整、早期停止和神经架构搜索(NAS)。通过 fast.ai、Google Cloud、Microsoft Azure 或 Amazon SageMaker 了解有关 AutoML 的更多信息。
Katib 是一个与机器学习(ML)框架无关的项目。它可以调整以用户选择的任何语言编写的应用程序的超参数,并原生支持许多 ML 框架,如 TensorFlow、MXNet、PyTorch、XGBoost 等。
Katib 支持多种 AutoML 算法,如贝叶斯优化、Parzen 树估计、随机搜索、协方差矩阵自适应进化策略、双曲线、高效神经架构搜索、可区分架构搜索等。其他算法支持即将到来。
Katib 项目是开源的。对于希望为项目做出贡献的开发人员来说,开发人员指南是一个很好的起点。
# 3.4.1.1.超参数和超参数调谐
超参数是控制模型训练过程的变量。它们包括:
- 学习率。
- 神经网络中的层数。
- 每个层中的节点数。
无法学习超参数值。换句话说,与节点权重和其他训练参数相比,模型训练过程不调整超参数值。
超参数调整是优化超参数值以最大化模型的预测精度的过程。如果您不使用 Katib 或类似系统进行超参数调整,您需要自己运行许多训练作业,手动调整超参数以找到最佳值。
自动超参数调整通过优化目标变量(也称为目标度量)来工作,该变量在超参数调整作业的配置中指定。一个常见的度量是模型在训练工作的验证过程中的准确性(验证准确性)。还可以指定是否希望超参数调整作业最大化或最小化度量。
例如,Katib 的下图显示了各种超参数值组合(学习率、层数和优化器)的验证精度水平:
Katib 在每个超参数调整作业(实验)中运行多个训练作业(称为试验)。每次试验都测试一组不同的超参数配置。实验结束时,Katib 输出超参数的优化值。
通过使用早期停止技术(early stopping)^101 (opens new window),可以改进超参数调谐实验。有关详细信息,请遵循提前停车指南^102 (opens new window)。
# 3.4.1.2.神经架构搜索
除了超参数调整,Katib 还提供了神经架构搜索功能。您可以使用 NAS 设计您的人工神经网络,目标是最大化模型的预测精度和性能。
NAS 与超参数调谐密切相关。两者都是 AutoML 的子集。当超参数调整优化模型的超参数时,NAS 系统优化模型的结构、节点权重和超参数。
NAS 技术通常使用各种技术来找到最佳的神经网络设计。
您可以从命令行或 UI 提交 Katib 作业。(在本页稍后了解有关 Katib 界面的更多信息。)以下屏幕截图显示了从 Katib UI 提交 NAS 作业的部分表单:
# 3.4.1.3.Katib 接口
您可以使用以下界面与 Katib 交互:
可用于提交实验和监视结果的 web UI。有关如何访问 UI 的信息,请参阅入门指南^103 (opens new window)。Kubeflow 中的 Katib 主页如下所示:
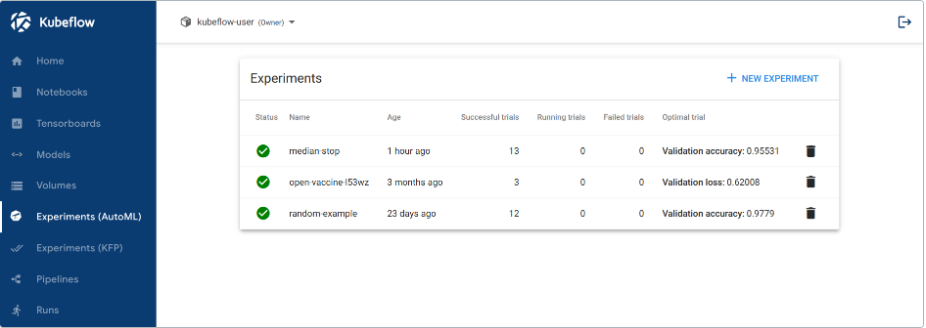
- gRPC API。检查 GitHub 上的 API 引用^104 (opens new window)。
- 命令行界面(CLI):
- Kubernetes CLI kubectl 对于针对 Kubeflow 集群运行命令非常有用。在 Kubernetes 文档^105 (opens new window)中了解 kubectl。
- Katib Python SDK。查看 GitHub 上的 Katib Python SDK 文档^106 (opens new window)。
# 3.4.1.4.Katib 概念
本节介绍 Katib 中使用的术语。
实验:实验是一次调整运行,也称为优化运行。
您可以指定配置设置来定义实验。主要配置如下:
- **目标:**您要优化的内容。这是客观指标,也称为目标变量。一个常见的度量是模型在训练工作的验证过程中的准确性(验证准确性)。还可以指定是否希望超参数调整作业最大化或最小化度量。
- **搜索空间:**超参数调整作业应考虑优化的所有可能超参数值的集合,以及每个超参数的约束。搜索空间的其他名称包括可行集和解空间。例如,您可以提供要优化的超参数的名称。对于每个超参数,您可以提供最小值和最大值或允许值列表。
- **搜索算法:**搜索最佳超参数值时使用的算法。
Katib 实验被定义为 Kubernetes CRD^107 (opens new window)。
有关如何定义实验的详细信息,请遵循实验运行指南^108 (opens new window)。
# 3.4.1.4.1.建议
一个建议是超参数调谐过程提出的一组超参数值。Katib 创建了一个试验来评估建议的一组值。Katib 建议定义为 Kubernetes CRD^109 (opens new window)。
# 3.4.1.4.2.试验
试验是超参数调谐过程的一次迭代。试用对应于一个具有参数分配列表的工人作业实例。参数分配列表与建议相对应。
每个实验都要进行几次试验。实验运行试验,直到达到目标或配置的最大试验次数。
Katib 试验被定义为 Kubernetes CRD。
# 3.4.1.4.3.工作作业 worker job
工作(worker job)是评估试验并计算其目标值的过程。工人作业可以是任何类型的 Kubernetes 资源或 KubernetesCRD。按照试用模板指南^110 (opens new window)检查如何在 Katib 中支持您自己的 Kubernetes 资源。
Katib 在上游有以下 CRD 示例:
- Kubernetes Job
- Kubeflow TFJob
- Kubeflow PyTorchJob
- Kubeflow MXJob
- Kubeflow XGBoostJob
- Kubeflow MPIJob
- Tekton Pipelines
- Argo Workflows
通过提供上述工作类型,Katib 支持多种 ML 框架。
# 3.4.2.Katib 入门
如何设置 Katib 并执行超参数调整
本指南介绍了如何开始使用 Katib,并使用命令行和 Katib 用户界面(UI)运行一些示例来执行超参数调整。
有关 Katib 和超参数调谐的概念概述,请查看 Katib 简介。
# 3.4.2.1.Katib 设置
让我们使用 Kubeflow 在 Kubernetes 集群上设置和配置 Katib。
# 3.4.2.1.1.先决条件
这是安装 Katib 的最低要求:
Kubernetes>=1.17
库贝特尔>=1.21
# 3.4.2.1.2.安装 Katib
如果您已经安装了 Kubeflow,则可以跳过此步骤。您的 Kubeflow 部署包括 Katib。
要将 Katib 安装为 Kubeflow 的一部分,请遵循 Kubeflow 安装指南。
如果您想与 Kubeflow 单独安装 Katib,或者想要获得更高版本的 Katib,可以使用以下 Katib 安装之一。要安装特定的 Katib 版本(例如 v0.11.1),请将 ref=master 修改为 ref=v0.11.1。
1.Katib 独立安装
有两种独立安装 Katib 的方法,这两种方法都不需要在 Kubernetes 集群上进行任何额外的设置。
1.1.基本安装
运行以下命令以使用主要组件(Katib 控制器、Katib ui、Katib mysql、Katib 数据库管理器和 Katib 证书生成器)部署 Katib:
kubectl apply -k "github.com/kubeflow/katib.git/manifests/v1beta1/installs/katib-standalone?ref=master"
1.2.控制器领主选举支持
运行以下命令以部署 Katib 和控制器领导人选举:
kubectl apply -k "github.com/kubeflow/katib.git/manifests/v1beta1/installs/katib-leader-election?ref=master"
此安装与基本安装几乎相同,尽管您可以使用领导人选举使 katib 控制器高度可用(HA)。如果您计划在需要高服务级别协议(SLA)和服务级别目标(SLO)的环境(如生产环境)中使用 Katib,请考虑选择此安装。
2.Katib Cert Manager 安装
运行以下命令以按照 Cert Manager 要求部署 Katib:
kubectl apply -k "github.com/kubeflow/katib.git/manifests/v1beta1/installs/katib-cert-manager?ref=master"
此安装使用证书管理器而不是 katib 证书生成器来提供 katib webhooks 证书。在使用此安装部署 Katib 之前,您必须在 Kubernetes 集群上部署 Cert Manager。
3.Katib 外部数据库安装
运行以下命令以使用自定义数据库(DB)后端部署 Katib:
kubectl apply -k "github.com/kubeflow/katib.git/manifests/v1beta1/installs/katib-external-db?ref=master"
此安装允许使用自定义 MySQL DB 而不是 katib MySQL。您必须在 secrets.env 中为 katib 数据库管理器修改适当的环境变量,以指向您的自定义 MySQL 数据库。在本指南中了解有关 katib db 管理器环境变量的更多信息。
4.OpenShift 上的 Katib
运行以下命令在 OpenShift v4.4+上部署 Katib:
kubectl apply -k "github.com/kubeflow/katib.git/manifests/v1beta1/installs/katib-openshift?ref=master"
此安装使用 OpenShift 服务控制器而不是 katib 证书生成器来提供 katib webhooks 证书。
上述安装为 Katib DB 组件部署 Persistent Volume Claim(PVC)^111 (opens new window)。
Kubernetes 集群必须具有用于动态卷配置的 StorageClass。有关更多信息,请查看 Kubernetes 关于动态资源调配^112 (opens new window)的文档。
如果集群没有动态卷配置,则必须手动部署 Persistent Volume(PV)以绑定 Katib DB 组件的 PVC。
# Katib 组件
运行以下命令以验证 Katib 组件是否正在运行:
$ kubectl get pods -n kubeflow
NAME READY STATUS RESTARTS AGE
katib-cert-generator-79g7d 0/1 Completed 0 79s
katib-controller-566595bdd8-8w7sx 1/1 Running 0 82s
katib-db-manager-57cd769cdb-vt7zs 1/1 Running 0 82s
katib-mysql-7894994f88-djp7m 1/1 Running 0 81s
katib-ui-5767cfccdc-v9fcs 1/1 Running 0 80s
- katib-controller-管理 katib Kubernetes CRD 的控制器(实验、建议、试验)
- katib-ui-katib 用户界面。
- katib-db-manager-用于控制 katib 数据库接口的 GRPC API 服务器。
- katib-mysql-存储 katib 实验度量的 mysql DB 后端。
- (可选)katib-cert-generator-用于 katib 独立安装的证书生成器。在开发人员指南中了解有关证书生成器的更多信息
# 3.4.2.2.访问 Katib UI
您可以使用 Katib 用户界面(UI)提交实验并监控结果。Kubeflow 中的 Katib 主页如下所示:
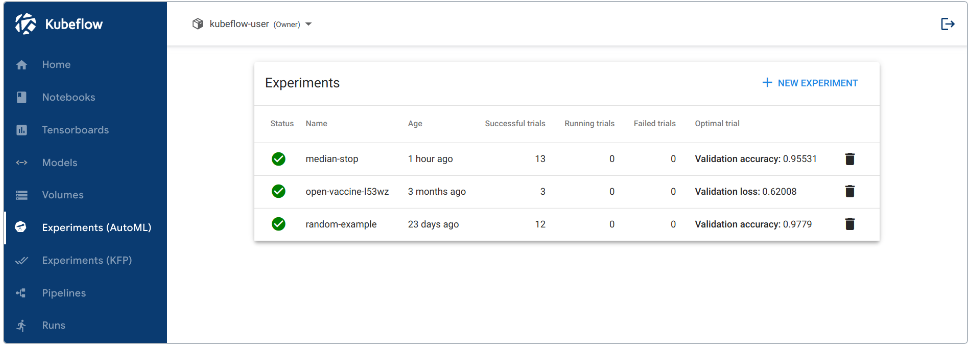
如果您将 Katib 作为 Kubeflow 的一部分安装,则可以从 Kubeflow UI 访问 Katib UI:
- 打开 Kubeflow UI。查看访问中央仪表板的指南。
- 单击左侧菜单中的 Katib。
或者,您可以为 Katib UI 服务设置端口转发:
kubectl port-forward svc/katib-ui -n kubeflow 8080:80
然后,您可以通过以下 URL 访问 Katib UI:
http://localhost:8080/katib/ (opens new window)
如果您想为 Katib UI 做出贡献,请查看本指南^113 (opens new window)。
# 3.4.2.3.示例
本节介绍一些可以运行以尝试 Katib 的示例。
# 3.4.2.3.1.使用随机搜索算法的示例
通过在 YAML 配置文件中定义实验,可以为 Katib 创建实验。YAML 文件定义了实验的配置,包括超参数可行空间、优化参数、优化目标、建议算法等。
本示例使用 YAML 文件作为随机搜索示例^114 (opens new window)。
随机搜索算法示例使用 MXNet 神经网络来使用 MNIST 数据集训练图像分类模型。您可以在此处查看训练容器源代码。该实验使用各种超参数运行了 12 个训练作业,并保存了结果。
如果将 Katib 作为 Kubeflow 的一部分安装,则无法在 Kubeflow 命名空间中运行实验。运行以下命令以更改命名空间并使用随机搜索示例启动实验:
1.下载示例:
curl https://raw.githubusercontent.com/kubeflow/katib/master/examples/v1beta1/hp-tuning/random.yaml (opens new window) --output random.yaml
2.编辑 random.yaml 并更改以下行以使用 Kubeflow 用户配置文件名称空间(例如 Kubeflow user example com):
namespace: kubeflow
(可选)注意:Katib 的实验不适用于 Istio sidecar 注入。如果您在 Istio 中使用 Kubeflow,则必须禁用 sidecar 注入。为此,请在实验的试用模板中指定以下注释:sidecar.istio.io/inject:“false”。
3.部署示例:
kubectl apply -f random.yaml
此示例将超参数嵌入为参数。通过使用 YAML 文件的 trialTemplate.trialSpec 部分中定义的模板,可以以另一种方式(例如,使用环境变量)嵌入超参数。该模板使用非结构化格式并替换 trialTemplate.trialParameters 中的参数。请遵循试用模板指南了解更多信息。
此示例随机生成以下超参数:
- --lr:学习率。类型:双人。
- --num-layers:神经网络中的层数。类型:整数。
- --optimizer:改变神经网络属性的优化方法。类型:分类。
检查实验状态:
kubectl -n kubeflow-user-example-com get experiment random -o yaml
上述命令的输出应与以下内容类似:
apiVersion: kubeflow.org/v1beta1
kind: Experiment
metadata:
...
name: random
namespace: kubeflow-user-example-com
...
spec:
algorithm:
algorithmName: random
maxFailedTrialCount: 3
maxTrialCount: 12
metricsCollectorSpec:
collector:
kind: StdOut
objective:
additionalMetricNames:
- Train-accuracy
goal: 0.99
metricStrategies:
- name: Validation-accuracy
value: max
- name: Train-accuracy
value: max
objectiveMetricName: Validation-accuracy
type: maximize
parallelTrialCount: 3
parameters:
- feasibleSpace:
max: "0.03"
min: "0.01"
name: lr
parameterType: double
- feasibleSpace:
max: "5"
min: "2"
name: num-layers
parameterType: int
- feasibleSpace:
list:
- sgd
- adam
- ftrl
name: optimizer
parameterType: categorical
resumePolicy: LongRunning
trialTemplate:
failureCondition: status.conditions.#(type=="Failed")#|#(status=="True")#
primaryContainerName: training-container
successCondition: status.conditions.#(type=="Complete")#|#(status=="True")#
trialParameters:
- description: Learning rate for the training model
name: learningRate
reference: lr
- description: Number of training model layers
name: numberLayers
reference: num-layers
- description: Training model optimizer (sdg, adam or ftrl)
name: optimizer
reference: optimizer
trialSpec:
apiVersion: batch/v1
kind: Job
spec:
template:
metadata:
annotations:
sidecar.istio.io/inject: "false"
spec:
containers:
- command:
- python3
- /opt/mxnet-mnist/mnist.py
- --batch-size=64
- --lr=${trialParameters.learningRate}
- --num-layers=${trialParameters.numberLayers}
- --optimizer=${trialParameters.optimizer}
image: docker.io/kubeflowkatib/mxnet-mnist:v1beta1-45c5727
name: training-container
restartPolicy: Never
status:
conditions:
- lastTransitionTime: "2021-10-07T21:12:06Z"
lastUpdateTime: "2021-10-07T21:12:06Z"
message: Experiment is created
reason: ExperimentCreated
status: "True"
type: Created
- lastTransitionTime: "2021-10-07T21:12:28Z"
lastUpdateTime: "2021-10-07T21:12:28Z"
message: Experiment is running
reason: ExperimentRunning
status: "True"
type: Running
currentOptimalTrial:
bestTrialName: random-hpsrsdqp
observation:
metrics:
- latest: "0.993054"
max: "0.993054"
min: "0.917694"
name: Train-accuracy
- latest: "0.979598"
max: "0.979598"
min: "0.957106"
name: Validation-accuracy
parameterAssignments:
- name: lr
value: "0.024736875661534784"
- name: num-layers
value: "4"
- name: optimizer
value: sgd
runningTrialList:
- random-2dwxbwcg
- random-6jd8hmnd
- random-7gks8bmf
startTime: "2021-10-07T21:12:06Z"
succeededTrialList:
- random-xhpcrt2p
- random-hpsrsdqp
- random-kddxqqg9
- random-4lkr5cjp
trials: 7
trialsRunning: 3
trialsSucceeded: 4
当 status.conditions.type 中的最后一个值为 Successed 时,实验完成。您可以查看有关状态最佳试用的信息。当前最佳试用。
- currentOptimalTrial.bestTrialName 是试用名称。
- currentOptimalTrial.observation.metrics 是目标和其他度量的最大值、最小值和最新记录值。
- currentOptimalTrial.parameterAssignments 是对应的超参数集。
此外,状态显示了实验的试验及其当前状态。
在 Katib UI 中查看实验结果:
1.如上所述打开 Katib UI。
2.您应该能够查看实验列表:
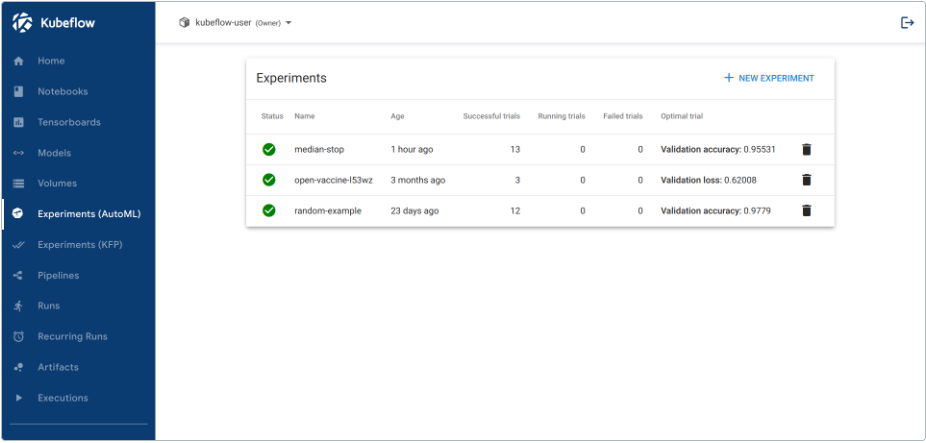
3.单击实验的名称,随机示例。
4.应该有一个图表显示超参数值(学习率、层数和优化器)的各种组合的验证水平和训练精度:
5.下图是实验中进行的试验列表:
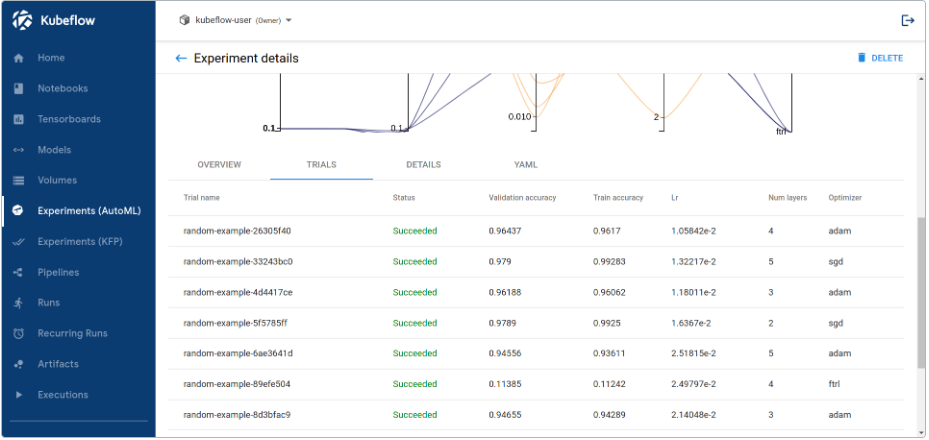
6.您可以单击试用名称以获取特定试用的指标:
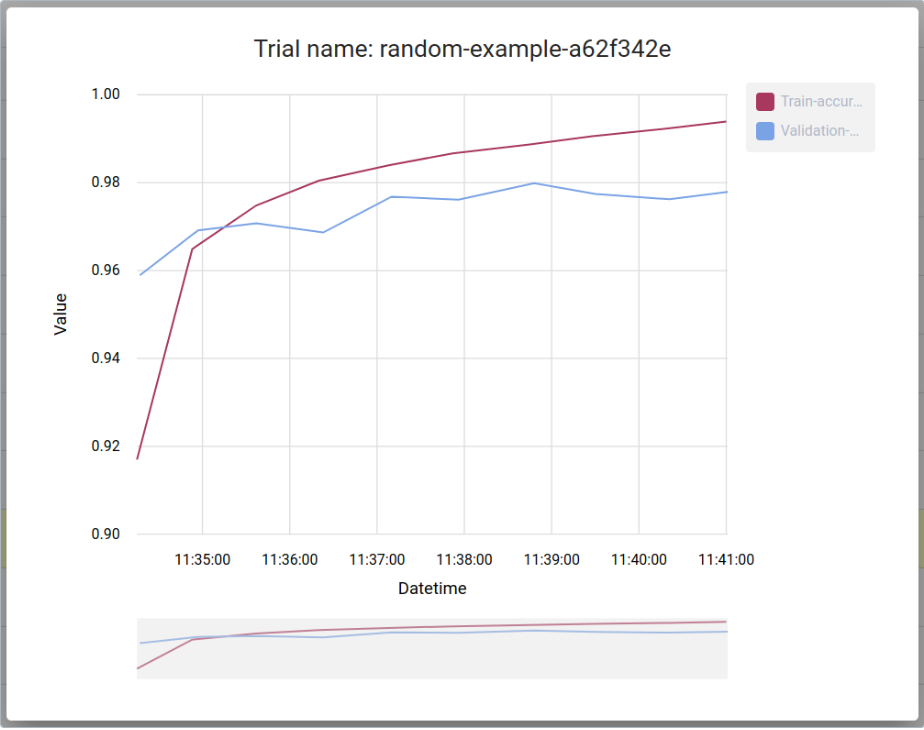
# 3.4.2.3.2.TensorFlow 示例
如果将 Katib 作为 Kubeflow 的一部分安装,则无法在 Kubeflow 命名空间中运行实验。运行以下命令以使用 Kubeflow 的 TensorFlow 训练作业操作员 TFJob 启动实验:
1.下载 tfjob-mnist-with-summaries.yaml:
curl https://raw.githubusercontent.com/kubeflow/katib/master/examples/v1beta1/kubeflow-training-operator/tfjob-mnist-with-summaries.yaml (opens new window) --output tfjob-mnist-with-summaries.yaml
2.编辑 tfjob-mnist-with-summaries.yaml 并更改以下行以使用 Kubeflow 用户配置文件名称空间(例如 Kubeflow user example com):
namespace: kubeflow
3.(可选)注意:Katib 的实验不适用于 Istio sidecar 注入。如果您在 Istio 中使用 Kubeflow,则必须禁用 sidecar 注入。为此,请在实验的试用模板中指定以下注释:sidecar.istio.io/inject:“false”。对于提供的 TFJob 示例,请检查此处如何设置注释。
4.部署示例:
kubectl apply -f tfjob-mnist-with-summaries.yaml
5.您可以检查实验的状态:
kubectl -n kubeflow-user-example-com get experiment tfjob-mnist-with-summaries -o yaml
# 3.4.2.3.3.PyTorch 示例
如果将 Katib 作为 Kubeflow 的一部分安装,则无法在 Kubeflow 命名空间中运行实验。运行以下命令以使用 Kubeflow 的 PyTorch 训练作业操作员 PyTorchJob 启动实验:
1.下载 pytorchjob-mnist.yaml:
curl https://raw.githubusercontent.com/kubeflow/katib/master/examples/v1beta1/kubeflow-training-operator/pytorchjob-mnist.yaml (opens new window) --output pytorchjob-mnist.yaml
2. 编辑 pytorchjob-mnist.yaml 并更改以下行以使用 Kubeflow 用户配置文件名称空间(例如 Kubeflow user example com):
namespace: kubeflow
3.(可选)注意:Katib 的实验不适用于 Istio sidecar 注入。如果您在 Istio 中使用 Kubeflow,则必须禁用 sidecar 注入。为此,请在实验的试用模板中指定以下注释:sidecar.istio.io/inject:“false”。对于提供的 PyTorchJob 示例,设置注释应类似于 TFJob
4.部署示例:
kubectl apply -f pytorchjob-mnist.yaml
5.您可以检查实验的状态:
kubectl -n kubeflow-user-example-com describe experiment pytorchjob-mnist
按照上面随机搜索算法示例中描述的步骤,在 Katib UI 中获得实验结果。
# 3.4.2.4.清理
要从 Kubernetes 集群中删除 Katib,请运行:
kubectl delete -k "github.com/kubeflow/katib.git/manifests/v1beta1/installs/katib-standalone?ref=master"
# 3.4.2.4.1.运行实验
如何在 Katib 中配置和运行超参数调谐或神经架构搜索实验
本指南介绍如何配置和运行 Katib 实验。根据配置设置,该实验可以执行超参数调整或神经架构搜索(NAS)(alpha)。
有关所涉及概念的概述,请查看 Katib 简介^115 (opens new window)。
# 3.4.2.4.2.将训练代码打包到容器图像中
Katib 和 Kubeflow 是基于 Kubernetes 的系统。要使用 Katib,您必须将训练代码打包在 Docker 容器映像中,并在注册表中提供该映像。查看 Docker 文档和 Kubernetes 文档。
# 3.4.2.4.3.配置实验
要在 Katib 中创建超参数调优或 NAS 实验,请在 YAML 配置文件中定义实验。YAML 文件定义了要优化的参数的潜在值范围(搜索空间)、确定最佳值时使用的目标度量、优化过程中使用的搜索算法以及其他配置。
作为参考,您可以使用随机搜索算法示例^116 (opens new window)的 YAML 文件。
下面的列表描述了 YAML 文件中用于实验的字段。Katib UI 提供了相应的字段。您可以选择从 UI 或命令行配置和运行实验。
3.4.2.4.3.1.配置规范
以下是实验配置规范中的字段:
parameters:要为机器学习(ML)模型调整的超参数或其他参数的范围。这些参数定义了搜索空间,也称为可行集或解空间。在规范的这一部分中,您定义了需要搜索的每个超参数的名称和分布(离散或连续)。例如,您可以为每个超参数提供最小值和最大值或允许值列表。Katib 根据您指定的超参数调整算法生成范围内的超参数组合。请参阅 ParameterSpec 类型。
objective:要优化的度量。目标度量也称为目标变量。一个常见的度量是模型在训练工作的验证过程中的准确性(验证准确性)。您还可以指定是否希望 Katib 最大化或最小化度量。
Katib 使用 objectiveMetricName 和 additionalMetricNames 来监控超参数如何与模型一起工作。Katib 记录了最佳 objectiveMetricName 度量值(根据类型最大化或最小化)和实验的.status.currentOptimalTrial.parameterAssignments 中相应的超参数集的值。如果一组超参数的 objectiveMetricName 度量值达到目标,Katib 将停止尝试更多的超参数组合。
您可以在不指定目标的情况下运行实验。在这种情况下,Katib 运行实验,直到相应的成功试验达到 maxTrialCount。maxTrialCount 参数如下所述。
计算实验目标的默认方法是:
- 当目标类型最大化时,Katib 会比较所有最大度量值。
- 当目标类型最小化时,Katib 会比较所有最小度量值。
要更改默认设置,请使用各种规则(最小、最大或最新)定义 metricStrategies,以从实验的 objectiveMetricName 和 additionalMetricNames 中提取每个度量的值。根据选择的策略计算实验的目标值。
例如,可以按如下方式设置实验中的参数:
. . .
objectiveMetricName: accuracy
type: maximize
metricStrategies:
- name: accuracy
value: latest
. . .
其中 Katib 控制器从每个试验的所有最新报告的准确度度量中搜索最佳最大值。检查度量策略示例^117 (opens new window)。每个度量的默认策略类型等于目标类型。
请参阅 ObjectiveSpec 类型。
- parallelTrialCount:Katib 应该并行训练的超参数集的最大数量。默认值为 3。
- maxTrialCount:要运行的最大试用次数。这相当于 Katib 应该生成的测试模型的超参数集的数量。如果省略了 maxTrialCount 值,则您的实验将一直运行,直到达到目标或实验达到最大失败次数。
- maxFailedTrialCount:允许失败的最大尝试次数。这相当于 Katib 应该测试的失败超参数集的数量。Katib 将状态为 Failed 或 Metrics Unavailable 的试验识别为 Failed 试验,如果失败的试验数量达到 maxFailedTrialCount,则 Katib 将以 Failed 状态停止试验。
- algorithm:您希望 Katib 用于查找最佳超参数或神经架构配置的搜索算法。示例包括随机搜索、网格搜索、贝叶斯优化等。检查下面的搜索算法详细信息。
- trialTemplate:定义试用的模板。如上所述,您必须将 ML 训练代码打包成 Docker 图像。trialTemplate.trialSpec 是带有模型参数的非结构化模板,这些参数由 trialTemplate.trialParameters 替换。例如,训练容器可以将超参数作为命令行参数或环境变量接收。您必须在 trialTemplate.prprimaryContainerName 中设置训练容器的名称。
Katib 动态支持任何类型的 Kubernetes CRD。在 Katib 示例中,您可以找到以下工作类型来训练您的模型:
- Kubernetes Job
- Kubeflow TFJob
- Kubeflow PyTorchJob
- Kubeflow MXJob
- Kubeflow XGBoostJob
- Kubeflow MPIJob
- Tekton Pipelines
- Argo Workflows
请参阅 TrialTemplate 类型。遵循试用模板指南了解如何指定 trialTemplate 参数、在 ConfigMaps 中保存模板以及在 Katib 中支持自定义 Kubernetes 资源。
metricsCollectorSpec:关于如何从每次测试中收集度量的规范,例如准确性和损失度量。了解以下指标收集器的详细信息。默认度量收集器是 StdOut。
nasConfig:神经架构搜索(NAS)的配置。注意:NAS 目前处于 alpha 版本,支持有限。您可以指定要优化的神经网络设计的配置,包括网络中的层数、操作类型等。请参阅 NasConfig 类型。
graphConfig:为神经网络的有向非循环图定义结构的图形配置。可以指定层数、输入层的 input_size 和输出层的 output_size。请参阅 GraphConfig 类型。
operations:要为 ML 模型调整的操作范围。对于每个神经网络层,NAS 算法选择其中一个操作来构建神经网络。每个操作包含上述参数集。请参阅操作类型。
您可以在此处找到所有 NAS 示例。
resumePolicy:可以是 LongRunning、Never 或 FromVolume 之一。默认值为 LongRunning。请参阅恢复策略类型。要了解如何修改正在运行的实验并使用各种重新启动策略,请遵循“恢复实验”指南。
关于 Katib 的实验、建议和试验类型的背景信息:在 Kubernetes 术语中,Katib 的试验类型、建议类型和试验类型是一种自定义资源(CR)。您为实验创建的 YAML 文件是 CR 规范。
3.4.2.4.3.2.详细搜索算法
Katib 目前支持几种搜索算法。请参阅 AlgorithmSpec 类型。
以下是 Katib 中可用的搜索算法列表:
- Grid search
- Random search
- Bayesian optimization
- Hyperband
- Tree of Parzen Estimators (TPE)
- Multivariate TPE
- Covariance Matrix Adaptation Evolution Strategy (CMA-ES)
- Sobol’s Quasirandom Sequence
- Neural Architecture Search based on ENAS
- Differentiable Architecture Search (DARTS)
- Population Based Training (PBT)
更多的算法正在开发中。
你可以自己给 Katib 添加一个算法。查看添加新算法的指南和开发人员指南。
3.4.2.4.3.3.网格搜索
Katib 中的算法名称是 grid。
当所有变量都是离散的(而不是连续的)并且可能性很低时,网格采样非常有用。网格搜索在所有可能性上执行彻底的组合搜索,使得搜索过程非常长,即使对于中等大小的问题也是如此。
Katib 使用 Chocolate 优化框架^118 (opens new window)进行网格搜索。
3.4.2.4.3.4.随机搜索
Katib 中的算法名称是随机的。
随机抽样是网格搜索的一种替代方法,当需要优化的离散变量数量较大且每次评估所需时间较长时使用。当所有参数都是离散的时,随机搜索执行采样而不进行替换。因此,当组合探索不可能时,随机搜索是最好的算法。如果连续变量的数量很高,则应改用准随机抽样。
Katib 使用 Hyperopt^119 (opens new window)、Goptuna^120 (opens new window)、Chocolate^121 (opens new window)或 Optuna^122 (opens new window)优化框架进行随机搜索。
Katib 支持以下算法设置:
| Setting name | Description | Example |
|---|---|---|
| random_state | [int]: Set random_state to something other than None for reproducible results. | 10 |
3.4.2.4.3.5.贝叶斯优化
Katib 中的算法名称是 bayesianoptimization。
贝叶斯优化^123 (opens new window)方法使用高斯过程回归对搜索空间进行建模。该技术计算搜索空间中每个点处损失函数的估计值和该估计值的不确定性。该方法适用于搜索空间中维数较低的情况。由于该方法建模了预期损失和不确定性,搜索算法在几个步骤内收敛,因此当完成参数配置评估的时间很长时,它是一个很好的选择。
Katib 使用 Scikit 优化^124 (opens new window)或巧克力优化框架^125 (opens new window)进行贝叶斯搜索。Scikit Optimize 也称为 skopt。
Katib 支持以下算法设置:
3.4.2.4.3.6.双曲线
Katib 中的算法名称是 hyperband。
Katib 支持 Hyperband^126 (opens new window)优化框架。与使用贝叶斯优化来选择配置不同,Hyperband 专注于提前停止,作为优化资源分配的策略,从而最大化其可以评估的配置数量。Hyperband 还关注搜索的速度。
3.4.2.4.3.7.Parzen 估计树(TPE)
Katib 中的算法名称是 tpe。
Katib 使用 Hyperopt、Goptuna 或 Optuna 优化框架进行 TPE 搜索。
该方法提供了基于正向和反向梯度的搜索。
Katib 支持以下算法设置:
| Setting name | Description | Example |
|---|---|---|
| n_EI_candidates | [int]: Number of candidate samples used to calculate the expected improvement. | 25 |
| random_state | [int]: Set random_state to something other than None for reproducible results. | 10 |
| gamma | [float]: The threshold to split between l(x) and g(x), check equation 2 in this Paper (opens new window). Value must be in (0, 1) range. | 0.25 |
| prior_weight | [float]: Smoothing factor for counts, to avoid having 0 probability. Value must be > 0. | 1.1 |
3.4.2.4.3.8.多变量 TPE
Katib 中的算法名称是 multivariate-tpe。
Katib 使用 Optuna^127 (opens new window)优化框架进行多变量 TPE 搜索。
Multivariate TPE^128 (opens new window)是独立(默认)TPE 的改进版本。该方法在搜索空间中查找超参数之间的依赖关系。
Katib 支持以下算法设置:
| Setting name | Description | Example |
|---|---|---|
| n_ei_candidates | [int]: Number of Trials used to calculate the expected improvement. | 25 |
| random_state | [int]: Set random_state to something other than None for reproducible results. | 10 |
| n_startup_trials | [int]: Number of initial Trials for which the random search algorithm generates hyperparameters. | 5 |
3.4.2.4.3.9.协方差矩阵自适应进化策略(CMA-ES)
Katib 中的算法名称是 cmaes。
Katib 使用 Goptuna 或 Optuna 优化框架进行 CMA-ES 搜索。
协方差矩阵自适应进化策略是一种用于连续搜索空间中优化问题的随机无导数数值优化算法。您还可以使用 IPOP-CMA-ES 和 BIOP-CMA-ES,当收敛到局部最小值时重新启动优化的变体算法。
Katib 支持以下算法设置:
| Setting name | Description | Example |
|---|---|---|
| random_state | [int]: Set random_state to something other than None for reproducible results. | 10 |
| sigma | [float]: Initial standard deviation of CMA-ES. | 0.001 |
| restart_strategy | [string, "none", "ipop", or "bipop", default="none"]: Strategy for restarting CMA-ES optimization when converges to a local minimum. | "ipop" |
3.4.2.4.3.10.Sobol 的 Quasirandom 序列
Katib 中的算法名称是 sobol。
Katib 使用 Goptuna^129 (opens new window)优化框架进行 Sobol 的准随机搜索。
Sobol’s quasirandom sequence ^130 (opens new window)是一个低差异序列。众所周知,Sobol 的准随机序列可以提供更好的均匀性。
3.4.2.4.3.11.基于 ENAS 的神经结构搜索
Katib 中的算法名称是 enas。
| Setting Name | Type | Default value | Description |
|---|---|---|---|
| controller_hidden_size | int | 64 | RL controller lstm hidden size. Value must be >= 1. |
| controller_temperature | float | 5.0 | RL controller temperature for the sampling logits. Value must be > 0. Set value to "None" to disable it in the controller. |
| controller_tanh_const | float | 2.25 | RL controller tanh constant to prevent premature convergence. Value must be > 0. Set value to "None" to disable it in the controller. |
| controller_entropy_weight | float | 1e-5 | RL controller weight for entropy applying to reward. Value must be > 0. Set value to "None" to disable it in the controller. |
| controller_baseline_decay | float | 0.999 | RL controller baseline factor. Value must be > 0 and <= 1. |
| controller_learning_rate | float | 5e-5 | RL controller learning rate for Adam optimizer. Value must be > 0 and <= 1. |
| controller_skip_target | float | 0.4 | RL controller probability, which represents the prior belief of a skip connection being formed. Value must be > 0 and <= 1. |
| controller_skip_weight | float | 0.8 | RL controller weight of skip penalty loss. Value must be > 0. Set value to "None" to disable it in the controller. |
| controller_train_steps | int | 50 | Number of RL controller training steps after each candidate runs. Value must be >= 1. |
| controller_log_every_steps | int | 10 | Number of RL controller training steps before logging it. Value must be >= 1. |
有关详细信息,请检查:
Katib 存储库中关于高效神经架构搜索(ENAS)的文档。
ENAS 示例-ENAS-gpu.yaml-试图显示所有可能的操作。由于搜索空间很大,该示例不太可能产生好的结果。
3.4.2.4.3.12.可区分体系结构搜索(DARTS)
Katib 中的算法名称是 darts。
目前,您无法在 Katib UI 中查看此算法的结果,只能在单个 GPU 上运行实验。
Katib 支持以下算法设置:
| Setting Name | Type | Default value | Description |
|---|---|---|---|
| num_epochs | int | 50 | Number of epochs to train model |
| w_lr | float | 0.025 | Initial learning rate for training model weights. This learning rate annealed down to w_lr_min following a cosine schedule without restart. |
| w_lr_min | float | 0.001 | Minimum learning rate for training model weights. |
| w_momentum | float | 0.9 | Momentum for training training model weights. |
| w_weight_decay | float | 3e-4 | Training model weight decay. |
| w_grad_clip | float | 5.0 | Max norm value for clipping gradient norm of training model weights. |
| alpha_lr | float | 3e-4 | Initial learning rate for alphas weights. |
| alpha_weight_decay | float | 1e-3 | Alphas weight decay. |
| batch_size | int | 128 | Batch size for dataset. |
| num_workers | int | 4 | Number of subprocesses to download the dataset. |
| init_channels | int | 16 | Initial number of channels. |
| print_step | int | 50 | Number of training or validation steps before logging it. |
| num_nodes | int | 4 | Number of DARTS nodes. |
| stem_multiplier | int | 3 | Multiplier for initial channels. It is used in the first stem cell. |
有关详细信息,请检查:
不同体系结构搜索的 Katib 存储库中的文档。
DARTS 的例子-DARTS-gpu.yaml。
3.4.2.4.3.12.基于种群的训练(PBT)
Katib 中的算法名称是 pbt。
查看基于群体的训练论文,了解有关该算法的更多详细信息。
PBT 服务需要具有 RWX 访问模式的持久卷声明,以便在 Suggestion 和 Trials 之间共享资源。目前,Katib 实验应该有 resumePolicy:FromVolume 来运行 PBT 算法。在本指南中了解有关简历策略的更多信息。
Katib 支持以下算法设置:
| Setting name | Description | Example |
|---|---|---|
| suggestion_trial_dir | The location within the trial container where checkpoints are saved | /var/log/katib/checkpoints/ |
| n_population | Number of trial seeds per generation | 40 |
| resample_probability | null (default): perturbs the hyperparameter by 0.8 or 1.2. 0-1: resamples the original distribution by the specified probability | 0.3 |
| truncation_threshold | Exploit threshold for pruning low performing seeds | 0.4 |
3.4.2.4.3.13.指标收集器
在 YAML 配置文件的 metricsCollectorSpec 部分,您可以定义 Katib 应该如何从每次测试中收集度量,例如准确度和损失度量。参考 MetricsCollectorSpec 类型
训练代码可以将度量记录到 stdout 或任意输出文件中。Katib 使用 sidecar 容器收集度量。sidecar 是一个实用容器,它支持 Kubernetes Pod 中的主容器。
要定义实验的度量收集器,请执行以下操作:
1、在.collector.kind 字段中指定收集器类型。Katib 的度量收集器支持以下收集器类型:
StdOut:Katib 从操作系统的默认输出位置(标准输出)收集度量。这是默认的度量收集器。
File:Katib 从您在.source.fileSystemPath.path 字段中指定的任意文件收集度量。训练容器应以 TEXT 或 JSON 格式将度量记录到此文件中。如果选择 JSON 格式,则度量必须按如下所示用 行分隔的 epoch 或 step,时间戳的键必须是 timestamp:
{"epoch": 0, "foo": “bar", “fizz": “buzz", "timestamp": 1638422847.28721…}
{"epoch": 1, "foo": “bar", “fizz**": “buzz",** "timestamp": 1638422847.287801…}
{"epoch": 2, "foo": “bar", “fizz": “buzz", "timestamp": "2021-12-02T14:27:50.000035161+09:00"…}
{"epoch": 3, "foo": “bar", “fizz**": “buzz",** "timestamp": "2021-12-02T14:27:50.000037459+09:00"…}
…
检查 TEXT 和 JSON 格式的文件度量收集器示例。此外,默认文件路径为/var/log/katib/metrics.log,默认文件格式为 TEXT。
TensorFlowEvent:Katib 从包含 tf.Event 的目录路径收集度量。您应该在.source.fileSystemPath.path 字段中指定路径。检查 TFJob 示例。默认目录路径为/var/log/katib/tfevent/。
自定义:如果需要使用自定义方式收集度量,请指定此值。必须在.collector.customCollector 字段中定义自定义度量收集器容器。检查自定义度量收集器示例。
无:如果不需要使用 Katib 的度量收集器,请指定此值。例如,您的训练代码可以处理其自身度量的持久存储。
2.在训练容器中编写代码,以.source.filter.metricsFormat 字段中指定的格式打印或保存到文件度量。默认格式为([\w|-]+)\s*=\s*([+-]?\d*(\.\d+)?([Ee][+-]?\d+)?)。每个元素都是带有两个子表达式的正则表达式。第一个匹配的表达式作为度量名称。第二个匹配表达式作为度量值。
例如,使用默认度量格式和 StdOut 度量收集器,如果目标度量的名称是 loss ,而其他度量是 recall 和 precision,则训练代码应打印以下输出:
epoch 1:
loss**=**3.0e-02
recall**=**0.5
precision**=**.4
epoch 2:
loss**=**1.3e-02
recall**=**0.55
precision**=**.5
# 3.4.3.运行实验
您可以从命令行或 Katib UI 运行 Katib 实验。
从命令行运行实验
您可以使用 kubectl 从命令行启动实验:
kubectl apply -f <your-path/your-experiment-config.yaml>
注:
如果您将 Katib 作为 Kubeflow 的一部分进行部署(Kubeflow 部署应包括 Katib),则需要将 Kubeflow 命名空间更改为配置文件命名空间。
(可选)Katib 的实验不适用于 Istio sidecar 注入。如果使用 Istio 运行 Kubeflow,则必须禁用 sidecar 注入。为此,请在实验的试用模板中指定以下注释:sidecar.istio.io/inject:“false”。有关如何为 Job、TFJob(TensorFlow)或 PyTorchJob(PyTorch)执行此操作的示例,请参阅入门指南。
运行以下命令以使用随机搜索算法示例启动实验:
kubectl apply -f https://raw.githubusercontent.com/kubeflow/katib/master/examples/v1beta1/hp-tuning/random.yaml (opens new window)
检查实验状态:
kubectl -n kubeflow describe experiment <your-experiment-name>
例如,要检查随机搜索算法实验运行的状态:
kubectl -n kubeflow describe experiment random
# 3.4.3.1.从 Katib UI 运行实验
您可以从 Katib UI 提交实验,而不是使用命令行。以下步骤假设您想要运行超参数调整实验。如果您想运行神经架构搜索,请访问 UI 的 NAS 部分(而不是 HP 部分),然后执行类似的步骤序列。
要从 Katib UI 运行超参数调整实验:
- 按照入门指南访问 Katib UI^131 (opens new window)。
- 单击 Katib 主页上的“新建实验”(NEW EXPERIMENT)。
- 您应该能够查看提供以下选项的选项卡:
- YAML 文件:选择此选项以提供包含实验配置的完整 YAML 文件。
- 参数:选择此选项可将配置值输入到表单中。
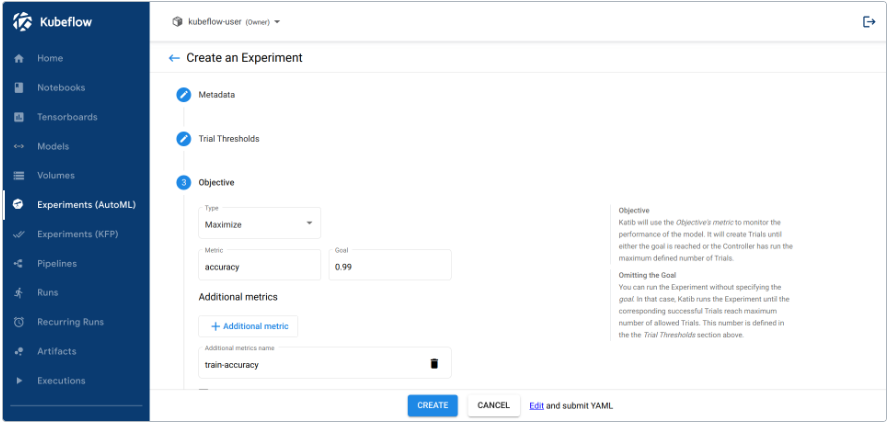
在 Katib UI 中查看实验结果:
- 您应该能够查看实验列表:
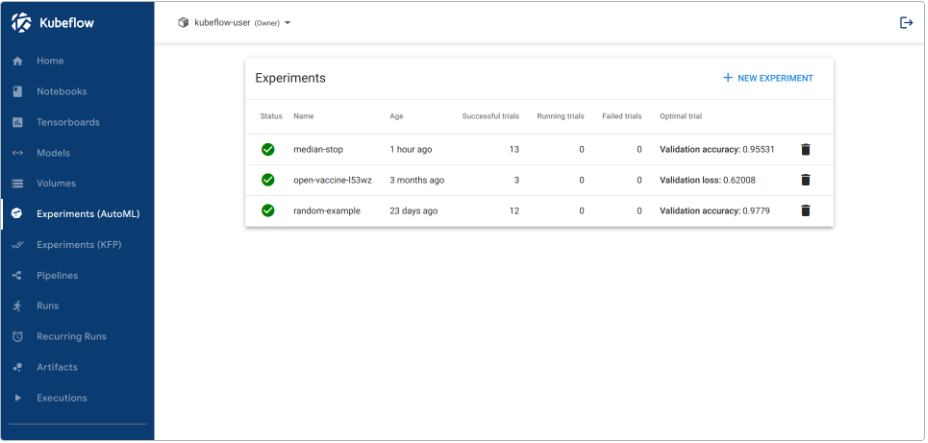
2、单击实验的名称。例如,单击随机示例。
3、应该有一个图表显示超参数值(学习率、层数和优化器)的各种组合的验证水平和训练精度:
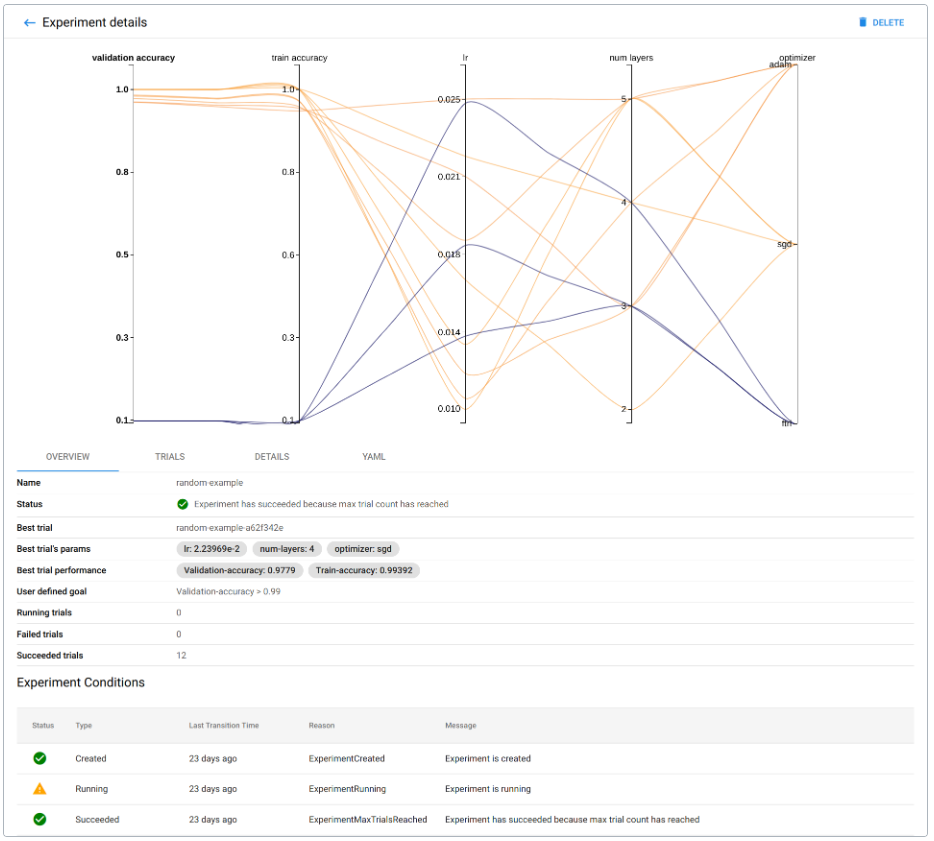
4、下图是实验中进行的试验列表:
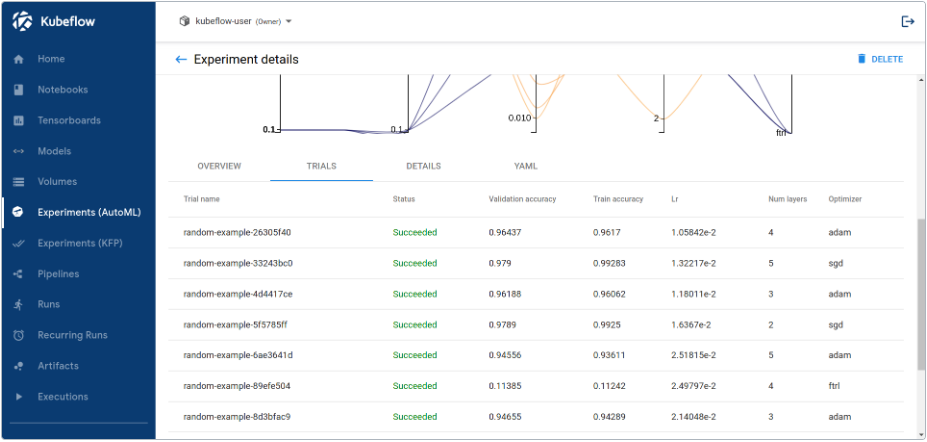
5、您可以单击试用名称以获取特定试用的指标:
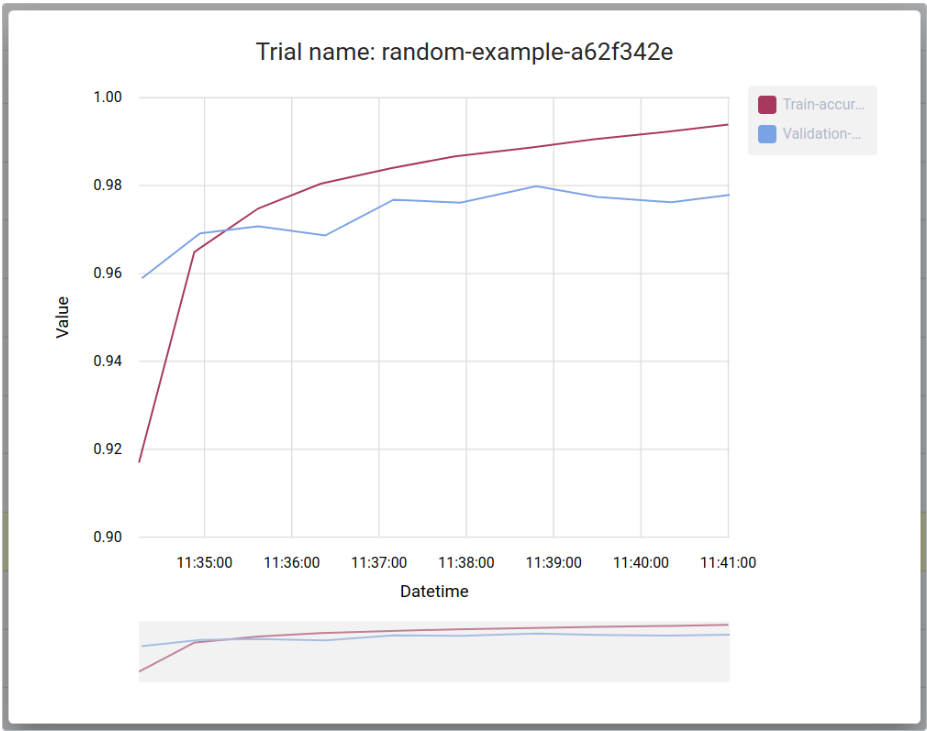
恢复实验
如何重新启动和修改正在运行的实验
本指南介绍了如何修改正在运行的实验并重新启动已完成的实验。您将了解如何更改实验执行过程,并为 Katib 实验使用各种恢复策略。
有关如何配置和运行实验的详细信息,请参阅运行实验指南。
修改运行实验
当实验运行时,您可以更改试验计数参数。例如,可以减少并行训练的超参数集的最大数量。
您只能更改 parallelTrialCount、maxTrialCount 和 maxFailedTrialCount 实验参数。
使用 Kubernetes API 或 kubectl 就地更新资源来进行实验更改。例如,运行:
如何在 Katib 中配置和运行超参数调谐或神经架构搜索实验
# 3.4.4.恢复实验
如何重新启动和修改正在运行的实验
本指南介绍了如何修改正在运行的实验并重新启动已完成的实验。您将了解如何更改实验执行过程,并为 Katib 实验使用各种恢复策略。
有关如何配置和运行实验的详细信息,请参阅运行实验指南。
# 3.4.4.1.修改运行实验
当实验运行时,您可以更改试验计数参数。例如,可以减少并行训练的超参数集的最大数量。
您只能更改 parallelTrialCount、maxTrialCount 和 maxFailedTrialCount 实验参数。
使用 Kubernetes API 或 kubectl 就地更新资源来进行实验更改。例如,运行:
kubectl edit experiment <experiment-name> -n <experiment-namespace>
进行适当的更改并保存。控制器自动处理新参数并进行必要的更改。
- 如果要增加或减少并行测试执行,请修改 parallelTrialCount。控制器相应地根据 parallelTrialCount 值创建或删除试验。
- 如果要增加或减少最大试用计数,请修改 maxTrialCount。maxTrialCount 应大于成功试用的当前计数。如果在实验达到目标或 maxFailedTrialCount 之前,您的实验应该以并行试验的并行 TrialCount 无限运行,则可以删除 maxTrialCount 参数
- 如果要增加或减少最大失败尝试计数,请修改 maxFailedTrialCount。如果实验不应达到失败状态,则可以删除 maxFailedTrialCount 参数。
# 3.4.4.2.继续成功的实验
Katib 实验只有在处于“成功”状态时才能重新启动,因为已达到 maxTrialCount。要检查当前的实验状态,请运行:kubectl get experience < experience name >-n < experiment namespace >。
要重新启动实验,您只能如上所述更改 parallelTrialCount、maxTrialCount 和 maxFailedTrialCount
要控制各种恢复策略,可以为实验指定.spec.resumePolicy。请参阅恢复策略类型。
恢复策略:从不
如果您的实验在任何时候都不应恢复,请使用此策略。实验完成后,建议的部署和服务将被删除,您无法重新启动实验。在概览指南中了解有关 Katib 概念的更多信息。
查看 never-resume.yaml 示例以了解更多详细信息。
恢复策略:LongRunning
如果要重新启动实验,请使用此策略。实验完成后,建议的部署和服务保持运行。修改实验的尝试计数参数以重新开始实验。
删除实验时,建议的部署和服务将被删除。
这是所有 Katib 实验的默认策略。您可以省略该功能的.spec.resumePolicy 参数。
恢复策略:FromVolume
如果要重新启动实验,请使用此策略。在这种情况下,卷附加到建议的部署。
除了建议的部署和服务外,Katib 控制器还创建 Persistent Volume Claim(PVC)。
注意:您的 Kubernetes 集群必须具有用于动态卷配置的 StorageClass,才能自动为创建的 PVC 配置存储。否则,您必须在 Katib 配置设置中定义建议的 Persistent Volume(PV)规范,Katib 控制器将创建 PVC 和 PV。按照 Katib 配置指南设置建议的音量设置。
- PVC 在建议命名空间中使用名称:<suggestion-name>-<suggestion-algorithm>进行部署。
- PV 以以下名称部署:<suggestion-name>-<suggestion-algorithm>-<suggestion-namespace>
实验完成后,建议的部署和服务将被删除。建议数据可保留在卷中。重新启动实验时,将创建建议的部署和服务,并且可以从卷中恢复建议统计信息。
删除实验时,建议的部署、服务、PVC 和 PV 将自动删除。
有关详细信息,请查看 from-volume-resume.yaml 示例。
# 3.4.5.试用模板概述
如何在 Katib 中指定试用模板参数并支持自定义资源(CRD)
本指南介绍了如何在 Katib 中配置试用模板参数和使用自定义 Kubernetes CRD。您将了解如何更改试用模板规范,如何使用 Kubernetes ConfigMaps 存储模板,以及如何修改 Katib 控制器以在 Katib 实验中支持 Kubernete CRD。
Katib 在上游有以下 CRD 示例:
- Kubernetes Job
- Kubeflow TFJob
- Kubeflow PyTorchJob
- Kubeflow MXJob
- Kubeflow XGBoostJob
- Kubeflow MPIJob
- Tekton Pipelines
- Argo Workflows
要使用您自己的 Kubernetes 资源,请遵循以下步骤。
有关如何配置和运行实验的详细信息,请参阅运行实验指南^132 (opens new window)。
# 3.4.5.1.使用试用模板提交实验
要运行 Katib 实验,您必须为正在进行实际训练的工人工作指定一个试用模板。在概览指南中了解有关 Katib 概念的更多信息。
# 3.4.5.1.1.配置试用模板规范
试验模板规范位于试验的.spec.trialTemplate 下。有关 API 概述,请参阅 TrialTemplate 类型。
要定义实验的试验,应在.spec.trialTemplate 中指定以下参数:
- trialParameters-在实验执行过程中在试验模板中使用的参数列表。
**注意:**试用模板必须包含 trialParameters 中的每个参数。您可以在模板的任何字段中设置这些参数,但.metadata.name 和.metadata.namespace 除外。请检查以下如何在模板中使用试用元数据参数。例如,训练容器可以将超参数作为命令行或参数或环境变量接收。
您的实验建议在运行试验之前生成 trialParameters。每个 trialParameter 具有以下结构:
- name-模板中替换的参数名称。
- description(可选)-参数的描述。
- reference-实验建议返回的参数名称。通常,对于超参数调谐参数参考等于实验搜索空间。例如,在网格示例中,搜索空间有三个参数(lr、num 层和优化器),trialParameters 包含引用中的每个参数。
- 您必须在 trialSpec 或 configMap 源中定义实验的试用模板。
**注意:**模板必须省略.metadata.name 和.metadata.namespace。
要从 trialParameters 设置参数,需要在模板中使用以下表达式:${trialParameters.<parametername>}。Katib 自动将其替换为实验建议中的适当值。
例如,--lr=${trialParameters.learningRate}是 learningRate 参数。
- trialSpec-非结构化格式的试验模板。模板应为有效的 YAML。检查网格示例。
- configMap-Kubernetes configMap 规范,实验的试用模板位于该规范中。此 ConfigMap 必须具有标签 katib.kubeflow.org/component:trial templates,并包含键值对,其中 key:<template-name>,value:<templateyaml>。检查带有试用模板的 ConfigMap 示例。
- configMap 规范应具有:
- configMapName-带有试用模板的 ConfigMap 名称。
- configMapNamespace-带有试用模板的 ConfigMap 命名空间。
- templatePath-模板的 ConfigMap 数据路径。
检查试用模板的 ConfigMap 源示例。
以下.spec.trialTemplate 参数用于控制试用行为。如果参数具有默认值,则可以在实验 YAML 中省略。
retain -表示在审判完成后,审判的资源没有得到清理。检查带有 retain:true 参数的示例。
默认值为 false
primaryPodLabels -试用工作人员的 Pod 或 Pods 标签。这些 Pod 由 Katib 度量收集器注入。
注意:如果省略了 primaryPodLabels,则度量收集器将包装所有工作人员的 Pod。在运行实验指南中了解有关 Katib 度量收集器的更多信息。使用 primaryPodLabels 检查示例。
Kubeflow TFJob、PyTorchJob、MXJob 和 XGBoostJob 的默认值为 job role:master
primaryPodLabels 默认值仅在.spec.trialTemplate.trialSpec 中指定模板时有效。对于 configMap 模板源,必须手动设置 primaryPodLabel。
primaryContainerName -运行实际模型训练的训练容器名称。Katib 度量收集器包装此容器以收集单个实验优化步骤所需的度量。
successCondition -试用工作已成功的试用工作人员的对象状态。此条件必须为 GJSON 格式。使用 successCondition 检查示例。
Kubernetes Job 的默认值为 status.conditions.#(type==“Complete”)#|#(status==“True”)#
Kubeflow TFJob、PyTorchJob、MXJob 和 XGBoostJob 的默认值为 status。conditions。#(type==“Successed”)#|#(status==“True”)#
successCondition 默认值仅在.spec.trialTemplate.trialSpec 中指定模板时有效。对于 configMap 模板源,必须手动设置 successCondition。
failureCondition -试用工作失败的试用工作人员的对象状态。此条件必须为 GJSON 格式。使用 failureCondition 检查示例。
Kubernetes 作业的默认值为 status.conditions.#(type==“Failed”)#|#(status==“True”)#
Kubeflow TFJob、PyTorchJob、MXJob 和 XGBoostJob 的默认值为 status。conditions。#(类型==“失败”)#|#(状态==“True”)#
failureCondition 默认值仅在.spec.trialTemplate.trialSpec 中指定模板时有效。对于 configMap 模板源,必须手动设置 failureCondition。
# 3.4.5.1.2.在模板中使用试用元数据
您不能在试用模板中指定.metadata.name 和.metadata.namespace,但可以在实验运行期间获取此数据。例如,如果您想将试用的名称附加到模型存储中。
为此,请将.trilParameters[x].reference 指向适当的元数据参数,并在试用模板中使用.trilParameter[x].name。
下表显示了.trilParameters[x].reference 值和试用元数据之间的关系。
| Reference | Trial metadata |
|---|---|
| ${trialSpec.Name} | Trial name |
| ${trialSpec.Namespace} | Trial namespace |
| ${trialSpec.Kind} | Kubernetes resource kind for the trial's worker |
| ${trialSpec.APIVersion} | Kubernetes resource APIVersion for the trial's worker |
| ${trialSpec.Labels[custom-key]} | Trial's worker label with custom-key key |
| ${trialSpec.Annotations[custom-key]} | Trial's worker annotation with custom-key key |
# 3.4.5.1.3.使用自定义 Kubernetes 资源作为试用模板
在 Katib 示例中,您可以找到以下试用工作程序类型:Kubernetes Job、Kubeflow TFJob、Kubreflow PyTorchJob、Kuboflow MXJob、Kuberlow XGBoostJob、Kubflow MPIJob、Tekton Pipelines 和 Argo Workflows。
可以使用您自己的 Kubernetes CRD 或其他 Kubernete 资源(例如 KubernetesDeployment)作为试用工作人员,而无需修改 Katib 控制器源代码并构建新映像。只要您的 CRD 创建 Kubernetes Pods,允许在这些 Pods 上注入 sidecar 容器,并且处于成功和失败状态,您就可以在 Katib 中使用它。
为此,您需要在 Kubernetes 集群上安装 Katib 组件之前对其进行修改。因此,您必须知道 CRD API 组和版本,CRD 对象的类型。此外,您需要知道创建自定义对象的资源。查看 Kubernetes 指南以了解有关 CRD 的更多信息。
按照以下两个简单步骤将自定义 CRD 集成到 Katib 中:
1、使用新规则修改 Katib 控制器 ClusterRole 的规则,以允许 Katib 访问试用创建的所有资源。要了解有关 ClusterRole 的更多信息,请查看 Kubernetes 指南。
对于 Tekton Pipelines,先创建 Tekton PipelineRun,然后创建 TektonTaskRun。因此,Katib 控制器 ClusterRole 应该可以访问流水线和任务运行:
- apiGroups:
- tekton.dev
resources:
- pipelineruns
- taskruns
verbs:
- "*"
2、使用新标志修改 Katib 控制器部署的参数:--try-resources=<objectkind><对象 API 版本><对象 API 组>。
例如,要支持 Tekton 管道:
- "--trial-resources=PipelineRun.v1beta1.tekton.dev"
完成这些更改后,按照入门指南中的描述部署 Katib,并等待创建 Katib 控制器 Pod。您可以从 Katib 控制器检查日志以验证资源集成:
$ kubectl logs $(kubectl get pods -n kubeflow -o name | grep katib-controller) -n kubeflow | grep '"CRD Kind":"PipelineRun"'
{"level":"info","ts":1628032648.6285546,"logger":"trial-controller","msg":"Job watch added successfully","CRD Group":"tekton.dev","CRD Version":"v1beta1","CRD Kind":"PipelineRun"}
如果您成功地运行了以上步骤,您应该能够在实验的试用模板源规范中使用自定义对象 YAML。
我们感谢您对在 Katib 中使用各种 CRD 的反馈。如果你能让我们知道你的实验,那就太好了。开发人员指南是了解如何为项目做出贡献的良好起点。
# 3.4.6.使用提前停止
如何在 Katib 实验中使用早期停止
本指南介绍了如何使用提前停止来改进 Katib 实验。提前停止可以避免在 Katib 实验期间训练模型时过度拟合。当目标指标在训练过程完成之前不再改善时,它还可以通过停止试验来节省计算资源和减少实验执行时间。
在 Katib 中使用提前停止的主要优点是不需要修改训练容器包。您所要做的就是对实验的 YAML 文件进行必要的更改。
提前停止与 Katib 的指标收集器的工作方式相同。它从标准输出或任意输出文件中分析所需的指标,并使用提前停止算法来决定是否需要停止试验。目前,提前停止仅适用于 StdOut 或文件度量收集器。
注意:您的训练容器必须打印带有时间戳的训练日志,因为早期停止算法需要知道报告的度量的序列。查看 MXNet 示例,了解如何将日期格式添加到日志中。
# 3.4.6.1.将实验配置为提前停止
作为参考,您可以使用早期停止示例的 YAML 文件。
1、按照指南配置 Katib 实验。
2、接下来,要为实验应用早期停止,请指定.spec.eearlyStopping 参数,类似于.spec 算法。有关详细信息,请参阅 EarlyStoppingSpec 类型。
- .eearlyStopping.algorithName-早期停止算法的名称。
- .eearlyStopping.algorithSettings-早期停止算法的设置。
结果是你的实验建议产生了新的试验。之后,早期停止算法为创建的试验生成早期停止规则。一旦试用达到所有规则,它将停止,试用状态将更改为 EarlyStopped。然后,Katib 再次提出建议,要求进行新的试验。
在概览指南中了解有关 Katib 概念的更多信息。
按照 Katib 配置指南为早期停止算法指定自己的图像。
# 3.4.6.2.详细介绍早期停止算法
以下是 Katib 中可用的早期停止算法列表:
中值停止规则
更多的算法正在开发中。
你可以自己给 Katib 添加一个早期停止算法。查看开发人员指南以作出贡献。
# 3.4.7.Katib 配置概述
如何更改 Katib 配置
本指南介绍了 Katib config-Kubernetes 配置映射,其中包含以下信息:
- 当前度量收集器(metrics collectors)^133 (opens new window)(key = metrics-collector-sidecar)。
- 当前算法(建议)^134 (opens new window)(key = suggestion)。
- 当前的早期停止算法(key = early-stopping)。
Katib 配置映射必须使用 Katib 配置名称部署在 Katib_CORE_NAMESPACE 命名空间中。提交实验时,Katib 控制器解析 Katib 配置。
您甚至可以在部署 Katib 后编辑此配置映射。
如果您正在 Kubeflow 命名空间中部署 Katib,请运行以下命令编辑 Katib 配置:
kubectl edit configMap katib-config -n kubeflow
# 3.4.7.1.指标收集器侧车设置
这些设置与 Katib 度量采集器相关,其中:
- 关键字:metrics-collector-sidecar
- value:每个度量收集器类型的对应 JSON 设置
具有所有设置的File度量收集器示例:
metrics-collector-sidecar: |-
{
"File": {
"image": "docker.io/kubeflowkatib/file-metrics-collector",
"imagePullPolicy": "Always",
"resources": {
"requests": {
"memory": "200Mi",
"cpu": "250m",
"ephemeral-storage": "200Mi"
},
"limits": {
"memory": "1Gi",
"cpu": "500m",
"ephemeral-storage": "2Gi"
}
},
"waitAllProcesses": false
},
...
}
除图像外,所有这些设置都可以省略。如果未指定任何其他设置,将自动设置默认值。
1. image -File metrics 收集器容器的 Docker 图像(必须指定)。
2. imagePullPolicy -文件度量收集器容器的图像拉取策略^135 (opens new window)。默认值为 IfNotPresent。
3. resources -文件度量收集器容器的资源。在上面的示例中,您可以检查如何指定限制和请求。目前,您只能指定 memory、cpu 和 ephemeral-storage 资源。
requests 的默认值为:
- memory = 10Mi
- cpu = 50m
- ephemeral-storage = 500Mi
limits 的默认值为:
- memory = 100Mi
- cpu = 500m
- ephemeral-storage = 5Gi
您可以运行度量收集器的容器,而无需从 Kubernetes 集群请求 cpu、memory 或 ephemeral-storage。例如,您必须从容器资源中删除临时存储,才能使用 Google Kubernetes Engine 集群自动缩放器。
要从度量收集器的容器中删除特定资源,请在 Katib 配置中设置请求和限制中的负值,如下所示:
"requests": {
"cpu": "-1",
"memory": "-1",
"ephemeral-storage": "-1"
},
"limits": {
"cpu": "-1",
"memory": "-1",
"ephemeral-storage": "-1"
}
- waitAllProcesses -一个标志,用于定义度量收集器是否应该等到训练容器中的所有进程完成后才开始收集度量。默认值为 true。
# 3.4.7.2.建议设置
这些设置与 Katib 建议相关,其中:
- 关键字:suggestion
- value:每个算法名称对应的 JSON 设置
如果要使用新算法,需要更新 Katib 配置。例如,对所有设置使用随机算法如下所示:
suggestion: |-
{
"random": {
"image": "docker.io/kubeflowkatib/suggestion-hyperopt",
"imagePullPolicy": "Always",
"resources": {
"requests": {
"memory": "100Mi",
"cpu": "100m",
"ephemeral-storage": "100Mi"
},
"limits": {
"memory": "500Mi",
"cpu": "500m",
"ephemeral-storage": "3Gi"
}
},
"serviceAccountName": "random-sa"
},
...
}
除图像外,所有这些设置都可以省略。如果未指定任何其他设置,将自动设置默认值。
1. image-带有随机算法的建议容器的 Docker 图像(必须指定)。
图像示例:docker.io/kubeflowkatib/<suggestion-name>
对于每个算法(建议),您可以在 Docker 图像中指定以下建议名称之一:
| Suggestion name | List of supported algorithms | Description |
|---|---|---|
| suggestion-hyperopt | random, tpe | Hyperopt (opens new window) optimization framework |
| suggestion-chocolate | grid, random, quasirandom, bayesianoptimization, mocmaes | Chocolate (opens new window) optimization framework |
| suggestion-skopt | bayesianoptimization | Scikit-optimize (opens new window) optimization framework |
| suggestion-goptuna | cmaes, random, tpe, sobol | Goptuna (opens new window) optimization framework |
| suggestion-optuna | multivariate-tpe, tpe, cmaes, random | Optuna (opens new window) optimization framework |
| suggestion-hyperband | hyperband | Katib Hyperband (opens new window) implementation |
| suggestion-pbt | pbt | Katib PBT (opens new window) implementation |
| suggestion-enas | enas | Katib ENAS (opens new window) implementation |
| suggestion-darts | darts | Katib DARTS (opens new window) implementation |
# 3.4.8.Katib 组件的环境变量
如何为每个 Katib 组件设置环境变量
本指南描述了每个 Katib 组件的环境变量。如果要更改 Katib 安装,可以修改其中的一些变量。
在下表中,您可以找到每个 Katib 组件中所有环境变量的描述、默认值和强制属性。如果变量具有强制属性,则需要在适当的 Katib 组件清单中设置相关的环境变量。
# 3.4.8.1.Katib 控制器
下面是 Katib 控制器部署的环境变量:
| Variable | Description | Default Value | Mandatory |
|---|---|---|---|
| KATIB_CORE_NAMESPACE | Base Namespace for all Katib components and default Experiment | metadata.namespace | Yes |
| KATIB_SUGGESTION_COMPOSER | Composer (opens new window) for the Katib Suggestions. You can use your own Composer | general | No |
| KATIB_DB_MANAGER_SERVICE_NAMESPACE | Katib DB Manager Namespace | KATIB_CORE_NAMESPACE env variable | No |
| KATIB_DB_MANAGER_SERVICE_IP | Katib DB Manager IP | katib-db-manager | No |
| KATIB_DB_MANAGER_SERVICE_PORT | Katib DB Manager Port | 6789 | No |
Katib Controller 使用以下地址表达式调用 Katib DB Manager:
KATIB_DB_MANAGER_SERVICE_IP.KATIB_DB_MANAGER_SERVICE_NAMESPACE:KATIB_DB_MANAGER_SERVICE_PORT
如果设置 KATIB_DB_MANAGER_SERVICE_NAMESPACE=“”,KATIB 控制器将使用以下地址调用 KATIB DB MANAGER:
KATIB_DB_MANAGER_SERVICE_IP:KATIB_DB_MANAGER_SERVICE_PORT
如果要使用自己的数据库管理器来报告 Katib 指标,可以更改 Katib_DB_Manager_SERVICE_NAMESPACE、Katib_VB_Manager_SERVICE_IP 和 Katib_DB_Manager_SRVICE_PORT 变量。
# 3.4.8.2.Katib UI
| ariable | Description | Default Value | Mandatory |
|---|---|---|---|
| KATIB_CORE_NAMESPACE | Base Namespace for all Katib components and default Experiment | metadata.namespace | Yes |
| KATIB_DB_MANAGER_SERVICE_NAMESPACE | Katib DB Manager Namespace | KATIB_CORE_NAMESPACE env variable | No |
| KATIB_DB_MANAGER_SERVICE_IP | Katib DB Manager IP | katib-db-manager | No |
| KATIB_DB_MANAGER_SERVICE_PORT | Katib DB Manager Port | 6789 | No |
Katib UI 使用与 Katib Controller 相同的地址表达式调用 Katib DB Manager。
# 3.4.8.3.Katib DB Manager
| Variable | Description | Default Value | Mandatory |
|---|---|---|---|
| DB_NAME | Katib DB Name: 'mysql' or 'postgres' | Yes | |
| DB_PASSWORD | Katib DB Password | test (MySQL) katib (Postgres) | Yes |
| DB_USER | Katib DB User | root (MySQL) katib (Postgres) | No |
| KATIB_MYSQL_DB_HOST | Katib MySQL Host | katib-mysql | No |
| KATIB_MYSQL_DB_PORT | Katib MySQL Port | 3306 | No |
| KATIB_MYSQL_DB_DATABASE | Katib MySQL Database name | katib | No |
| KATIB_POSTGRESQL_DB_HOST | Katib Postgres Host | katib-postgres | No |
| KATIB_POSTGRESQL_DB_PORT | Katib Postgres Port | 5432 | No |
| KATIB_POSTGRESQL_DATABASE | Katib Postgres Database name | katib | No |
Currently, Katib DB Manager supports only MySQL and Postgres database. (DB_NAME env variable must be filled with one of mysql or postgres)
However, you can use your own DB Manager and Database to report metrics by implements the katib db interface.
For the Katib DB Manager you can change DB_PASSWORD to your own DB password.
Katib DB Manager creates DB connection to the DB by the type of DB.
If DB_NAME=mysql, it uses mysql driver and this data source name:
DB_USER:DB_PASSWORD@tcp(KATIB_MYSQL_DB_HOST:KATIB_MYSQL_DB_PORT)/KATIB_MYSQL_DB_DATABASE?timeout=5s
If DB_NAME=postgres, it uses pq driver and this data source name:
postgresql://[DB_USER[:DB_PASSWORD]@][KATIB_POSTGRESQL_DB_HOST][:KATIB_POSTGRESQL_DB_PORT][/KATIB_POSTGRESQL_DB_DATABASE]
# 3.4.8.4.Katib 数据库
Katib DB 组件支持 MySQL 和 Postgres。
# 3.4.8.4.1.Katib MySQL
对于 Katib MySQL,您需要设置以下环境变量:
- MYSQL_ROOT_PASSWORD 转换为 katib MYSQL secrets 中的值,等于“test”。
- MYSQL_ALLOW_EMPTY_PASSWORD true
- MYSQL_DATABASE 作为 katib。
您可以参考 MySQL Docker 映像的所有环境变量列表^136 (opens new window)。
Katib MySQL 环境变量必须与 Katib DB Manager 环境变量匹配,这意味着:
- MYSQL_ROOT_PASSWORD= DB_PASSWORD
- MYSQL_DATABASE=KATIB_MYSQL_DB_DATABASE
# 3.4.8.4.2.Katib Postgres
对于 Katib Postgres,您需要设置以下环境变量:
- POSTGRES_USER、POSTGRES_PASSWORD 和 POSTGRES_DB 转换为 katib POSTGRES secrets 中的值,该值等于“katib”。
您可以参考 Postgres Docker 映像的所有环境变量列表^137 (opens new window)。
Katib Postgres 环境变量必须与 Katib DB Manager 环境变量匹配,这意味着:
- POSTGRES_USER = DB_USER
- POSTGRES_PASSWORD = DB_PASSWORD
- POSTGRES_DB = KATIB_POSTGRESQL_DB_DATABASE
# 3.4.9.Training Operators
本页介绍使用 TensorFlow 训练机器学习模型的 TFJob。
# 3.4.9.1.TensorFlow Training (TFJob)
# 3.4.9.1.1.什么是 TFJob?
TFJob 是一个 Kubernetes 自定义资源,用于在 Kubernete 上运行 TensorFlow 训练作业。TFJob 的 Kubeflow 实现是在训练操作员。
注意:由于 Istio 自动 sidecar 注入,TFJob 在默认情况下不在用户命名空间中工作。为了让 TFJob 运行,它需要注释 sidecar.istio.io/inject:“false”来为 TFJob pods 禁用它。
TFJob 是一种具有 YAML 表示形式的资源,如下所示(编辑以使用容器图像和命令编写自己的训练代码):
apiVersion: kubeflow.org/v1
kind: TFJob
metadata:
generateName: tfjob
namespace: your-user-namespace
spec:
tfReplicaSpecs:
PS:
replicas: 1
restartPolicy: OnFailure
template:
metadata:
annotations:
sidecar.istio.io/inject: "false"
spec:
containers:
- name: tensorflow
image: gcr.io/your-project/your-image
command:
- python
- -m
- trainer.task
- --batch_size=32
- --training_steps=1000
Worker:
replicas: 3
restartPolicy: OnFailure
template:
metadata:
annotations:
sidecar.istio.io/inject: "false"
spec:
containers:
- name: tensorflow
image: gcr.io/your-project/your-image
command:
- python
- -m
- trainer.task
- --batch_size=32
- --training_steps=1000
如果您想让 TFJob pod 访问凭据机密,例如在执行基于 GKE 的 Kubeflow 安装时自动创建的 GCP 凭据,您可以装载并使用如下机密:
apiVersion: kubeflow.org/v1
kind: TFJob
metadata:
generateName: tfjob
namespace: your-user-namespace
spec:
tfReplicaSpecs:
PS:
replicas: 1
restartPolicy: OnFailure
template:
metadata:
annotations:
sidecar.istio.io/inject: "false"
spec:
containers:
- name: tensorflow
image: gcr.io/your-project/your-image
command:
- python
- -m
- trainer.task
- --batch_size=32
- --training_steps=1000
env:
- name: GOOGLE_APPLICATION_CREDENTIALS
value: "/etc/secrets/user-gcp-sa.json"
volumeMounts:
- name: sa
mountPath: "/etc/secrets"
readOnly: true
volumes:
- name: sa
secret:
secretName: user-gcp-sa
Worker:
replicas: 1
restartPolicy: OnFailure
template:
metadata:
annotations:
sidecar.istio.io/inject: "false"
spec:
containers:
- name: tensorflow
image: gcr.io/your-project/your-image
command:
- python
- -m
- trainer.task
- --batch_size=32
- --training_steps=1000
env:
- name: GOOGLE_APPLICATION_CREDENTIALS
value: "/etc/secrets/user-gcp-sa.json"
volumeMounts:
- name: sa
mountPath: "/etc/secrets"
readOnly: true
volumes:
- name: sa
secret:
secretName: user-gcp-sa
如果您不熟悉 Kubernetes 资源,请参阅了解 KubernetesObjects 页面。
TFJob 与内置控制器的不同之处在于,TFJob 规范旨在管理分布式 TensorFlow 训练作业。
分布式 TensorFlow 作业通常包含以下 0 个或多个进程
- Chief : Chief 负责组织训练和执行检查模型等任务。
- Ps Ps 是参数服务器;这些服务器为模型参数提供分布式数据存储。
- Worker Worker 做训练模特的实际工作。在某些情况下,工人 0 也可能担任主管。
- Evaluator Evaluator 可用于在模型训练时计算评估度量。
TFJob 规范中的字段 tfReplicaSpecs 包含从副本类型(如上所列)到该副本的 TFReplicaSpec 的映射。TFReplicaSpec 由 3 个字段组成
- replicas 要为此 TFJob 生成的此类型副本的数量。
- template 描述要为每个副本创建的 pod 的 PodTemplateSpec^138 (opens new window)。pod 必须包含一个名为 tensorflow 的容器。
- restartPolicy 确定 pod 退出时是否重新启动。允许值如下
- 始终意味着吊舱将始终重新启动。此策略适用于参数服务器,因为它们从不退出,并且在发生故障时应始终重新启动。
- OnFailure 表示如果 pod 因故障退出,吊舱将重新启动。
- 非零退出代码表示失败。
- 退出代码 0 表示成功,吊舱将不会重新启动。
- 这项政策对chief 和workers都有好处。
- ExitCode 表示重新启动行为取决于 tensorflow 容器的退出代码,如下所示:
- 退出代码 0 表示进程已成功完成,不会重新启动。
- 以下退出代码表示永久错误,容器将不会重新启动:
- 1: 一般性错误
- 2: 壳内件的误用
- 126:调用的命令无法执行
- 127:找不到命令
- 128:退出的参数无效
- 139:容器被 SIGSEGV 终止(内存引用无效)
- 以下退出代码表示可重试错误,容器将重新启动:
- 130:由 SIGINT 终止的容器(键盘 Control-C)
- 137:容器收到 SIGKILL
- 143:容器收到 SIGTERM
- 退出代码 138 对应于 SIGUSR1,并为用户指定的可重试错误保留。
- 其他退出代码未定义,无法保证其行为。
有关退出代码的背景信息,请参阅 GNU 终止信号指南和 Linux 文档项目。
- Never 意味着终止的 pod 将永远不会重新启动。这个策略应该很少使用,因为 Kubernetes 会因为各种原因(例如节点变得不健康)终止 pod,这将阻止作业恢复。
# 3.4.9.1.2.安装 TensorFlow 运算符
如果您还没有这样做,请按照《入门指南》部署 Kubeflow。
- 默认情况下,TFJob 操作员将被部署为训练操作员的控制器。
如果您想安装没有 Kubeflow 的独立版本的训练操作员,请参阅 Kubeflow/training 操作员的自述文件。
验证 Kubeflow 部署中是否包含 TFJob 支持
检查 TensorFlow 自定义资源是否已安装:
kubectl get crd
输出应包括 tfjobs.kubeflow.org,如下所示:
NAME CREATED AT
...
tfjobs.kubeflow.org 2021-09-06T18:33:58Z
...
检查训练操作员是否通过以下方式运行:
kubectl get pods -n kubeflow
输出应包括训练操作员 xxx,如下所示:
NAME READY STATUS RESTARTS AGE
training-operator-d466b46bc-xbqvs 1/1 Running 0 4m37s
# 3.4.9.1.3.运行 Mnist 示例
请参阅分布式 MNIST 示例的清单。您可以根据需要更改配置文件。
部署 TFJob 资源以开始训练:
kubectl create -f https://raw.githubusercontent.com/kubeflow/training-operator/master/examples/tensorflow/simple.yaml (opens new window)
监控作业(请参阅下面的详细指南):
kubectl -n kubeflow get tfjob tfjob-simple -o yaml
Delete it
kubectl -n kubeflow delete tfjob tfjob-simple
# 3.4.9.1.4.自定义 TFJob
通常,可以在 TFJob yaml 文件中更改以下值:
- 更改图像以指向包含代码的 docker 图像
- 更改副本的数量和类型
- 更改分配给每个资源的资源(请求和限制)
- 设置任何环境变量
- 例如,您可能需要配置各种环境变量以与 GCS 或 S3 等数据存储进行通信
- 如果要将 PV 用于存储,请连接 PV。
# 3.4.9.1.5.使用 GPU
要使用 GPU,必须将集群配置为使用 GPU。
- 节点必须连接 GPU。
- Kubernetes 集群必须识别 nvidia.com/gpu 资源类型。
- GPU 驱动程序必须安装在群集上。
- 有关详细信息:
- 用于调度 GPU 的 Kubernetes 指令^139 (opens new window)
- GKE 说明^140 (opens new window)
- EKS 指令^141 (opens new window)
要附加 GPU,请在应包含 GPU 的副本中指定容器上的 GPU 资源;例如
apiVersion: "kubeflow.org/v1"
kind: "TFJob"
metadata:
name: "tf-smoke-gpu"
spec:
tfReplicaSpecs:
PS:
replicas: 1
template:
metadata:
creationTimestamp: null
spec:
containers:
- args:
- python
- tf_cnn_benchmarks.py
- --batch_size=32
- --model=resnet50
- --variable_update=parameter_server
- --flush_stdout=true
- --num_gpus=1
- --local_parameter_device=cpu
- --device=cpu
- --data_format=NHWC
image: gcr.io/kubeflow/tf-benchmarks-cpu:v20171202-bdab599-dirty-284af3
name: tensorflow
ports:
- containerPort: 2222
name: tfjob-port
resources:
limits:
cpu: "1"
workingDir: /opt/tf-benchmarks/scripts/tf_cnn_benchmarks
restartPolicy: OnFailure
Worker:
replicas: 1
template:
metadata:
creationTimestamp: null
spec:
containers:
- args:
- python
- tf_cnn_benchmarks.py
- --batch_size=32
- --model=resnet50
- --variable_update=parameter_server
- --flush_stdout=true
- --num_gpus=1
- --local_parameter_device=cpu
- --device=gpu
- --data_format=NHWC
image: gcr.io/kubeflow/tf-benchmarks-gpu:v20171202-bdab599-dirty-284af3
name: tensorflow
ports:
- containerPort: 2222
name: tfjob-port
resources:
limits:
nvidia.com/gpu: 1
workingDir: /opt/tf-benchmarks/scripts/tf_cnn_benchmarks
restartPolicy: OnFailure
按照 TensorFlow 的说明使用 GPU^142 (opens new window)。
# 3.4.9.1.6.监控您的 Job
获取工作状态
kubectl -n kubeflow get -o yaml tfjobs tfjob-simple
下面是示例作业的示例输出
apiVersion: kubeflow.org/v1
kind: TFJob
metadata:
creationTimestamp: "2021-09-06T11:48:09Z"
generation: 1
name: tfjob-simple
namespace: kubeflow
resourceVersion: "5764004"
selfLink: /apis/kubeflow.org/v1/namespaces/kubeflow/tfjobs/tfjob-simple
uid: 3a67a9a9-cb89-4c1f-a189-f49f0b581e29
spec:
tfReplicaSpecs:
Worker:
replicas: 2
restartPolicy: OnFailure
template:
spec:
containers:
- command:
- python
- /var/tf_mnist/mnist_with_summaries.py
image: gcr.io/kubeflow-ci/tf-mnist-with-summaries:1.0
name: tensorflow
status:
completionTime: "2021-09-06T11:49:30Z"
conditions:
- lastTransitionTime: "2021-09-06T11:48:09Z"
lastUpdateTime: "2021-09-06T11:48:09Z"
message: TFJob tfjob-simple is created.
reason: TFJobCreated
status: "True"
type: Created
- lastTransitionTime: "2021-09-06T11:48:12Z"
lastUpdateTime: "2021-09-06T11:48:12Z"
message: TFJob kubeflow/tfjob-simple is running.
reason: TFJobRunning
status: "False"
type: Running
- lastTransitionTime: "2021-09-06T11:49:30Z"
lastUpdateTime: "2021-09-06T11:49:30Z"
message: TFJob kubeflow/tfjob-simple successfully completed.
reason: TFJobSucceeded
status: "True"
type: Succeeded
replicaStatuses:
Worker:
succeeded: 2
startTime: "2021-09-06T11:48:10Z"
# 3.4.9.1.7.条件
TFJob 具有 TFJobStatus,该 TFJobStatus 具有 TFJobConditions 数组,TFJob 已通过或未通过该数组。TFJobCondition 数组的每个元素都有六个可能的字段:
- lastUpdateTime字段提供上次更新此条件的时间。
- lastTransitionTime 字段提供条件从一种状态转换到另一种状态的最后时间。
- 消息字段是一条人类可读的message ,指示有关转换的详细信息。
- reason字段是条件的最后一次转换的唯一的一个单词 CamelCase 原因。
- status 字段是一个可能值为“True”、“False”和“Unknown”的字符串。
- type 字段是具有以下可能值的字符串:
- TFJobCreated 表示 TFJob 已被系统接受,但一个或多个 pod/服务尚未启动。
- TFJobRunning 表示此 TFJob 的所有子资源(例如服务/吊舱)已成功调度和启动,并且作业正在运行。
- TFJobRestarting 表示此 TFJob 的一个或多个子资源(例如服务/pod)出现问题,正在重新启动。
- TFJobSuccessed 表示作业已成功完成。
- TFJobFailed 表示作业已失败。
工作的成败取决于
- 如果一份工作有主管,成败取决于主管的地位。
- 如果一份工作没有主管,成败取决于工人。
- 在这两种情况下,如果正在监视的进程退出,退出代码为 0,则 TFJob 成功。
- 在非零退出代码的情况下,行为由副本的 restartPolicy 决定。
- 如果 restartPolicy 允许重新启动,则流程将重新启动,TFJob 将继续执行。
- 对于 restartPolicy ExitCode,行为取决于退出代码。
- 如果 restartPolicy 不允许重新启动,则非零退出代码将被视为永久失败,作业将被标记为失败。
# 3.4.9.1.8.tfReplicaStatus(tf 复制状态)
tfReplicaStatuses 提供了一个映射,指示给定状态下每个副本的 pod 数量。有三种可能的状态
- Active 是当前正在运行的 pod 数。
- Successed 是成功完成的 pod 数。
- Failed 是以错误完成的 pod 数。
# 3.4.9.1.9.事件
在执行过程中,TFJob 将发出事件以指示正在发生的事情,例如创建/删除 pod 和服务。默认情况下,Kubernetes 不会保留超过 1 小时的事件。查看作业运行的最近事件。
kubectl -n kubeflow describe tfjobs tfjob-simple
这将产生如下输出
Name: tfjob-simple
Namespace: kubeflow
Labels: <none>
Annotations: <none>
API Version: kubeflow.org/v1
Kind: TFJob
Metadata:
Creation Timestamp: 2021-09-06T11:48:09Z
Generation: 1
Managed Fields:
API Version: kubeflow.org/v1
Fields Type: FieldsV1
fieldsV1:
f:spec:
.:
f:tfReplicaSpecs:
.:
f:Worker:
.:
f:replicas:
f:restartPolicy:
f:template:
.:
f:spec:
Manager: kubectl-create
Operation: Update
Time: 2021-09-06T11:48:09Z
API Version: kubeflow.org/v1
Fields Type: FieldsV1
fieldsV1:
f:spec:
f:runPolicy:
.:
f:cleanPodPolicy:
f:successPolicy:
f:tfReplicaSpecs:
f:Worker:
f:template:
f:metadata:
f:spec:
f:containers:
f:status:
.:
f:completionTime:
f:conditions:
f:replicaStatuses:
.:
f:Worker:
.:
f:succeeded:
f:startTime:
Manager: manager
Operation: Update
Time: 2021-09-06T11:49:30Z
Resource Version: 5764004
Self Link: /apis/kubeflow.org/v1/namespaces/kubeflow/tfjobs/tfjob-simple
UID: 3a67a9a9-cb89-4c1f-a189-f49f0b581e29
Spec:
Tf Replica Specs:
Worker:
Replicas: 2
Restart Policy: OnFailure
Template:
Spec:
Containers:
Command:
python
/var/tf_mnist/mnist_with_summaries.py
Image: gcr.io/kubeflow-ci/tf-mnist-with-summaries:1.0
Name: tensorflow
Status:
Completion Time: 2021-09-06T11:49:30Z
Conditions:
Last Transition Time: 2021-09-06T11:48:09Z
Last Update Time: 2021-09-06T11:48:09Z
Message: TFJob tfjob-simple is created.
Reason: TFJobCreated
Status: True
Type: Created
Last Transition Time: 2021-09-06T11:48:12Z
Last Update Time: 2021-09-06T11:48:12Z
Message: TFJob kubeflow/tfjob-simple is running.
Reason: TFJobRunning
Status: False
Type: Running
Last Transition Time: 2021-09-06T11:49:30Z
Last Update Time: 2021-09-06T11:49:30Z
Message: TFJob kubeflow/tfjob-simple successfully completed.
Reason: TFJobSucceeded
Status: True
Type: Succeeded
Replica Statuses:
Worker:
Succeeded: 2
Start Time: 2021-09-06T11:48:10Z
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreatePod 7m9s tfjob-controller Created pod: tfjob-simple-worker-0
Normal SuccessfulCreatePod 7m8s tfjob-controller Created pod: tfjob-simple-worker-1
Normal SuccessfulCreateService 7m8s tfjob-controller Created service: tfjob-simple-worker-0
Normal SuccessfulCreateService 7m8s tfjob-controller Created service: tfjob-simple-worker-1
Normal ExitedWithCode 5m48s (x3 over 5m48s) tfjob-controller Pod: kubeflow.tfjob-simple-worker-1 exited with code 0
Normal ExitedWithCode 5m48s tfjob-controller Pod: kubeflow.tfjob-simple-worker-0 exited with code 0
Normal TFJobSucceeded 5m48s tfjob-controller TFJob kubeflow/tfjob-simple successfully completed.
这里的事件表明 pod 和服务已成功创建。
# 3.4.9.1.10.TensorFlow 日志
logging 遵循标准 K8s logging 实践。
您可以使用 kubectl 获取任何尚未删除的 pod 的标准输出/错误。
首先找到作业控制器为感兴趣的副本创建的 pod。Pods 将被命名
${JOBNAME}-${REPLICA-TYPE}-${INDEX}
一旦你确定了你的 pod,你就可以使用 kubectl 获取日志。
kubectl logs ${PODNAME}
TFJob 规范中的 CleanPodPolicy 控制作业终止时 pod 的删除。策略可以是以下值之一
- 运行策略意味着只有作业完成时仍在运行的 pod(例如参数服务器)才会立即删除;完成的 pod 将不会被删除,这样日志将被保留。这是默认值。
- All 策略意味着当作业完成时,所有 pod(甚至已完成的 pod)都将立即删除。
- None 策略意味着作业完成时不会删除任何 pod。
如果您的集群利用了 Kubernetes 集群日志记录,那么您的日志也可能会被运送到适当的数据存储中以供进一步分析。
# 3.4.9.1.11.GKE 上的 Stackdriver
有关使用 Stackdriver 获取日志的说明,请参阅日志记录和监视指南。如日志记录和监视指南中所述,可以根据 pod 标签获取特定副本的日志。使用 Stackdriver UI,您可以使用如下查询
resource.type="k8s_container"
resource.labels.cluster_name="${CLUSTER}"
metadata.userLabels.job-name="${JOB_NAME}"
metadata.userLabels.replica-type="${TYPE}"
metadata.userLabels.replica-index="${INDEX}"
或者使用 gcloud
QUERY="resource.type=\"k8s_container\" "
QUERY="${QUERY} resource.labels.cluster_name=\"${CLUSTER}\" "
QUERY="${QUERY} metadata.userLabels.job-name=\"${JOB_NAME}\" "
QUERY="${QUERY} metadata.userLabels.replica-type=\"${TYPE}\" "
QUERY="${QUERY} metadata.userLabels.replica-index=\"${INDEX}\" "
gcloud --project=${PROJECT} logging read \
--freshness=24h \
--order asc ${QUERY}
# 3.4.9.1.12.Troubleshooting
以下是排除工作故障的一些步骤
1.您的 job 是否存在状态?运行命令
kubectl -n ${USER_NAMESPACE} get tfjobs -o yaml ${JOB_NAME}
- USER_NAMESPACE 是为用户配置文件创建的命名空间。
- 如果生成的输出不包含作业的状态,则这通常表示作业规范无效。
- 如果 TFJob 规范无效,则 tf 运算符日志中应该有一条日志消息
kubectl -n ${KUBEFLOW_NAMESPACE} logs `kubectl get pods --selector=name=tf-job-operator -o jsonpath='{.items[0].metadata.name}'`
KUBEFLOW_NAMESPACE 是在其中部署 TFJob 运算符的命名空间。
2.检查 job 的事件,以查看是否创建了 pod
获取事件的方法有很多种;如果你的工作时间不到 1 小时,那么你可以
kubectl -n ${USER_NAMESPACE} describe tfjobs ${JOB_NAME}
输出的底部应包含作业发出的事件列表;例如
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreatePod 90s tfjob-controller Created pod: tfjob2-worker-0
Normal SuccessfulCreatePod 90s tfjob-controller Created pod: tfjob2-ps-0
Normal SuccessfulCreateService 90s tfjob-controller Created service: tfjob2-worker-0
Normal SuccessfulCreateService 90s tfjob-controller Created service: tfjob2-ps-0
Kubernetes 只保存事件 1 小时(参见 Kubernetes/kubenetes#52521)
- 根据您的群集设置,事件可能会持久化到外部存储,并可在较长时间内访问
- 在 GKE 上,事件保存在 stackdriver 中,可以使用上一节中的说明进行访问。
如果没有创建 pod 和服务,那么这表明没有处理 TFJob;常见原因是
TFJob 规范无效(请参见上文)
TFJob 运算符未运行
3.检查 pod 的事件,以确保它们被安排好。
获取事件的方法有很多种;如果你的吊舱不到 1 小时,那么你可以
kubectl -n ${USER_NAMESPACE} describe pods ${POD_NAME}
输出的底部应该包含以下事件
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 18s default-scheduler Successfully assigned tfjob2-ps-0 to gke-jl-kf-v0-2-2-default-pool-347936c1-1qkt
Normal SuccessfulMountVolume 17s kubelet, gke-jl-kf-v0-2-2-default-pool-347936c1-1qkt MountVolume.SetUp succeeded for volume "default-token-h8rnv"
Normal Pulled 17s kubelet, gke-jl-kf-v0-2-2-default-pool-347936c1-1qkt Container image "gcr.io/kubeflow/tf-benchmarks-cpu:v20171202-bdab599-dirty-284af3" already present on machine
Normal Created 17s kubelet, gke-jl-kf-v0-2-2-default-pool-347936c1-1qkt Created container
Normal Started 16s kubelet, gke-jl-kf-v0-2-2-default-pool-347936c1-1qkt Started container
可以阻止容器启动的一些常见问题是
资源不足,无法安排 pod
pod 尝试装载不存在或不可用的卷(或机密)
docker 映像不存在或无法访问(例如,由于权限问题)
4.如果 pod 启动;按照上一节中的说明检查容器的日志。
# 3.4.9.2.PaddlePaddle Training (PaddleJob)
本页介绍 PaddleJob 如何使用飞桨训练机器学习模型。
PaddleJob 是 Kubernetes 的自定义资源,用于在 Kubernete 上运行飞桨训练作业。PaddleJob 的 Kubeflow 实现是在训练操作员。
# 3.4.9.2.1.安装飞桨操作器
如果您还没有这样做,请按照《入门指南》部署 Kubeflow。
默认情况下,桨板操作员将被部署为训练操作员的控制器。
如果您想安装没有 Kubeflow 的独立版本的训练操作员,请参阅 Kubeflow/training 操作员的自述文件^143 (opens new window)。
验证 Kubeflow 部署中是否包含 PaddleJob 支持
检查是否安装了 Paddle 自定义资源:
kubectl get crd
输出应包括如下所示的 paddlejobs.kubeflow.org:
NAME CREATED AT
...
paddlejobs.kubeflow.org 2022-10-21T05:37:53Z
...
检查训练操作员是否通过以下方式运行:
kubectl get pods -n kubeflow
输出应包括 job-name-worker-<rank>,如下所示:
NAME READY STATUS RESTARTS AGE
training-operator-worker-0 1/1 Running 0 4m37s
training-operator-worker-1 1/1 Running 0 4m37s
# 3.4.9.2.2.创建飞桨训练工作
您可以通过定义 PaddleJob 配置文件来创建训练作业。请参阅分布式示例的清单。您可以根据需要更改配置文件。
部署 PaddleJob 资源以开始训练:
kubectl create -f https://raw.githubusercontent.com/kubeflow/training-operator/master/examples/paddlepaddle/simple-cpu.yaml (opens new window)
现在,您应该能够看到创建的 pod 与指定数量的副本相匹配。
kubectl get pods -l job-name=paddle-simple-cpu -n kubeflow
在 cpu 集群上训练需要几分钟。可以检查日志以查看其训练进度。
PODNAME=$(kubectl get pods -l job-name=paddle-simple-cpu,replica-type=worker,replica-index=0 -o name -n kubeflow)
kubectl logs -f ${PODNAME} -n kubeflow
# 3.4.9.2.3.监视 PaddleJob
kubectl get -o yaml paddlejobs paddle-simple-cpu -n kubeflow
请参阅状态部分以监视作业状态。这里是作业成功完成时的输出示例。
apiVersion: kubeflow.org/v1
kind: PaddleJob
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"kubeflow.org/v1","kind":"PaddleJob","metadata":{"annotations":{},"name":"paddle-simple-cpu","namespace":"kubeflow"},"spec":{"paddleReplicaSpecs":{"Worker":{"replicas":2,"restartPolicy":"OnFailure","template":{"spec":{"containers":[{"args":["-m","paddle.distributed.launch","run_check"],"command":["python"],"image":"registry.baidubce.com/paddlepaddle/paddle:2.4.0rc0-cpu","imagePullPolicy":"Always","name":"paddle","ports":[{"containerPort":37777,"name":"master"}]}]}}}}}}
creationTimestamp: "2022-10-24T03:47:45Z"
generation: 3
name: paddle-simple-cpu
namespace: kubeflow
resourceVersion: "266235056"
selfLink: /apis/kubeflow.org/v1/namespaces/kubeflow/paddlejobs/paddle-simple-cpu
uid: 7ef4f92f-0ed4-4a35-b10a-562b79538cc6
spec:
paddleReplicaSpecs:
Worker:
replicas: 2
restartPolicy: OnFailure
template:
spec:
containers:
- args:
- -m
- paddle.distributed.launch
- run_check
command:
- python
image: registry.baidubce.com/paddlepaddle/paddle:2.4.0rc0-cpu
imagePullPolicy: Always
name: paddle
ports:
- containerPort: 37777
name: master
protocol: TCP
status:
completionTime: "2022-10-24T04:04:43Z"
conditions:
- lastTransitionTime: "2022-10-24T03:47:45Z"
lastUpdateTime: "2022-10-24T03:47:45Z"
message: PaddleJob paddle-simple-cpu is created.
reason: PaddleJobCreated
status: "True"
type: Created
- lastTransitionTime: "2022-10-24T04:04:28Z"
lastUpdateTime: "2022-10-24T04:04:28Z"
message: PaddleJob kubeflow/paddle-simple-cpu is running.
reason: JobRunning
status: "False"
type: Running
- lastTransitionTime: "2022-10-24T04:04:43Z"
lastUpdateTime: "2022-10-24T04:04:43Z"
message: PaddleJob kubeflow/paddle-simple-cpu successfully completed.
reason: JobSucceeded
status: "True"
type: Succeeded
replicaStatuses:
Worker:
labelSelector:
matchLabels:
group-name: kubeflow.org
job-name: paddle-simple-cpu
training.kubeflow.org/job-name: paddle-simple-cpu
training.kubeflow.org/operator-name: paddlejob-controller
training.kubeflow.org/replica-type: Worker
succeeded: 2
startTime: "2022-10-24T03:47:45Z"
# 3.4.9.3.PyTorch Training (PyTorchJob)
本页描述了 PyTorchJob 用于使用 PyTorch 训练机器学习模型。
PyTorchJob 是一个 Kubernetes 自定义资源,用于在 Kubernete 上运行 PyTorch 训练作业。PyTorchJob 的 Kubeflow 实现是在training-operator (opens new window)。
# 3.4.9.3.1.安装 PyTorch 操作员
如果您还没有这样做,请按照《入门指南》部署 Kubeflow。
默认情况下,PyTorch 操作员将被部署为训练操作员的控制器。
如果您想安装没有 Kubeflow 的独立版本的训练操作员,请参阅 Kubeflow/training 操作员的自述文件^144 (opens new window)。
3.4.9.3.1.1.验证 Kubeflow 部署中是否包含 PyTorchJob 支持
检查是否已安装 PyTorch 自定义资源:
kubectl get crd
输出应包括 pytorchjobs.kubeflow.org,如下所示:
NAME CREATED AT
...
pytorchjobs.kubeflow.org 2021-09-06T18:33:58Z
...
检查训练操作员是否通过以下方式运行:
kubectl get pods -n kubeflow
输出应包括训练操作员 xxx,如下所示:
NAME READY STATUS RESTARTS AGE
training-operator-d466b46bc-xbqvs 1/1 Running 0 4m37s
# 3.4.9.3.2.创建 PyTorch 训练工作
您可以通过定义 PyTorchJob 配置文件来创建训练作业。请参阅分布式 MNIST 示例的清单。您可以根据需要更改配置文件。
部署 PyTorchJob 资源以开始训练:
kubectl create -f https://raw.githubusercontent.com/kubeflow/training-operator/master/examples/pytorch/simple.yaml (opens new window)
现在,您应该能够看到创建的 pod 与指定数量的副本相匹配。
kubectl get pods -l job-name=pytorch-simple -n kubeflow
在 cpu 集群上训练需要 5-10 分钟。可以检查日志以查看其训练进度。
PODNAME=$(kubectl get pods -l job-name=pytorch-simple,replica-type=master,replica-index=0 -o name -n kubeflow)
kubectl logs -f ${PODNAME} -n kubeflow
# 3.4.9.3.3.监视 PyTorchJob
kubectl get -o yaml pytorchjobs pytorch-simple -n kubeflow
请参阅状态部分以监视作业状态。这里是作业成功完成时的输出示例。
apiVersion: kubeflow.org/v1
kind: PyTorchJob
metadata:
clusterName: ""
creationTimestamp: 2018-12-16T21:39:09Z
generation: 1
name: pytorch-tcp-dist-mnist
namespace: default
resourceVersion: "15532"
selfLink: /apis/kubeflow.org/v1/namespaces/default/pytorchjobs/pytorch-tcp-dist-mnist
uid: 059391e8-017b-11e9-bf13-06afd8f55a5c
spec:
cleanPodPolicy: None
pytorchReplicaSpecs:
Master:
replicas: 1
restartPolicy: OnFailure
template:
metadata:
creationTimestamp: null
spec:
containers:
- image: gcr.io/kubeflow-ci/pytorch-dist-mnist_test:1.0
name: pytorch
ports:
- containerPort: 23456
name: pytorchjob-port
resources: {}
Worker:
replicas: 3
restartPolicy: OnFailure
template:
metadata:
creationTimestamp: null
spec:
containers:
- image: gcr.io/kubeflow-ci/pytorch-dist-mnist_test:1.0
name: pytorch
ports:
- containerPort: 23456
name: pytorchjob-port
resources: {}
status:
completionTime: 2018-12-16T21:43:27Z
conditions:
- lastTransitionTime: 2018-12-16T21:39:09Z
lastUpdateTime: 2018-12-16T21:39:09Z
message: PyTorchJob pytorch-tcp-dist-mnist is created.
reason: PyTorchJobCreated
status: "True"
type: Created
- lastTransitionTime: 2018-12-16T21:39:09Z
lastUpdateTime: 2018-12-16T21:40:45Z
message: PyTorchJob pytorch-tcp-dist-mnist is running.
reason: PyTorchJobRunning
status: "False"
type: Running
- lastTransitionTime: 2018-12-16T21:39:09Z
lastUpdateTime: 2018-12-16T21:43:27Z
message: PyTorchJob pytorch-tcp-dist-mnist is successfully completed.
reason: PyTorchJobSucceeded
status: "True"
type: Succeeded
replicaStatuses:
Master: {}
Worker: {}
startTime: 2018-12-16T21:40:45Z
# 3.4.9.4.MXNet Training (MXJob)
本指南将指导您使用 Apache MXNet(孵化)^145 (opens new window)和 Kubeflow。
MXNet Operator 提供了一个 Kubernetes 自定义资源 MXJob,可以轻松地在 Kubernete 上运行分布式或非分布式 Apache MXNet 作业(训练和调优)和其他扩展框架,如 BytePS^146 (opens new window)作业。使用自定义资源定义(CRD),用户可以像内置的 K8S 资源一样创建和管理 Apache MXNet 作业。
MXJob 的 Kubeflow 实现是在training-operator (opens new window)^147 (opens new window)。
# 安装 MXNet 操作员
如果您还没有这样做,请按照《入门指南》部署 Kubeflow。
默认情况下,MXNet 操作员将被部署为训练操作员的控制器。
如果您想安装没有 Kubeflow 的独立版本的训练操作员,请参阅 Kubeflow/training 操作员的自述文件。
# 验证您的 Kubeflow 部署中是否包含 MXJob 支持
检查是否安装了 Apache MXNet 自定义资源:
kubectl get crd
输出应包括 mxjobs.kubeflow.org,如下所示:
NAME CREATED AT
...
mxjobs.kubeflow.org 2021-09-06T18:33:57Z
...
检查训练操作员是否通过以下方式运行:
kubectl get pods -n kubeflow
输出应包括 training-operator-xxx,如下所示:
NAME READY STATUS RESTARTS AGE
training-operator-d466b46bc-xbqvs 1/1 Running 0 4m37s
# 创建 Apache MXNet 训练作业
您可以通过使用 MXTrain 模式定义 MXJob,然后使用创建来创建训练作业。
kubectl create -f https://raw.githubusercontent.com/kubeflow/training-operator/master/examples/mxnet/train/mx_job_dist_gpu_v1.yaml (opens new window)
每个 mxReplicaSpec 定义一组 Apache MXNet 进程。mxReplicaType 定义了一组进程的语义。语义如下:
scheduler
- 作业(job)必须有 1 个且只有 1 个调度程序
- pod 必须包含一个名为 mxnet 的容器
- MXJob 的总体状态由 mxnet 容器的退出代码决定
- 0=成功
- 1||2||126||127||128||139=永久错误:
- 1: 一般性错误
- 2: 壳内件的误用
- 126:调用的命令无法执行
- 127:找不到命令
- 128:退出的参数无效
- 139:容器被 SIGSEGV 终止(内存引用无效)
- 130||137||143=意外系统信号的可重试错误:
- 130:Control-C 终止的容器
- 137:容器收到 SIGKILL
- 143:容器收到 SIGTERM
- 138=在训练操作员中为用户指定的可重试错误保留
- 其他=未定义且无保证
工人worker
- 一个工作可以有 0 到 N 个工人
- pod 必须包含一个名为 mxnet 的容器
- 如果工人退出,他们将自动重新启动
服务器server
- 一个作业可以有 0 到 N 个服务器
- 参数服务器退出时会自动重新启动
为每个副本定义一个 K8S PodTemplateSpec 模板。该模板允许您指定应为每个复制副本创建的容器、卷等。
# 创建 TVM 调整作业(AutoTVM)
TVM 是一个端到端的深度学习编译器堆栈,您可以使用 MXJob 轻松运行 AutoTVM。您可以通过定义 MXTune 作业的类型,然后使用
kubectl create -f https://raw.githubusercontent.com/kubeflow/training-operator/master/examples/mxnet/tune/mx_job_tune_gpu_v1.yaml (opens new window)
在使用自动调优示例之前,需要提前完成一些准备工作。为了让 TVM 调整您的网络,您应该创建一个具有 TVM 模块的 docker 映像。然后,您需要一个自动调整脚本来指定要调整的网络并设置自动调整参数。有关详细信息,请参阅教程。最后,您需要一个启动脚本来启动自动调整程序。事实上,MXJob 将所有参数设置为环境变量,启动脚本需要读取这些变量,然后将其传输到自动调整脚本。
# Using GPUs
MXNet 操作员支持 GPU 训练。
请验证您的图像可用于 GPU 的分布式训练。
例如,如果您有以下内容,MXNet Operator 会将 pod 安排到节点以满足 GPU 限制。
command: ["python"]
args: ["/incubator-mxnet/example/image-classification/train_mnist.py","--num-epochs","1","--num-layers","2","--kv-store","dist_device_sync","--gpus","0"]
resources:
limits:
nvidia.com/gpu: 1
# 监视 Apache MXNet 作业
获取工作状态
kubectl get -o yaml mxjobs $JOB
下面是示例作业的示例输出
apiVersion: kubeflow.org/v1
kind: MXJob
metadata:
creationTimestamp: 2021-03-24T15:37:27Z
generation: 1
name: mxnet-job
namespace: default
resourceVersion: "5123435"
selfLink: /apis/kubeflow.org/v1/namespaces/default/mxjobs/mxnet-job
uid: xx11013b-4a28-11e9-s5a1-704d7bb912f91
spec:
runPolicy:
cleanPodPolicy: All
jobMode: MXTrain
mxReplicaSpecs:
Scheduler:
replicas: 1
restartPolicy: Never
template:
metadata:
creationTimestamp: null
spec:
containers:
- image: mxjob/mxnet:gpu
name: mxnet
ports:
- containerPort: 9091
name: mxjob-port
resources: {}
Server:
replicas: 1
restartPolicy: Never
template:
metadata:
creationTimestamp: null
spec:
containers:
- image: mxjob/mxnet:gpu
name: mxnet
ports:
- containerPort: 9091
name: mxjob-port
resources: {}
Worker:
replicas: 1
restartPolicy: Never
template:
metadata:
creationTimestamp: null
spec:
containers:
- args:
- /incubator-mxnet/example/image-classification/train_mnist.py
- --num-epochs
- "10"
- --num-layers
- "2"
- --kv-store
- dist_device_sync
- --gpus
- "0"
command:
- python
image: mxjob/mxnet:gpu
name: mxnet
ports:
- containerPort: 9091
name: mxjob-port
resources:
limits:
nvidia.com/gpu: "1"
status:
completionTime: 2021-03-24T09:25:11Z
conditions:
- lastTransitionTime: 2021-03-24T15:37:27Z
lastUpdateTime: 2021-03-24T15:37:27Z
message: MXJob mxnet-job is created.
reason: MXJobCreated
status: "True"
type: Created
- lastTransitionTime: 2021-03-24T15:37:27Z
lastUpdateTime: 2021-03-24T15:37:29Z
message: MXJob mxnet-job is running.
reason: MXJobRunning
status: "False"
type: Running
- lastTransitionTime: 2021-03-24T15:37:27Z
lastUpdateTime: 2021-03-24T09:25:11Z
message: MXJob mxnet-job is successfully completed.
reason: MXJobSucceeded
status: "True"
type: Succeeded
mxReplicaStatuses:
Scheduler: {}
Server: {}
Worker: {}
startTime: 2021-03-24T15:37:29Z
首先要注意的是 RuntimeId。这是一个随机唯一字符串,用于为 MXJob 创建的所有 K8 资源(例如作业控制器和服务)命名。
与其他 K8S 资源一样,状态提供有关资源状态的信息。
phase-指示作业的阶段,将是
- Creating
- Running
- CleanUp
- Failed
- Done
state-提供作业的总体状态,将是
- Running
- Succeeded
- Failed
对于作业中的每个复制副本类型,都会有一个 ReplicaStatus,它提供每个状态中该类型的复制副本数量。
对于每种副本类型,作业都会创建一组 K8s 作业控制器,名为
${REPLICA-TYPE}-${RUNTIME_ID}-${INDEX}
例如,如果您有 2 台服务器,运行时 id 为“76n0”,则 MXJob 将创建以下两个作业:
server-76no-0
server-76no-1
# 3.4.9.4.XGBoost 训练 (XGBoostJob)
本页介绍 XGBoostJob 用于使用 XGBoost 训练机器学习模型。
XGBoostJob 是一个 Kubernetes 自定义资源,用于在 Kubernete 上运行 XGBoost 训练作业。XGBoostJob 的 Kubeflow 实现正在训练操作员。
# 3.4.9.4.1.安装 XGBoost 操作员
如果您还没有这样做,请按照《入门指南》部署 Kubeflow。
默认情况下,XGBoost 操作员将被部署为训练操作员的控制器。
如果您想安装没有 Kubeflow 的独立版本的训练操作员,请参阅 Kubeflow/training 操作员的自述文件。
# 3.4.9.4.2.验证 Kubeflow 部署中是否包含 XGBoost 支持
检查 XGboost 自定义资源是否已安装
kubectl get crd
输出应包括 xgboostjobs.kubeflow.org
NAME AGE
...
xgboostjobs.kubeflow.org 4d
...
检查训练操作员是否通过以下方式运行:
kubectl get pods -n kubeflow
输出应包括 training-operator-xxx,如下所示:
NAME READY STATUS RESTARTS AGE
training-operator-d466b46bc-xbqvs 1/1 Running 0 4m37s
# 3.4.9.4.3.创建 XGBoost 训练工作
您可以通过定义 XGboostJob 配置文件来创建训练作业。请参阅 IRIS 示例的清单。您可以根据需要更改配置文件。E.g.:将规范中的 CleanPodPolicy 添加到 None 以在作业终止后保留 pod。
cat xgboostjob.yaml
部署 XGBoostJob 资源开始训练:
kubectl create -f xgboostjob.yaml
现在,您应该能够看到创建的 pod 与指定数量的副本相匹配。
kubectl get pods -l job-name=xgboost-dist-iris-test-train
在 cpu 集群上训练需要 5-10 分钟。可以检查日志以查看其训练进度。
PODNAME=$(kubectl get pods -l job-name=xgboost-dist-iris-test-train,replica-type=master,replica-index=0 -o name)
kubectl logs -f ${PODNAME}
# 3.4.9.4.4.监视 XGBoostJob
kubectl get -o yaml xgboostjobs xgboost-dist-iris-test-train
请参阅状态部分以监视作业状态。这里是作业成功完成时的输出示例。
apiVersion: kubeflow.org/v1
kind: XGBoostJob
metadata:
creationTimestamp: "2021-09-06T18:34:06Z"
generation: 1
name: xgboost-dist-iris-test-train
namespace: default
resourceVersion: "5844304"
selfLink: /apis/kubeflow.org/v1/namespaces/default/xgboostjobs/xgboost-dist-iris-test-train
uid: a1ea6675-3cb5-482b-95dd-68b2c99b8adc
spec:
runPolicy:
cleanPodPolicy: None
xgbReplicaSpecs:
Master:
replicas: 1
restartPolicy: Never
template:
spec:
containers:
- args:
- --job_type=Train
- --xgboost_parameter=objective:multi:softprob,num_class:3
- --n_estimators=10
- --learning_rate=0.1
- --model_path=/tmp/xgboost-model
- --model_storage_type=local
image: docker.io/merlintang/xgboost-dist-iris:1.1
imagePullPolicy: Always
name: xgboost
ports:
- containerPort: 9991
name: xgboostjob-port
protocol: TCP
Worker:
replicas: 2
restartPolicy: ExitCode
template:
spec:
containers:
- args:
- --job_type=Train
- --xgboost_parameter="objective:multi:softprob,num_class:3"
- --n_estimators=10
- --learning_rate=0.1
image: docker.io/merlintang/xgboost-dist-iris:1.1
imagePullPolicy: Always
name: xgboost
ports:
- containerPort: 9991
name: xgboostjob-port
protocol: TCP
status:
completionTime: "2021-09-06T18:34:23Z"
conditions:
- lastTransitionTime: "2021-09-06T18:34:06Z"
lastUpdateTime: "2021-09-06T18:34:06Z"
message: xgboostJob xgboost-dist-iris-test-train is created.
reason: XGBoostJobCreated
status: "True"
type: Created
- lastTransitionTime: "2021-09-06T18:34:06Z"
lastUpdateTime: "2021-09-06T18:34:06Z"
message: XGBoostJob xgboost-dist-iris-test-train is running.
reason: XGBoostJobRunning
status: "False"
type: Running
- lastTransitionTime: "2021-09-06T18:34:23Z"
lastUpdateTime: "2021-09-06T18:34:23Z"
message: XGBoostJob xgboost-dist-iris-test-train is successfully completed.
reason: XGBoostJobSucceeded
status: "True"
type: Succeeded
replicaStatuses:
Master:
succeeded: 1
Worker:
succeeded: 2
# 3.4.9.5.MPI Training (MPIJob)
本指南将指导您使用 MPI 进行训练。
MPI Operator 使得在 Kubernetes 上运行 allreduce 风格的分布式训练变得容易。请查看此博客文章^148 (opens new window),了解 MPI Operator 及其行业采用情况。
# 3.4.9.5.1.安装
通过运行以下命令,可以使用默认设置部署操作员:
git clone https://github.com/kubeflow/mpi-operator (opens new window)
cd mpi-operator
kubectl apply -f deploy/v2beta1/mpi-operator.yaml
或者,按照入门指南部署 Kubeflow。
Kubeflow 0.2.0 引入了 MPI 支持的 alpha 版本。您必须使用高于 0.2.0 的 Kubeflow 版本。
您可以通过以下方式检查是否安装了 MPI 作业自定义资源:
kubectl get crd
输出应包括 mpijobs.kubeflow.org,如下所示:
NAME AGE
...
mpijobs.kubeflow.org 4d
...
如果未包含,可以使用 kustomsize^149 (opens new window)按如下方式添加:
git clone https://github.com/kubeflow/mpi-operator (opens new window)
cd mpi-operator
kustomize build manifests/overlays/kubeflow | kubectl apply -f -
注意,自从 Kubernetes v1.14 以来,kustosize 成为 kubectl 中的一个子命令,因此您也可以运行以下命令:
从 Kubernetes v1.21 开始,您可以使用:
kubectl apply -k manifests/overlays/kubeflow
kubectl kustomize base | kubectl apply -f -
# 3.4.9.5.2.创建 MPI 作业
可以通过定义 MPIJob 配置文件来创建 MPI 作业。有关启动多节点 TensorFlow 基准测试训练作业^150 (opens new window)的信息,请参阅 TensorFlow 标准测试示例配置文件。您可以根据需要更改配置文件。
cat examples/v2beta1/tensorflow-benchmarks.yaml
部署 MPIJob 资源以开始训练:
kubectl apply -f examples/v2beta1/tensorflow-benchmarks.yaml
# 3.4.9.5.3.监视 MPI 作业
创建 MPIJob 资源后,现在应该可以看到创建的 pod 与指定数量的 GPU 相匹配。您还可以从状态部分监视作业状态。这里是作业成功完成时的输出示例。
kubectl get -o yaml mpijobs tensorflow-benchmarks
apiVersion: kubeflow.org/v2beta1
kind: MPIJob
metadata:
creationTimestamp: "2019-07-09T22:15:51Z"
generation: 1
name: tensorflow-benchmarks
namespace: default
resourceVersion: "5645868"
selfLink: /apis/kubeflow.org/v1alpha2/namespaces/default/mpijobs/tensorflow-benchmarks
uid: 1c5b470f-a297-11e9-964d-88d7f67c6e6d
spec:
runPolicy:
cleanPodPolicy: Running
mpiReplicaSpecs:
Launcher:
replicas: 1
template:
spec:
containers:
- command:
- mpirun
- --allow-run-as-root
- -np
- "2"
- -bind-to
- none
- -map-by
- slot
- -x
- NCCL_DEBUG=INFO
- -x
- LD_LIBRARY_PATH
- -x
- PATH
- -mca
- pml
- ob1
- -mca
- btl
- ^openib
- python
- scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py
- --model=resnet101
- --batch_size=64
- --variable_update=horovod
image: mpioperator/tensorflow-benchmarks:latest
name: tensorflow-benchmarks
Worker:
replicas: 1
template:
spec:
containers:
- image: mpioperator/tensorflow-benchmarks:latest
name: tensorflow-benchmarks
resources:
limits:
nvidia.com/gpu: 2
slotsPerWorker: 2
status:
completionTime: "2019-07-09T22:17:06Z"
conditions:
- lastTransitionTime: "2019-07-09T22:15:51Z"
lastUpdateTime: "2019-07-09T22:15:51Z"
message: MPIJob default/tensorflow-benchmarks is created.
reason: MPIJobCreated
status: "True"
type: Created
- lastTransitionTime: "2019-07-09T22:15:54Z"
lastUpdateTime: "2019-07-09T22:15:54Z"
message: MPIJob default/tensorflow-benchmarks is running.
reason: MPIJobRunning
status: "False"
type: Running
- lastTransitionTime: "2019-07-09T22:17:06Z"
lastUpdateTime: "2019-07-09T22:17:06Z"
message: MPIJob default/tensorflow-benchmarks successfully completed.
reason: MPIJobSucceeded
status: "True"
type: Succeeded
replicaStatuses:
Launcher:
succeeded: 1
Worker: {}
startTime: "2019-07-09T22:15:51Z"
训练应该在 GPU 集群上运行 100 步,需要几分钟。您可以查看日志以查看训练进度。当作业开始时,从启动器 pod 访问日志:
PODNAME=$(kubectl get pods -l mpi_job_name=tensorflow-benchmarks,mpi_role_type=launcher -o name)
kubectl logs -f ${PODNAME}
TensorFlow: 1.14
Model: resnet101
Dataset: imagenet (synthetic)
Mode: training
SingleSess: False
Batch size: 128 global
64 per device
Num batches: 100
Num epochs: 0.01
Devices: ['horovod/gpu:0', 'horovod/gpu:1']
NUMA bind: False
Data format: NCHW
Optimizer: sgd
Variables: horovod
...
40 images/sec: 154.4 +/- 0.7 (jitter = 4.0) 8.280
40 images/sec: 154.4 +/- 0.7 (jitter = 4.1) 8.482
50 images/sec: 154.8 +/- 0.6 (jitter = 4.0) 8.397
50 images/sec: 154.8 +/- 0.6 (jitter = 4.2) 8.450
60 images/sec: 154.5 +/- 0.5 (jitter = 4.1) 8.321
60 images/sec: 154.5 +/- 0.5 (jitter = 4.4) 8.349
70 images/sec: 154.5 +/- 0.5 (jitter = 4.0) 8.433
70 images/sec: 154.5 +/- 0.5 (jitter = 4.4) 8.430
80 images/sec: 154.8 +/- 0.4 (jitter = 3.6) 8.199
80 images/sec: 154.8 +/- 0.4 (jitter = 3.8) 8.404
90 images/sec: 154.6 +/- 0.4 (jitter = 3.7) 8.418
90 images/sec: 154.6 +/- 0.4 (jitter = 3.6) 8.459
100 images/sec: 154.2 +/- 0.4 (jitter = 4.0) 8.372
100 images/sec: 154.2 +/- 0.4 (jitter = 4.0) 8.542
----------------------------------------------------------------
total images/sec: 308.27
有关使用英特尔 MPI 的示例,请参阅:
cat examples/pi/pi-intel.yaml
# 3.4.9.5.4.暴露的指标
| Metric name | Metric type | Description | Labels |
|---|---|---|---|
| mpi_operator_jobs_created_total | Counter | Counts number of MPI jobs created | |
| mpi_operator_jobs_successful_total | Counter | Counts number of MPI jobs successful | |
| mpi_operator_jobs_failed_total | Counter | Counts number of MPI jobs failed | |
| mpi_operator_job_info | Gauge | Information about MPIJob | launcher=<launcher-pod-name> namespace=<job-namespace> |
# 3.4.9.5.5.加入指标
使用 kube 状态度量,可以通过标签连接度量。例如,kube_pod_info * on(pod,namespace) group_left label_replace(mpi_operator_job_infos, "pod", "$0", "launcher", ".*")
# 3.4.9.5.6.Docker 图像
我们为每个版本在 Dockerhub 上推送 mpioperator^151 (opens new window)的 Docker 图像。您可以使用以下 Dockerfile 自行构建映像:
- mpi-operator
或者,您可以使用 make 构建图像:
make RELEASE_VERSION**=dev IMAGE_NAME=**registry.example.com/mpi-operator images
这将生成带有标记注册表的图像 example.com/mpioperator:dev。
# 3.4.9.6.作业调度
本指南介绍了如何在 Kubeflow 中使用火山调度器(volcano scheduler^152 (opens new window))来支持集群调度,以允许作业同时运行多个 pod。
# 3.4.9.6.1.使用组调度运行作业
要使用集群调度,您必须首先在集群中安装火山调度程序作为 Kubernetes 的辅助调度程序,并配置操作员以启用集群调度。
- 按照 Volcano^153 (opens new window)中的说明安装 volcano。
- 以 TFJob 为例,通过将 true 设置为--enable 组调度标志,在培训操作员中启用组调度。
注意:Kubeflow 中的 Volcano 调度程序和操作员通过使用 PodGroup 实现集群调度。操作员将自动创建作业的 PodGroup。
例如,使用火山调度程序将作业作为一个组进行调度的 yaml 与非组调度程序相同。
apiVersion: "kubeflow.org/v1beta1"
kind: "TFJob"
metadata:
name: "tfjob-gang-scheduling"
spec:
tfReplicaSpecs:
Worker:
replicas: 1
template:
spec:
containers:
- args:
- python
- tf_cnn_benchmarks.py
- --batch_size=32
- --model=resnet50
- --variable_update=parameter_server
- --flush_stdout=true
- --num_gpus=1
- --local_parameter_device=cpu
- --device=gpu
- --data_format=NHWC
image: gcr.io/kubeflow/tf-benchmarks-gpu:v20171202-bdab599-dirty-284af3
name: tensorflow
resources:
limits:
nvidia.com/gpu: 1
workingDir: /opt/tf-benchmarks/scripts/tf_cnn_benchmarks
restartPolicy: OnFailure
PS:
replicas: 1
template:
spec:
containers:
- args:
- python
- tf_cnn_benchmarks.py
- --batch_size=32
- --model=resnet50
- --variable_update=parameter_server
- --flush_stdout=true
- --num_gpus=1
- --local_parameter_device=cpu
- --device=cpu
- --data_format=NHWC
image: gcr.io/kubeflow/tf-benchmarks-cpu:v20171202-bdab599-dirty-284af3
name: tensorflow
resources:
limits:
cpu: "1"
workingDir: /opt/tf-benchmarks/scripts/tf_cnn_benchmarks
restartPolicy: OnFailure
# 3.4.9.6.2.关于火山调度程序和帮派调度(About volcano scheduler and gang-scheduling)
通过使用火山调度程序应用组调度,只有当作业的所有 pod 都有足够的资源时,作业才能运行。否则,所有 pod 都将处于挂起状态,等待足够的资源。例如,如果创建了一个需要 N 个 pod 的作业,并且只有足够的资源来调度 N-2 个 pod,那么该作业的 N 个 pod 将保持挂起状态。
注意:在高工作负载时,如果作业的一个 pod 在作业仍在运行时死亡,则可能会给其他 pod 一个占用资源并导致死锁的机会。
# 3.4.9.6.3.故障排除
如果您在火山调度程序中不断遇到与 RBAC 相关的问题。
您可以尝试将以下规则添加到火山调度程序使用的调度程序集群角色中。
- apiGroups:
- '*'
resources:
- '*'
verbs:
- '*'
# 3.4.10.多租户(Multi-Tenancy)
# 3.4.10.1.多用户隔离简介
为什么 Kubeflow 管理员需要多用户隔离?
在 Kubeflow 集群中,用户通常需要被隔离到一个组中,其中一个组包括一个或多个用户。此外,用户可能需要属于多个组。Kubeflow 的多用户隔离简化了用户操作,因为每个用户只查看和编辑 Kubeflow 组件和配置中定义的模型工件。用户的视图不会被不在其配置中的组件或模型工件所干扰。这种隔离还提供了高效的基础设施和操作,即单个集群支持多个隔离的用户,不需要管理员操作不同的集群来隔离用户。
# 3.4.10.1.1.关键概念
管理员Administrator:管理员是创建和维护 Kubeflow 集群的人。此人为其他用户配置权限(即查看、编辑)。
用户User:用户是指可以访问集群中某组资源的人。管理员需要向用户授予访问权限。
配置文件Profile:配置文件是用户的唯一配置,它决定用户的访问权限,并由管理员定义。
隔离Isolation:隔离使用 Kubernetes 命名空间。命名空间隔离用户或一组用户,即 Bob 和 Sara 共享的 Bob 命名空间或 ML Eng 命名空间。
身份验证Authentication:身份验证由 Istio 和 OIDC 的集成提供,并由 mTLS 进行保护。更多详情请点击此处
授权Authorization:通过与 Kubernetes RBAC 的集成提供授权。
Kubeflow 多用户隔离由 Kubeflow 管理员配置。管理员为每个用户配置 Kubeflow 用户配置文件。创建并应用配置后,用户只能访问管理员为其配置的 Kubeflow 组件。该配置限制未经授权的 UI 用户查看或意外删除模型工件。
通过多用户隔离,用户被认证和授权,然后被提供一个基于时间的令牌,即 json web 令牌(JWT)。访问令牌作为用户请求中的 web 标头携带,并授权用户访问其配置文件中配置的资源。Profile 配置了几个项,包括 User 的命名空间、RBAC RoleBinding、Istio ServiceRole 和 ServiceRoleBindings 以及资源配额和自定义插件。有关配置文件定义和相关 CRD 的更多信息,请参阅此处
# 3.4.10.1.2.当前集成
这些 Kubeflow 组件可以支持多用户隔离:中央仪表板、笔记本、管道、AutoML(Katib)、KFServing。此外,笔记本创建的资源(例如,培训作业和部署)也继承相同的访问权限。
重要提示:多用户隔离有几个可配置的依赖项,尤其是与 Kubeflow 如何与底层 Kubernetes 集群的身份管理系统配置相关的依赖项。此外,Kubeflow 多用户隔离并不能提供硬安全保证,防止恶意侵入其他用户的档案。
在配置多用户隔离以及安全和身份管理要求时,建议您咨询分发提供商。这个 KubeCon 演示提供了对体系结构和实现的详细回顾。对于内部部署,Kubeflow 使用 Dex 作为联合 OpenID 连接提供程序,并可以与 LDAP 或 Active Directory 集成以提供身份验证和身份服务。这可以是一种高级配置,建议您咨询发行提供商或为本地 Kubeflow 提供高级技术支持的团队。
# 3.4.10.2.多用户隔离设计
支持多用户隔离的深度设计
# 3.4.10.2.1.设计概述
Kubeflow 多租户目前是围绕用户名称空间构建的。具体来说,Kubeflow 定义了用户特定的命名空间,并使用 Kubernetes 基于角色的访问控制(RBAC)策略来管理用户访问。
此功能允许用户共享对其工作区的访问。工作区所有者可以通过 Kubeflow UI 与其他用户共享/撤销工作区访问。被邀请后,用户有权编辑工作区并操作 Kubeflow 自定义资源。
Kubeflow 多租户是自助式的——新用户可以通过 UI 自行注册创建和拥有自己的工作空间。
Kubeflow 使用 Istio 控制集群内流量。默认情况下,除非 Istio RBAC 允许,否则拒绝对用户工作区的请求。绑定用户请求使用身份提供程序(例如,Google Cloud 上的 identity Aware Proxy(IAP)或本地部署的 Dex)进行标识,然后通过 Istio RBAC 规则进行验证。
在内部,Kubeflow 使用 Profile 自定义资源来控制所有涉及的策略、角色和绑定,并保证一致性。Kubeflow 还提供了一个插件接口来管理 Kubernetes 之外的外部资源/策略,例如与 AmazonWebServicesAPI 接口以进行身份管理。
下图说明了一个具有两个用户访问路径的 Kubeflow 多租户集群:通过 Kubeflow 中央仪表板和 kubectl 命令行界面(CLI)。
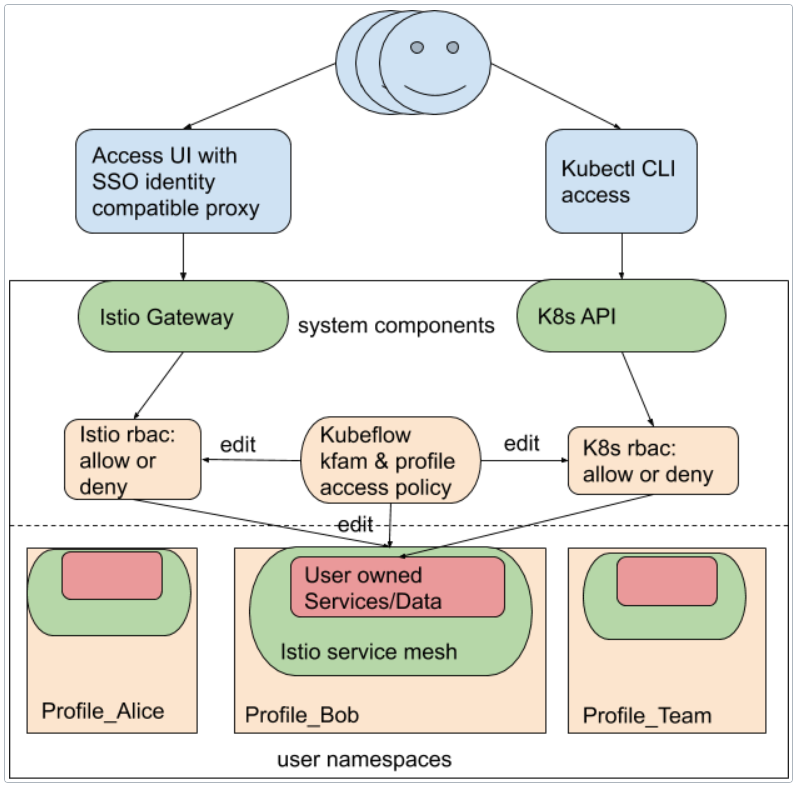
# 3.4.10.2.2.功能要求
Kubeflow 使用 Istio 对集群内流量应用访问控制。
Kubeflow 配置文件控制器需要群集管理员权限。
KubeflowUI 需要在身份感知代理后面提供。身份感知代理和 Kubernetes 主机应该共享相同的身份管理。
谷歌云上的 Kubeflow 安装使用 GKE 和 IAP。
Kubeflow 的本地安装使用了 Dex,这是一个灵活的 OpenID Connect(OIDC)提供程序。
# 3.4.10.2.3.支持的平台
如果您使用 IAP 在 GCP 上部署 Kubeflow,则默认情况下会启用 Kubeflow 多租户。
# 3.4.10.3.多用户隔离入门
如何使用配置文件的多用户隔离
# 3.4.10.3.1.使用情况概述
安装并配置 Kubeflow 后,默认情况下,您将访问主配置文件。概要文件拥有一个同名的 Kubernetes 命名空间以及一个 Kubernete 资源集合。用户可以查看和修改对其主要配置文件的访问权限。您可以与系统中的其他用户共享对配置文件的访问权限。当与其他用户共享对配置文件的访问权限时,您可以选择是只提供读取访问权限还是读取/修改访问权限。在使用 Kubeflow 中央仪表板时,出于所有实际目的,活动名称空间直接与活动概要文件绑定。
# 3.4.10.3.2.用法示例
您可以从 Kubeflow 中央仪表板的顶部栏中选择您的活动配置文件。请注意,您只能查看具有查看或修改权限的配置文件。
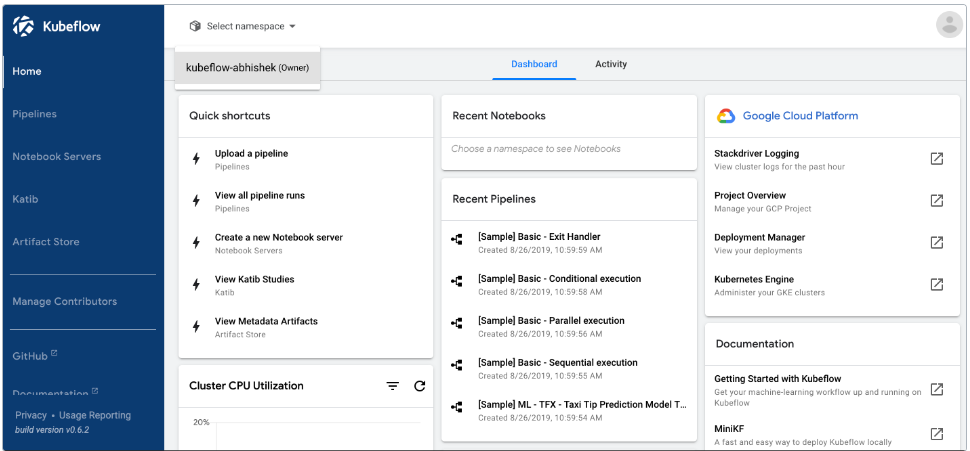
本指南说明了使用 Jupyter 笔记本服务的用户隔离功能,这是系统中第一个与多用户隔离功能完全集成的服务。
选择活动配置文件后,笔记本服务器 UI 仅显示当前所选配置文件中的活动笔记本服务器。所有其他笔记本服务器都对您隐藏。如果切换活动配置文件,视图将相应地切换活动笔记本的列表。您可以连接到任何列出的笔记本服务器,并查看和修改服务器中可用的现有 Jupyter 笔记本。
例如,下图显示了用户主配置文件中可用的笔记本服务器列表:
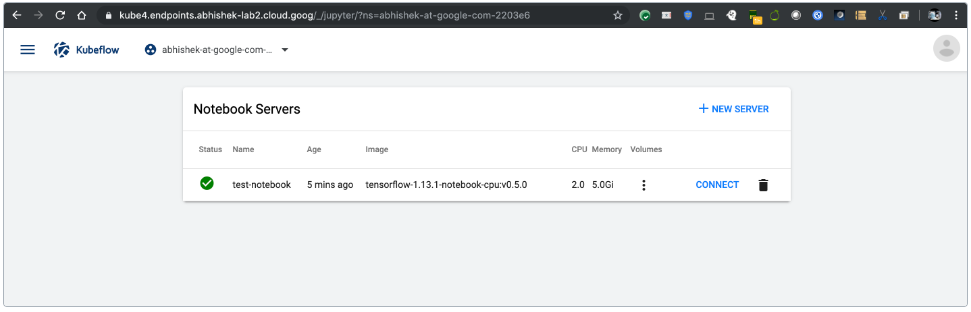
当未经授权的用户访问此配置文件中的笔记本时,他们会看到错误:
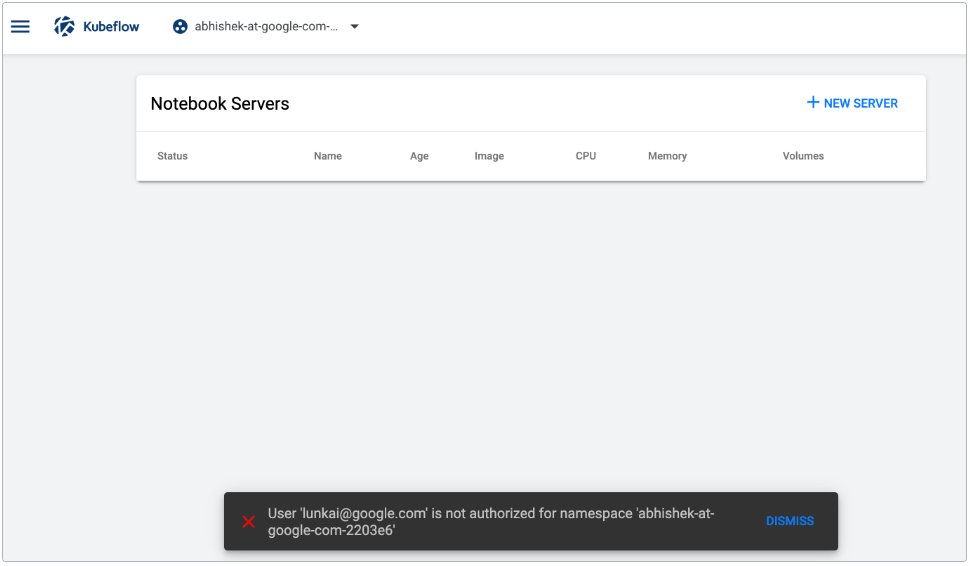
当您从笔记本服务器 UI 创建 Jupyter 笔记本服务器时,将在活动配置文件中创建笔记本 pod。如果您没有对活动配置文件的修改权限,则只能浏览当前活动的笔记本服务器并访问现有笔记本,但不能在该配置文件中创建新的笔记本服务器。您可以在主配置文件中创建笔记本服务器,您可以查看和修改这些服务器。
# 3.4.10.3.3.注册新用户
管理员可以为 Kubeflow 集群中的任何用户手动创建配置文件。这里的管理员是在 Kubernetes 集群中具有集群管理员角色绑定的人员。此人有权在集群中创建和修改 Kubernetes 资源。例如,部署 Kubeflow 的人员将在集群中拥有管理权限。
我们推荐这种方法,因为它鼓励采用 GitOps 流程来处理概要文件的创建。
Kubeflow v1.6.0 可选地为首次登录时经过身份验证的用户提供自动配置文件创建工作流。
前提条件:授予用户最少的 Kubernetes 集群访问权限
您必须向每个用户授予允许他们连接到 Kubernetes 集群的最小权限范围。
例如,对于 Google Cloud 用户,您应该授予以下云身份和访问管理(IAM)角色。在以下命令中,将[PROJECT]替换为您的 Google Cloud 项目,并将[EMAIL]替换为用户的电子邮件地址:
- 要访问 Kubernetes 集群,用户需要 Kubernetes Engine Cluster Viewer^154 (opens new window)角色:
gcloud projects add-iam-policy-binding [PROJECT] --member=user:[EMAIL] --role=roles/container.clusterViewer
- 要通过 IAP 访问 Kubeflow UI,用户需要 IAP 安全的 Web App^155 (opens new window)用户角色:
gcloud projects add-iam-policy-binding [PROJECT] --member=user:[EMAIL] --role=roles/iap.httpsResourceAccessor
# 3.4.10.3.4.手动创建配置文件
管理员可以手动为用户创建配置文件,如下所述。
在本地计算机上创建包含以下内容的 profile.yaml 文件:
apiVersion: kubeflow.org/v1beta1
kind: Profile
metadata:
name: profileName # replace with the name of profile you want, this will be user's namespace name
spec:
owner:
kind: User
name: userid@email.com # replace with the email of the user
resourceQuotaSpec: # resource quota can be set optionally
hard:
cpu: "2"
memory: 2Gi
requests.nvidia.com/gpu: "1"
persistentvolumeclaims: "1"
requests.storage: "5Gi"
运行以下命令以创建相应的配置文件资源:
kubectl create -f profile.yaml
kubectl apply -f profile.yaml #if you are modifying the profile
上面的命令创建一个名为 profileName 的配置文件。配置文件所有者是userid@email.com并且具有对该配置文件的查看和修改权限。作为概要文件创建的一部分,将创建以下资源:
- 一个 Kubernetes 命名空间,与相应的概要文件共享相同的名称。
- Kubernetes RBAC(基于角色的访问控制^156 (opens new window))角色绑定命名空间的角色绑定:Admin。这使概要文件所有者成为命名空间管理员,从而允许他们使用 kubectl(通过 Kubernetes API)访问命名空间。
- Istio 命名空间范围内的 AuthorizationPolicy:user userid email com clusterrole edit。这允许用户访问属于在其中创建 AuthorizationPolicy 的命名空间的数据
- 命名空间范围内的服务帐户默认编辑器和默认查看器,由用户在命名空间中创建的 pod 使用。
- 将设置命名空间范围内的资源配额限制。
注意:由于概要文件与 Kubernetes 名称空间一一对应,因此在文档中有时可以互换使用概要文件和名称空间。
# 3.4.10.3.5.批量创建用户配置文件
管理员可能希望批量创建多个用户的配置文件。您可以通过在本地计算机上创建一个 profile.yaml,其中包含多个配置文件描述部分,如下所示:
apiVersion: kubeflow.org/v1beta1
kind: Profile
metadata:
name: profileName1 # replace with the name of profile you want
spec:
owner:
kind: User
name: userid1@email.com # replace with the email of the user
---
apiVersion: kubeflow.org/v1beta1
kind: Profile
metadata:
name: profileName2 # replace with the name of profile you want
spec:
owner:
kind: User
name: userid2@email.com # replace with the email of the user
运行以下命令将名称空间应用于 Kubernetes 集群:
kubectl create -f profile.yaml
kubectl apply -f profile.yaml #if you are modifying the profiles
这将创建多个概要文件,每个概要文件对应于 profile.yaml 中各节中列出的各个概要文件。
# 3.4.10.3.6.自动创建配置文件
Kubeflow v1.6.0 提供自动配置文件创建:
- 默认情况下不会激活自动概要文件创建,需要作为部署的一部分明确包含。在部署期间启用自动用户配置文件创建后,将在经过身份验证的用户首次登录时为其创建新的用户配置文件。用户将能够在 Kubeflow 中央仪表板的下拉列表中看到他们的新配置文件。
- 通过将 CD_REGISTRATION_FLOW env 变量设置为 true,可以作为部署的一部分启用自动概要文件创建。修改<manifest-path>/apps/centraldashboard/aupstream/base/params.env 以将注册变量设置为 true
CD_CLUSTER_DOMAIN=cluster.local
CD_USERID_HEADER=kubeflow-userid
CD_USERID_PREFIX=
CD_REGISTRATION_FLOW=true
- 当经过身份验证的用户首次登录系统并访问中央仪表板时,他们会自动触发配置文件创建。
- 一条简短的消息介绍了概要文件:自动创建概要文件

- 用户可以命名其配置文件并单击“完成”:
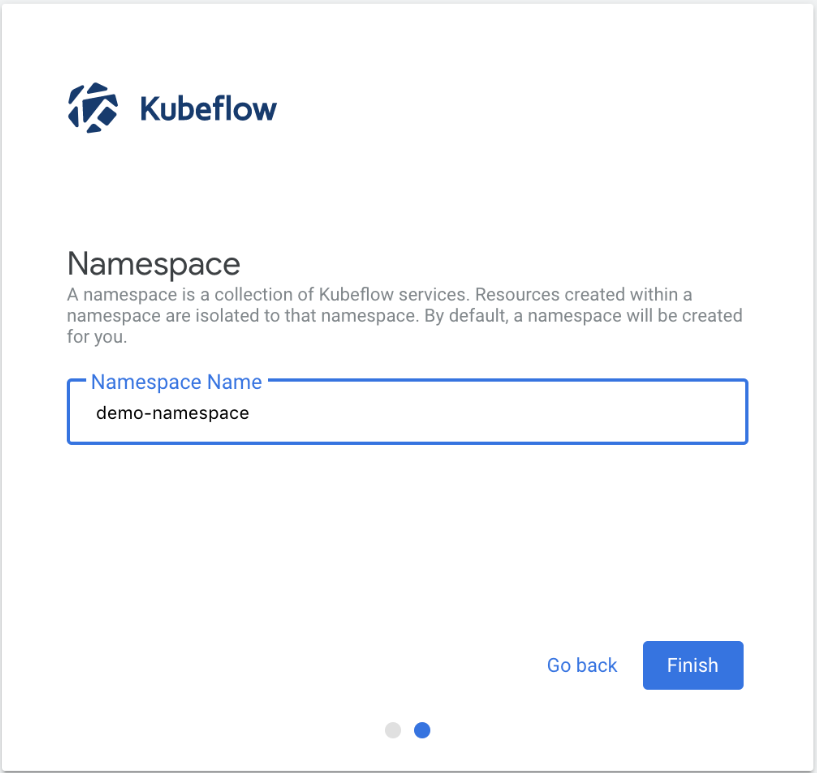
这会将用户重定向到仪表板,用户可以在下拉列表中查看和选择其配置文件。
# 3.4.10.3.7.列出和描述配置文件
管理员可以列出系统中的现有配置文件:
$ kubectl get profiles
并使用以下内容描述特定配置文件:
$ kubectl describe profile profileName
# 3.4.10.3.8.删除现有配置文件
管理员可以使用以下方法删除现有配置文件:
$ kubectl delete profile profileName
这将删除概要文件、相应的命名空间和与概要文件关联的任何 Kubernetes 资源。配置文件的所有者或其他有权访问配置文件的用户将不再有权访问该配置文件,也不会在中央仪表板上的下拉列表中看到该配置文件。
# 3.4.10.3.9.通过 Kubeflow UI 管理贡献者
Kubeflow v1.6.0 允许与系统中的其他用户共享配置文件。配置文件的所有者可以使用仪表板上的“管理参与者”选项卡共享对其配置文件的访问权限。
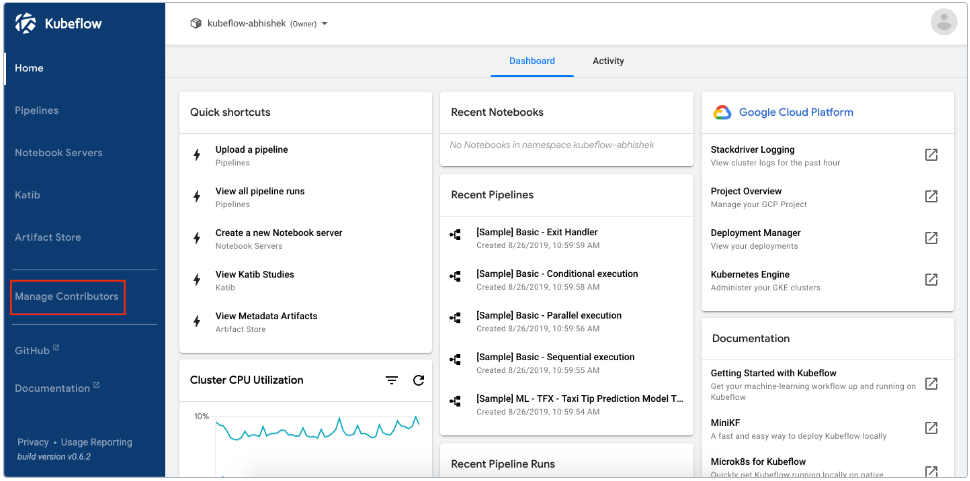
以下是“管理参与者”选项卡视图的示例:
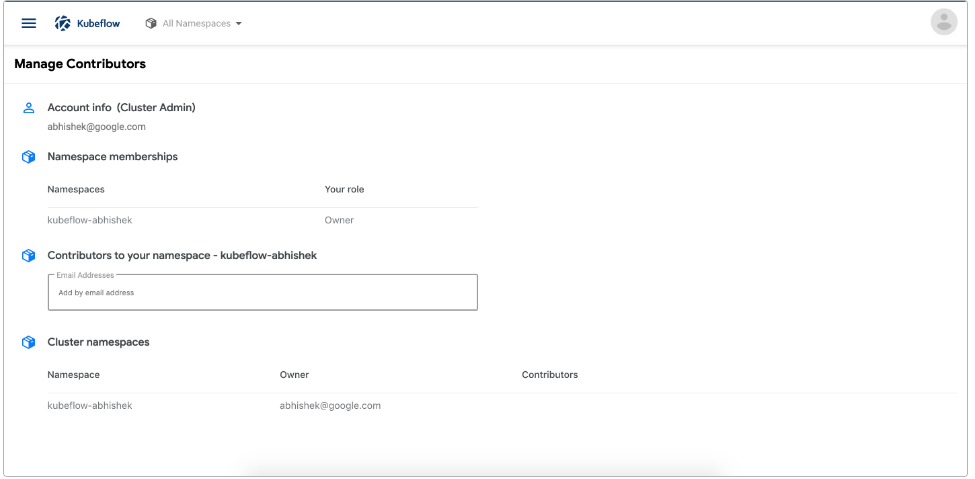
注意,在上面的视图中,与概要文件关联的帐户是集群管理员(ClusterAdmin),因为该帐户用于部署 Kubeflow。该视图列出了用户可访问的配置文件以及与该配置文件关联的角色。
要添加或删除贡献者,请在命名空间字段的“贡献者”中添加/删除电子邮件地址或用户标识符。
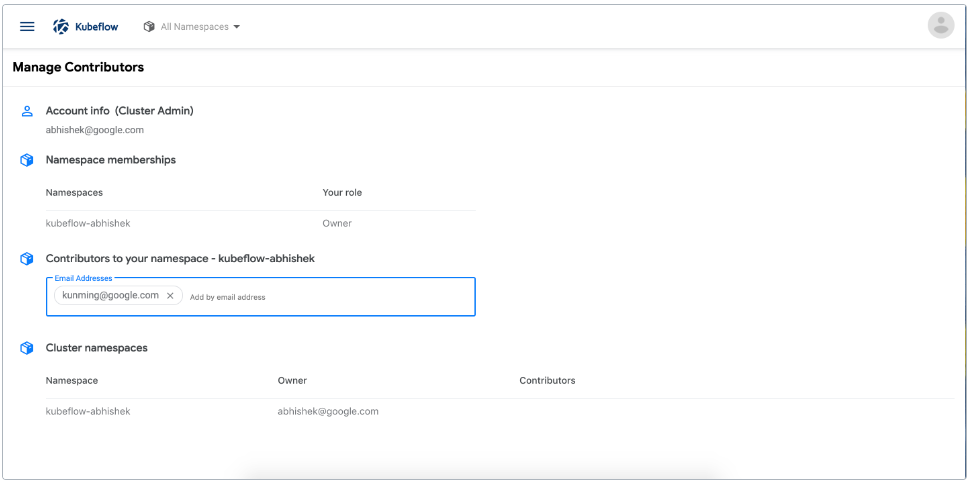
“管理参与者”选项卡显示命名空间所有者添加的参与者。注意,集群管理员可以查看系统中的所有配置文件及其贡献者。
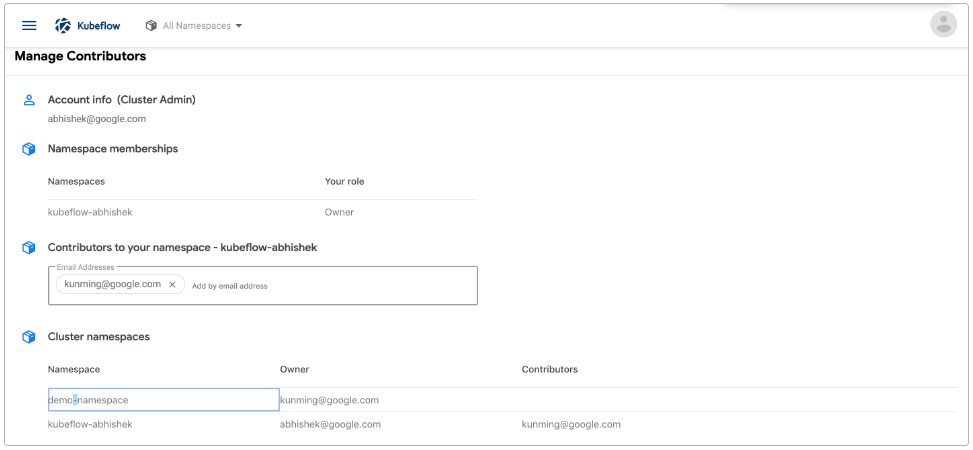
贡献者可以访问命名空间中的所有 Kubernetes 资源,并可以创建笔记本服务器以及访问现有笔记本。
# 3.4.10.3.10.手动管理贡献者
管理员可以手动向现有配置文件添加贡献者,如下所述。
在本地计算机上创建包含以下内容的 rolebinding.yaml 文件:
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
annotations:
role: edit
user: userid@email.com # replace with the email of the user from your Active Directory case sensitive
name: user-userid-email-com-clusterrole-edit
# Ex: if the user email is lalith.vaka@kp.org the name should be user-lalith-vaka-kp-org-clusterrole-edit
# Note: if the user email is Lalith.Vaka@kp.org from your Active Directory, the name should be user-lalith-vaka-kp-org-clusterrole-edit
namespace: profileName # replace with the namespace/profile name that you are adding contributors to
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: kubeflow-edit
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: User
name: userid@email.com # replace with the email of the user from your Active Directory case sensitive
在本地计算机上创建具有以下内容的 authorizationpolicy.yaml 文件:
apiVersion: security.istio.io/v1beta1
kind: AuthorizationPolicy
metadata:
annotations:
role: edit
user: userid@email.com # replace with the email of the user from your Active Directory case sensitive
name: user-userid-email-com-clusterrole-edit
namespace: profileName # replace with the namespace/profile name that you are adding contributors to
spec:
action: ALLOW
rules:
- when:
- key: request.headers[kubeflow-userid] # for GCP, use x-goog-authenticated-user-email instead of kubeflow-userid for authentication purpose
values:
- accounts.google.com:userid@email.com # replace with the email of the user from your Active Directory case sensitive
运行以下命令以创建相应的贡献者资源:
kubectl create -f rolebinding.yaml
kubectl create -f authorizationpolicy.yaml
上面的命令添加了一个贡献者userid@email.com到名为 profileName 的配置文件。出资人userid@email.com具有查看和修改该配置文件的权限。
# 4.外部附加组件
可与 Kubeflow 部署或发行版集成的其他工具。
# 4.1.爱丽拉 Elyra
Elyra 使数据科学家能够直观地创建端到端机器学习(ML)工作流。
Elyra 旨在帮助数据科学家、机器学习工程师和人工智能开发人员解决模型开发生命周期的复杂性。Elyra 与 JupyterLab 集成,提供了一个 Pipeline 可视化编辑器,可以在 Kubeflow 环境中创建低代码/无代码的 Pipeline。
下面是用 Elyra 创建的 Piepline 的示例,您可以识别所有在可视化编辑器中管理的组件/任务和相关属性。
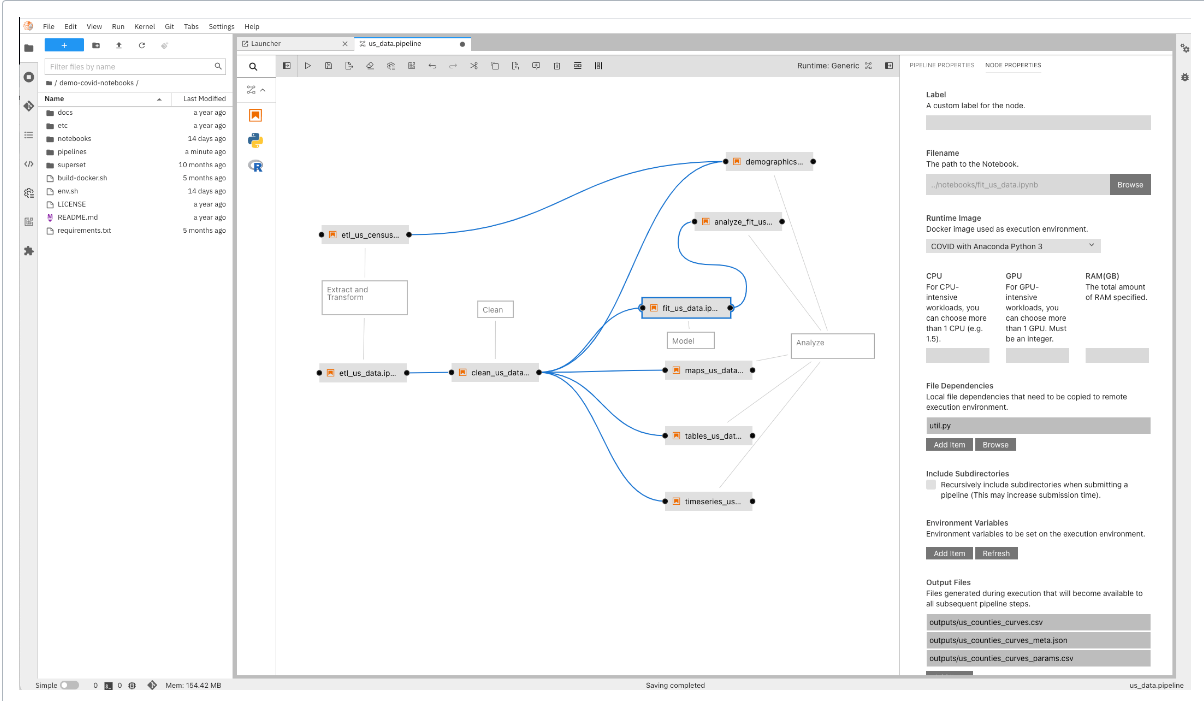
要了解有关 Elyra 的更多信息,请访问 Elyra GitHub 项目^157 (opens new window)。
要在 Kubeflow 环境中启用 Elyra,请访问将 Elyra 用于 Kubeflow 笔记本服务器^158 (opens new window)。
# 4.2.Istio 公司
Kubeflow 中 Istio 组件的文档
# 4.2.1.Istio 简介
大多数现代应用程序都是使用分布式微服务架构构建的。这确保了每个单独的服务都是简单的,并有明确的责任。复杂的系统和平台通常是通过结合许多这样的微服务来构建的。每个微服务都定义了自己的 API,服务使用这些 API 相互交互,以满足最终用户的请求。
术语服务网格用于描述构成此类应用程序的微服务网络以及它们之间的交互。随着服务网格的规模和复杂性的增长,它可能变得更难理解和管理。其需求可以包括发现、负载平衡、故障恢复、度量和监控。服务网格通常还具有更复杂的操作需求,如 A/B 测试、金丝雀部署、速率限制、访问控制和端到端身份验证。
Istio^159 (opens new window)是 Google 对服务网格的一个开创性和高性能的开源实现。有关详细信息,您可以阅读 Istio 的概念概述^160 (opens new window)。
# 4.2.2.为什么 Kubeflow 需要 Istio
Kubeflow 是一组工具、框架和服务,它们一起部署到一个 Kubernetes 集群中,以实现端到端的 ML 工作流。这些组件或服务中的大多数是独立开发的,有助于工作流的不同部分。开发完整的 ML 工作流或 ML 开发环境需要组合多个服务和组件。Kubeflow 提供了底层基础设施,可以将这些不同的组件组合在一起。
Kubeflow 使用 Istio 作为一种统一的方式来保护、连接和监控微服务。明确地:
通过基于身份的强身份验证和授权,确保 Kubeflow 部署中的服务到服务通信安全。
用于支持访问控制和配额的策略层。
部署中流量的自动度量、日志和跟踪,包括集群入口和出口。
# 4.2.3.kubeflow 的 Istio
下图说明了用户请求如何与 Kubeflow 中的服务交互。当用户通过可通过 Kubeflow Central Dashboard 访问的 Notebooks Servers UI 请求创建新的笔记本服务器时,它会遍历整个过程。
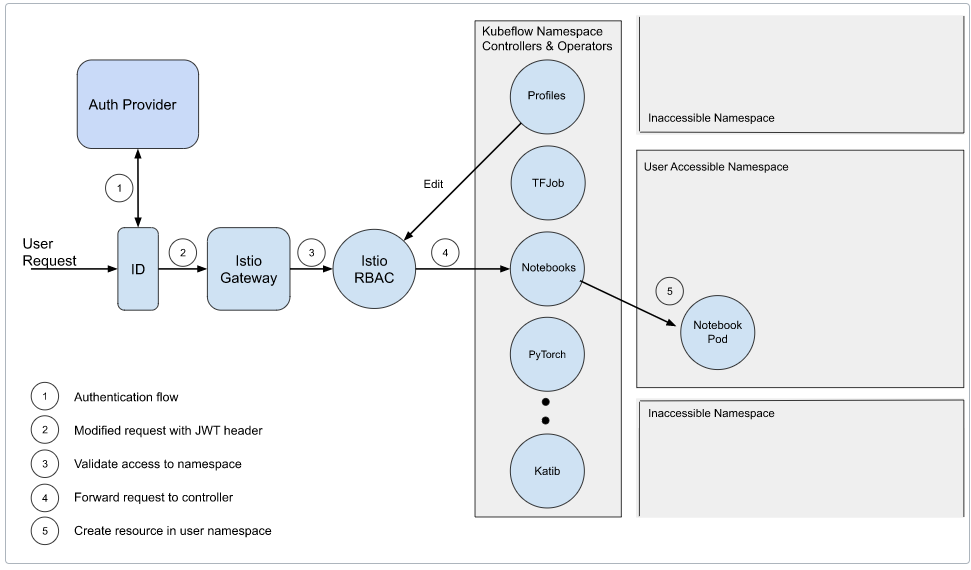
- 用户请求被识别代理拦截,该代理与 SSO 服务提供商(如云服务提供商上的 IAM 或本地 Active Directory/LDAP)进行对话。
- 当用户通过身份验证时,Istio 网关会修改请求,以包含包含用户身份的 JWT Header 令牌。服务网格中的所有请求都携带此令牌。
- Istio RBAC 策略应用于传入请求,以验证对服务和请求的命名空间的访问。如果用户无法访问其中任何一个,则会返回错误响应。
- 如果请求被验证,它将被转发到适当的控制器(在本例中为笔记本控制器)。
- Notebooks Controller 使用 Kubernetes RBAC 验证授权,并在用户请求的命名空间中创建笔记本 pod。
用户使用笔记本在名称空间中创建培训作业或其他资源的进一步操作将经历类似的过程。Profiles Controller 管理概要文件的创建,并创建和应用适当的 Istio 策略。有关详细信息,请参阅多用户隔离。
# 4.2.4.在没有 Istio 的情况下部署 Kubeflow
目前,没有 Istio 无法部署 Kubeflow。Kubeflow 需要 Istio 自定义资源定义(CRD)来表示从网关访问创建的笔记本的新路由。
# 4.3.Kale
Kale 使数据科学家能够协调端到端机器学习(ML)工作流。
Kale 简化了 Kubeflow 的使用,为数据科学家提供了协调端到端 ML 工作流所需的工具。Kale 以 JupyterLab 扩展的形式提供了一个 UI。您可以在 Jupyter 记事本中注释单元格以定义:管道步骤、超参数调整、GPU 使用和度量跟踪。单击按钮创建管道组件和 KFP DSL,解决依赖关系,将数据对象注入到每个步骤中,部署数据科学管道,并提供最佳模型。
# 4.4.KServe
基于 Kubernetes 的高度可扩展和基于标准的模型推理平台
# Kserve
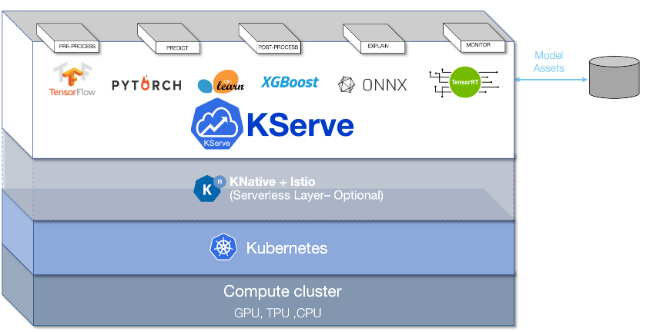
KServe 支持 Kubernetes 上的无服务器推理,并为 TensorFlow、XGBoost、scikit learn、PyTorch 和 ONNX 等通用机器学习(ML)框架提供高性能、高抽象接口,以解决生产模型服务用例。
# KFServing 现在是 KServe
KFServing GitHub 存储库已移交给一个独立的 KServe GitHub 组织,由 Kubeflow Serving 工作组领导管理。
# KServe 文件
大部分 KServe 文档将在新的文档网站上提供,建议参考 KServe 网站上的文档,而不是本网站
您可以使用 KServe 执行以下操作:
- 为任意框架上的 ML 模型提供 Kubernetes 自定义资源定义。
- 封装自动缩放、网络、健康检查和服务器配置的复杂性,为您的 ML 部署带来 GPU 自动缩放、缩放到零和金丝雀部署等尖端服务功能。
- 通过提供开箱即用的预测、预处理、后处理和解释功能,为您的生产 ML 推理服务器提供一个简单、可插入和完整的故事。
- 我们强大的社区贡献有助于 KServe 的发展。我们有一个由彭博社、IBM Cloud、Seldon、Amazon Web Services(AWS)和 NVIDIA 驱动的技术指导委员会。请浏览 KServe GitHub 回购,并提出问题以提供反馈!
# 使用 Kubeflow 安装
KServe 与 Kubeflow1.5 一起工作。Kustosize 安装文件位于清单库中。查看 KServe/KServe 存储库中 Istio/Dex 上运行 KServe 的示例。对于使用 Kubeflow 在主要云提供商上的安装,请遵循他们的安装文档。
Kubeflow 1.5 包括 KServe v0.7,它将核心推理服务 API 从 v1alpha2 提升到 v1beta1 稳定,并将 ModelMesh 组件添加到版本中。此外,关于 AI 公平性、AI 可解释性和对抗性鲁棒性的 LFAI 可信 AI 项目已与 KServe 集成,我们也在 OpenShift 上提供了 KServe。要了解更多信息,请阅读发布博客并遵循发布说明
# 独立 KServe
快速启动安装
KServe Quickstart 环境仅供实验使用。有关生产安装,请参阅《管理员指南》
# 4.5.Fairing
Kubeflow Fairing 文档。
# 4.6.Feature Store
功能存储、管理、验证和服务
# 4.7.Tools for Serving
Kubeflow 中的 ML 模型服务
https://www.kubeflow.org/docs/components/pipelines/v1/sdk/connect-api/ (opens new window)